Wobfuscator: Obfuscating JavaScript Malware via Opportunistic Translation to WebAssembly
Wobfuscator: Obfuscating JavaScript Malware via Opportunistic Translation to WebAssembly
论文来自 2022 IEEE Symposium on Security and Privacy (SP 2022) 的《Wobfuscator: Obfuscating JavaScript Malware via Opportunistic Translation to WebAssembly》。
摘要
为了保护web用户免受恶意JavaScript代码的攻击,已经提出了各种恶意软件检测器,它们可以分析和分类代码为恶意或良性。最先进的检测器专注于JavaScript作为唯一的目标语言。
然而,WebAssembly为攻击者提供了一个新的、迄今为止尚未探索的躲避恶意软件检测器的机会。本文介绍了Wobfuscator,这是第一种通过将计算部分移动到WebAssembly中来逃避静态JavaScript恶意软件检测的技术。该技术的核心是一组代码转换,将JavaScript中精心选择的行为部分转换为WebAssembly。这种方法是机会主义的,因为它使用WebAssembly,在不损害代码正确性的情况下帮助逃避恶意软件检测。使用43499个恶意JavaScript文件和149677个良性JavaScript文件以及六个流行的JavaScript库的数据集评估我们的方法,结果表明我们的方法可以有效地避开最先进的基于学习的静态恶意软件检测器;且混淆后语义不变;而且我们的方法开销很小,使其在现实世界的程序中具有实用性。通过指出当前恶意软件检测器的局限性,我们的工作激励了未来检测网络中多语言恶意软件的努力。
1. Introduction
web的无处不在使客户端web应用程序成为攻击者的一个有吸引力的目标。因此,各种类型的攻击都针对浏览器,例如,由恶意软件驱动的攻击[48]、[23]、[43]、通过基于脚本的浏览器增强市场部署的恶意代码[58]、未经用户同意的基于浏览器的加密挖掘[40]、[52]、[34]、恶意浏览器扩展[21]、[65]和基于浏览器的网络钓鱼[14]。最近的一份报告估计,仅精心策划的网络钓鱼活动每月就会产生170万到200万个恶意有效载荷网址[44]。除了这些明显的恶意活动外,许多网站还采用了用户不想要的技术,例如广泛的浏览器指纹识别[30]或跟踪[25]。
为了保护用户免受在浏览器中执行恶意脚本的侵害,JavaScript恶意软件检测器会在执行这些脚本之前或期间发出警告。一行工作在脚本执行之前对其进行静态分析[24]、[50]、[56]、[28]、[27],例如,通过拦截网络中已有的脚本、作为浏览器的一部分或作为单独的反病毒工具的一部分。另一项工作是动态分析脚本[36],例如通过检测代码或通过浏览器扩展。为了减少基于动态分析的恶意软件检测器带来的运行时开销,静态检测器通常作为第一道防线,例如,通过仅动态分析静态分析认为危险的脚本。
为了在恶意软件检测器存在的情况下有效地攻击用户,攻击者试图通过混淆和规避技术来隐藏脚本的恶意性[53],[55]。攻击者和防御者的进步导致了日益复杂的混淆和规避技术与日益有效的恶意软件检测器之间的军备竞赛。目前,最有效的恶意软件检测技术使用基于学习的分类器来区分恶意脚本和良性脚本[24],[50],[28],[27]。这些方法从给定的JavaScript文件中提取一组特征,例如n元代码令牌(n-grams of code tokens)或基于AST的特征,或者将JavaScript代码输入深度神经网络[63],以确定该文件是否可能是恶意的。
虽然关注JavaScript在历史上是有意义的,但JavaScript不再是客户端web的唯一语言。WebAssembly[31]是另一种在浏览器中广泛使用的语言。WebAssembly于2015年首次宣布,自2017年11月以来,所有主要浏览器都支持WebAssemblys,截至2021年8月,全球94%的浏览器安装都支持它。该语言为用C和C++等语言编写的计算密集型库提供了一个高效的编译目标。除了WebAssembly的许多积极用途外,该语言还为攻击者提供了逃避恶意软件检测器的新机会——据我们所知,这一机会尚未被探索。
本文介绍了第一种通过将计算部分移动到WebAssembly中来逃避JavaScript恶意软件检测的技术。我们描述了Wobfuscator,这是一种代码混淆技术,可以将给定的JavaScript文件转换为新的JavaScript文件和一组WebAssembly模块。通过更改恶意JavaScript代码,我们的工作旨在避开静态恶意软件检测器。其基本原理是,静态检测器可以单独使用,也可以作为脚本动态分析的过滤器。也就是说,躲避静态恶意软件检测器为攻击者带来了巨大的好处。
将JavaScript文件的一部分转换为WebAssembly绝非易事。JavaScript是动态类型的,具有复杂的对象,并提供对浏览器API的直接访问。相比之下,WebAssembly是静态类型的,只有四种低级原始数据类型,并且只能通过从JavaScript导入来间接访问浏览器API。由于这些根本性的差异,一般的JavaScript到WebAssembly的翻译实际上是不可能的,这反映在WebAssemblys从未被吹捧为JavaScript的替代品,而是作为一种补充的方式[31]。
本文的核心技术贡献是一组代码转换,这些转换提取了JavaScript中精心选择的行为部分,以转换为WebAssembly。这种方法是机会主义的,因为它将JavaScript转换为WebAssembly,在不损害代码正确性的情况下,它有助于避开恶意软件检测器。例如,我们提出了一种转换,将函数调用提取到WebAssembly模块中,混淆脚本是否以及何时调用特定函数。其他转换旨在混淆字符串文字、控制流语句和数组初始化。前提条件保护每个转换,以确保保留原始行为,我们认为这是攻击者使用混淆技术的关键属性。
我们的工作涉及现有的JavaScript混淆技术。例如,Fass等人将恶意代码融合为良性代码,同时保留良性代码的AST[26]。为了更全面地了解混淆技术及其流行情况,我们建议读者参考其他工作[66],[55]。所有这些方法都是通过JavaScript语言中的转换来混淆代码的,而Wobfusctor则利用WebAssembly的可用性,通过翻译JavaScript之外的代码来混淆代码。Wang等人的一篇论文分享了通过将一种语言的部分代码翻译成另一种语言来混淆用一种语言编写的代码的一般想法[60]。然而,他们描述了将C代码部分翻译成Prolog,这并没有解决通过部分翻译成WebAssembly来混淆JavaScript的独特挑战。
我们使用43499个恶意JavaScript文件和149677个良性JavaScript文件的数据集以及六个流行的JavaScript库来评估Wobfuscator。我们的结果显示如下。首先,该方法有效地避开了最先进的基于学习的静态恶意软件检测器:应用我们的转换将四个研究的检测器[50]、[24]、[28]、[27]的召回率分别降低到0.18、0.63、0.18和0.00。其次,混淆保留了转换代码的语义:混淆了六个流行的JavaScript库并运行了它们的2017年测试,结果显示测试代码的行为没有明显变化。最后,我们发现我们的工具将所有转换应用于项目平均只需要8.9秒(平均4152行代码),在运行时平均增加31.07%的开销。总体而言,这些结果表明Wobfuscator在现实世界的程序中是实用的。
总之,本文有以下贡献:
- 第一种使用WebAssembly作为混淆恶意JavaScript代码行为的方法的技术。
- 一组代码转换,将精心选择的JavaScript代码位置转换为WebAssembly。
- 综合评估表明,该方法有效地避开了最先进的静态恶意软件检测器,同时保留了原始代码的语义。
我们的实验结果已公开:https://github.com/js2wasm-obfuscator/translator
2. WebAssembly的背景
我们简要介绍了WebAssembly的核心概念和语法。出于篇幅原因,我们建议读者参考原始出版物[31]、官方网站[10]或规范[64]以获取更详细的解释。
WebAssembly是一种低级字节码语言。WebAssembly程序以二进制文件的形式分发,这些二进制文件结构紧凑,可以通过网络发送,解析速度也很快。
每个WebAssembly程序都是一个文件模块,分为几个部分。最重要的是,代码部分包含所有函数及其正文。全局部分包含标量全局变量。内存部分声明了一个线性的、字节可寻址的内存,其中的部分可以用数据部分初始化。
WebAssembly指令在低抽象级别上运行,没有类或复杂对象等。指令和函数是静态类型的,但只有四种基本类型:分别是32位和64位整数值和浮点值。指令在虚拟堆栈机上执行,即它们弹出操作数并将结果推送到隐式计算堆栈上。指令很简单,旨在与硬件指令紧密映射,例如,WebAssembly i32.add指令将被转换为x86 addl。由于没有垃圾收集器,只有原始标量类型,复杂对象(字符串、数组、记录等)被存储在程序组织的线性内存中,该内存本质上是一个非类型化字节的可增长数组。
WebAssembly没有标准库,为了与“外部世界”交互,WebAssemblys模块需要从宿主环境导入函数。在浏览器中,宿主环境是JavaScript,因此任何JavaScript函数都可以从WebAssembly调用。然而,非原始数据需要通过WebAssembly内存进行封送(也可以从JavaScript访问)。JavaScript中的WebAssembly API提供了编译和实例化(即实现WebAssembly模块的导入)WebAssembly和调用导出WebAssembly函数的函数。
3. 威胁模型(THREAT MODEL)
我们的工作是关于作为客户端web应用程序的一部分交付的恶意或不需要的代码。网站可能故意传递此类代码,例如,因为域由攻击者控制,也可能无意中传递,例如,通过第三方脚本或广告。我们假设攻击者控制着服务器端的恶意代码,因此可以自由修改它。特别是,他们可以转换源代码、将一个文件拆分为多个文件或合并多个代码文件。
在防御方面,我们假设一个静态恶意软件检测器在web应用程序在浏览器中执行之前扫描其客户端代码。恶意软件检测器用于拦截和检查代码的机制与我们无关。例如,它可以实现为一个网络代理,在文件到达客户端计算机之前对其进行扫描,也可以实现为客户端计算机上的防病毒工具或浏览器扩展。超出静态分析的恶意软件检测或缓解技术,例如基于分析客户端代码的执行,超出了本工作的范围。
攻击者的目标是绕过恶意软件检测器。为此,攻击者可能会认为目标浏览器支持WebAssembly,这是当今几乎所有浏览器的情况。攻击者不需要访问恶意软件检测器,或者在基于机器学习的检测器的情况下,不需要访问其训练的数据。
4. 方法
A. Overview and Challenges
图1给出了Wobfuscator的概览。输入是一个JavaScript文件,我们将其解析为AST。接下来,该方法识别潜在的翻译站点,即(i)与检测恶意代码相关的代码位置,以及(ii)可以以语义保留的方式翻译成WebAssembly的代码位置。该方法不是针对一般的JavaScript到WebAssembly转换,而是机会主义地只针对满足这两个要求的代码位置。
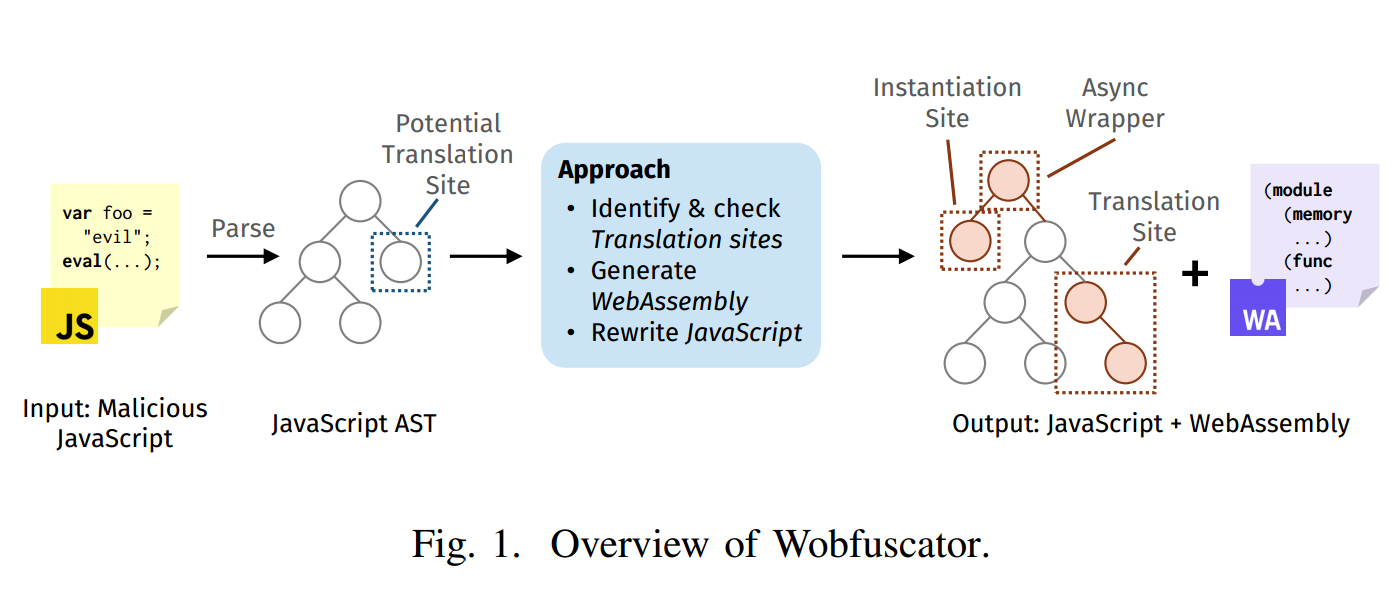
为了将行为转移到WebAssembly中,Wobfuscator为每个翻译站点生成WebAssemblys代码,然后转换JavaScript AST以利用生成的代码。AST通过三种方式进行转换。首先,在实例化站点,我们添加代码将WebAssembly模块加载到应用程序中。其次,在每个选定的翻译站点,我们修改代码以访问WebAssembly模块提供的属性和函数。第三,在AST的根节点,我们有条件地将脚本包装成一个匿名的异步函数,称为异步包装器,以支持代码中的异步关键字。本节的其余部分将详细解释这些转换。最后,Wobfuscator的输出是转换后的JavaScript代码以及一个或多个生成的WebAssembly模块。
在设计将JavaScript行为转换为WebAssembly模块的转换时,我们遇到了几个挑战。一个关键的挑战是,由于WebAssembly中的功能有限,不可能将通用JavaScript代码完全翻译成WebAssembly。一个例子是动态生成的代码,它在JavaScript中通过臭名昭著的eval函数启用,但在WebAssembly中不受支持。JavaScript支持相当复杂的规则,例如var绑定变量的函数作用域、hoisting of functions和闭包。WebAssembly只有三个存储位置:全局模块变量、每个函数的局部变量和原始字节内存。此外,WebAssembly只有有限的控制流指令,不能完全复制所有可用的JavaScript构造,如try/catch语句、for循环和Promises。另一个挑战是WebAssembly和JavaScript之间可以传递的数据类型有限。在WebAssembly的初始版本中,函数只能接受和返回数值数据类型,这无法复制JavaScript支持的复杂对象。最后,不同的浏览器可以对使用的WebAssembly模块施加文件大小限制,因此我们必须解决这个限制,以便我们的技术具有通用性。
由于这些和其他差异,Wobfuscator不是基于完整的,而是基于机会主义的翻译,即在不牺牲正确性的情况下,转换有助于避开恶意软件检测器的代码。
B. 变换(Transformations)
我们的目标是生成 WebAssembly 模块,以复现特定 JavaScript 代码片段的功能行为。为实现这些模块,Wobfuscator 构建在一组核心的变换规则之上:
定义 1(变换规则):一个变换规则是一个三元组 ((L, t, p)),其中:
- (L) 表示可应用该变换的一组代码位置;
- (t) 是一个变换函数,它把 (L) 中某个代码位置处的 JavaScript 映射为改写后的 JavaScript 代码以及一个或多个 WebAssembly 模块;并且
- (p) 是应用 (t) 的前置条件,以谓词的形式作用在某个代码位置及其周围上下文上。
我们给出七条针对 JavaScript 不同语言特性的变换规则。它们大体分为三类。
- 数据混淆类:混淆在一个 JavaScript 文件中被定义并使用的数据。此类规则针对字符串字面量(第 IV-B1 节)与数组初始化代码(第 IV-B2 节)。
- 函数调用混淆类:隐藏可疑的函数调用(第 IV-B3 节)或任意函数调用(第 IV-B4 节)。
- 控制流混淆类:混淆给定代码的控制流。此类规则针对 if 语句(第 IV-B5 节)、for 循环(第 IV-B6 节)以及 while 循环(第 IV-B7 节)。
表 I 对这些变换规则进行了示意说明。

这些变换规则使用了若干 JavaScript 原语与 WebAssembly 进行交互:
instanWasm(source, impObj):从source实例化一个 WebAssembly 模块并返回该模块。可选参数impObj是一个对象,包含需要导入到所创建 WebAssembly 模块中的函数。我们使用该原语的两个变体:同步与异步实例化(见第 IV-C 节)。loadStrFromBuf(buffer, startIndex):从buffer中自字节偏移startIndex开始创建一个字符串,直到遇到第一个空字节(即\00)为止;其中buffer是 WebAssembly 模块的线性内存。loadArrFromBuf(buffer, startIndex, length):从buffer的字节偏移startIndex开始,读取长度为length的片段并创建一个数组;其中buffer也是 WebAssembly 的线性内存。
1) 混淆字符串字面量(Obfuscating String Literals)
JavaScript 恶意软件常用编码字符串来隐藏恶意代码。这些编码字符串对于学习字符串模式及其编码方案的恶意软件检测器至关重要。为规避对编码字符串的检测,我们定义变换规则T1-StringLiteral,记为三元组 ((L_{T1}, t_{T1}, p_{T1})),其中:
(L_{T1}):允许应用规则 T1 的代码位置,均为 AST 中类型为
Literal且取值为字符串的节点。(t_{T1}):变换函数(在表 I 的 T1-StringLiteral 行给出)。为混淆字符串字面量
"lit",(t_{T1}) 生成一个 WebAssembly 模块,在其中 定义一段memory并将其导出到 JavaScript(第 2 行)。该内存用于在偏移 0 处存储字符串字面量"lit"(第 3 行)。为在 JavaScript 中重建该字符串,定义并导出一个包含该偏移量的变量$d1(第 1 行)。每个字符串都以空字节结束(即\00),因此可以从起始索引开始读取线性内存,直到遇到第一个空字节即可完成重建。若输入的 JavaScript 程序中有多个字符串需要变换,它们会被存储在同一个 WebAssembly 模块中;此时,为每个被存储的字符串可分别定义多个变量(如
$d1, $d2, ...)。变量buf指向由 WebAssembly 导出的内存(第 3 行)。在翻译位点,变量startInd获得存储于线性内存中的目标字符串字面量的起始索引(第 5 行)。最后,使用原语loadStrFromBuf并以buf与startInd为实参来重建字符串"lit"(第 6 行)。(p_{T1}):前置条件。该变换仅能应用于 JavaScript 允许用函数调用替换字符串字面量 的位置。具体地,以下情况不适用:
(i) 出现在import或require语句中的字符串字面量,因为在打包模块时这类字符串应当是静态已知的;
(ii) 作为属性名出现在对象表达式中的字符串字面量,因为函数调用的返回值不能用作对象键。
2) 混淆数组(Obfuscating Arrays)
恶意文件经常包含数值字面量数组,这些数值代表字符编码,用来重建恶意字符串。为混淆这类数组,我们利用这样一个事实:WebAssembly 模块的线性内存以 array buffer 形式暴露出来,而它可以自然地映射为 JavaScript 的数值数组。据此提出变换规则
T2-ArrayInitialization(((L_{T2}, t_{T2}, p_{T2}))),其中:
(L_{T2}):T2 可应用在
NewExpression类型的 AST 节点(例如new Array),或表示数组字面量表达式的ArrayExpression节点(例如[1,2,3])。此外,该变换还会把用于初始化数组元素的后续AssignmentExpression赋值语句收拢为一次 JavaScript 函数调用(如把arr[1] = 42; arr[2] = 97; ...合并)。(t_{T2}):其定义见表 I 的 T2-ArrayInitialization 一行。设原始 JavaScript 代码创建数组
arr,并把元素arr[i1]与arr[i2]初始化为数值num1与num2。变换后,(t_{T2}) 生成一个 WebAssembly 模块:该模块创建一段memory并将其导出(第 1 行);定义一个导出函数$f,把num1与num2写入线性内存中的指定偏移i1与i2(第 2–8 行)。在翻译位点,变换后的 JavaScript 代码实例化该 WebAssembly 模块(第 2 行),并创建一个变量以便读取导出的内存(第 3 行)。与 T1-StringLiterals 类似,若有多个数组初始化需要变换,在翻译位点只创建一个 WebAssembly 模块;此时调用导出函数f把num1与num2分别写入线性内存的偏移i1与i2(第 5 行)。最后,loadArrFromBuf()从线性内存缓冲区复制数值,返回一个 JavaScriptArray对象,并将其赋给arr(第 6 行)。该函数需要数组在线性内存中的起始索引与数组长度两个参数——二者均由 Wobfuscator 计算并注入到每次loadArrFromBuf()调用中。我们保证返回的对象是标准的 JavaScriptArray,以便原始代码能够照常访问Array的标准属性与方法。(p_{T2}):该变换仅应用于用数值字面量初始化的数组。由于 WebAssembly 只有数值型数据类型,我们仅使用
.const与.store在内存中存放数值字面量。具体而言,只在以下任一情形满足时应用变换:new Array表达式,随后紧跟仅插入数值字面量的赋值语句;new Array表达式,其实参全为数值字面量;- 仅包含数值字面量的
ArrayExpression。
3) 混淆函数名(Obfuscating Function Names)
一些内置的 JavaScript 函数(例如臭名昭著的 eval)经常被攻击者滥用。因此,检测器可能会把这些内置函数名视为可疑,并将其作为恶意软件检测的特征之一。为规避这类检测,我们通过变换规则
T3-FunctionName(((L_{T3}, p_{T3}, t_{T3})))从 JavaScript 代码中移除可疑函数名:
(L_{T3}):T3 可应用在包含特定标识符名称的
CallExpression节点或NewExpression节点上。(t_{T3}):其定义见表 I 的 T3-FunctionName 一行。以混淆函数名
"eval"为例,(t_{T3}) 会把该函数名从 JavaScript 中移除并将其存入 WebAssembly 线性内存。在 WebAssembly 代码中:- 定义并导出一个全局变量
$d1,其值为0(第 1 行),表示线性内存中字符串"eval"的起始索引; - 创建并导出一段
memory(第 2 行); - 定义一个数据段,在偏移 0 处写入
"eval"(第 3 行)。
在变换后的 JavaScript 代码中:
- 实例化该 WebAssembly 模块(第 2 行),并定义一个变量用于访问线性内存(第 3 行);
- 变量
startInd被赋值为导出的d1,即线性内存中"eval"的起始索引(第 5 行); - 最后调用
loadStrFromBuf重建字符串"eval",并通过window对象以该字符串(记作str)调用eval,其实参与原始eval()中使用的相同(第 6 行)。
- 定义并导出一个全局变量
(p_{T3}):该变换可应用于通过
window对象可访问的全局函数的调用表达式或 new 表达式。我们识别出恶意文件中常用的 8 个全局函数,并仅在标识符属于下列列表时应用该变换:eval,atob,btoa,WScript,unescape,escape,Function,ActiveXObject。
虽然这些函数本身并非天然恶意,但我们分析的许多恶意软件样本会利用它们来解码并执行隐藏代码。
4) 混淆调用(Obfuscating Calls)
除了前述可疑函数外,我们还为一般的 JavaScript 函数调用构造了变换规则 T4-CallExpression。该变换把 JavaScript 中的函数调用改写为:先调用一个导出的 WebAssembly 函数,而这个 WebAssembly 函数再去调用导入到 WebAssembly 的 JavaScript 函数。与完全从 JavaScript 中移除可疑函数名的 T3-FunctionName 不同,这里是改变调用点处被调用函数的上下文,从而影响基于 AST 的恶意软件检测器在扫描恶意代码时所见到的语境。
该变换需要在WebAssembly MVP 兼容性与可变换的函数调用数量之间做权衡。因此我们给出两个变体:
- T4-CallExpression(a):完全兼容 WebAssembly MVP(不使用任何语言扩展),仅能用于无返回值的函数;
- T4-CallExpression(b):可处理有返回值的函数,但需要 WebAssembly Reference Types 提案的支持(Firefox 与 Chrome 默认已启用此提案)。
T4-CallExpression(a)
规则:((L_{T4a}, p_{T4a}, t_{T4a}))
(L_{T4a}):为包含被调函数标识符及实参的
CallExpression节点。(t_{T4a})(见表 I 的 T4-CallExpression(a) 行):为混淆一次
f(a)形式的 JavaScript 调用,(t_{T4a}) 将该调用包裹进一个匿名函数,并把这个匿名函数作为导入传入 WebAssembly(第 2 行)。在原始调用点,改为调用一个 WebAssembly 导出函数$f0(第 4 行)。在 WebAssembly 代码中,包裹 JavaScript 调用的函数被作为$impFunc导入;导出函数$f0的实现就是调用这个被导入的$impFunc(第 1–2 行)。注意,用于包裹原始 JavaScript 调用的匿名函数始终具有相同的类型签名:无参数、无返回(
void)。因此,同一个 WebAssembly 模块可以编译一次,重复复用到每个被替换的函数调用上;我们只需在不同的调用点改变导入对象中所包含的具体 JavaScript 函数即可。(p_{T4a}):仅当调用表达式没有返回值被用于赋值或其他表达式时可用,因为 WebAssembly 的基本数据类型
i32, i64, f32, f64无法覆盖 JavaScript 可能的所有返回值类型。
T4-CallExpression(b)
规则:((L_{T4b}, p_{T4b}, t_{T4b}))
(L_{T4b}):与 (L_{T4a}) 相同。
(t_{T4b})(见表 I 的 T4-CallExpression(b) 行):实验性的 WebAssembly Reference Types 提案新增了值类型
externref,可在 WebAssembly 与 JavaScript 之间传递任意 JS 值的引用。利用该类型,变换仅需导入被变换函数的引用。具体而言:变换后的 JavaScript 代码把函数引用f导入到 WebAssembly(第 2 行)。在原始的f(a)调用点,f被替换为 WebAssembly 的导出函数$f0,该函数接收原调用的实参a并返回原函数可能产生的任何值(第 4 行)。在 WebAssembly 代码中,导出函数$f0的输入类型与返回类型均为externref(第 1 行);在$f0内部,它以传入的值为参数调用导入的$impFunc(第 2–3 行)。
相比 (T4a),该变体的优势是:支持更多的函数调用(包括有返回值的情形),并把更多行为迁移到 WebAssembly 内部完成。(p_{T4b}):仅当同时满足以下条件时可用:
(i) 被调函数内部不包含对this的引用;
(ii) 调用实参中不包含this的引用;
(iii) 被调函数中引用到的变量的数据依赖不包含this;
(iv) 被调函数不是字面量值的方法;
(v) 被调函数不是特殊函数bind或super。
条件 (i)–(iv) 的原因是:从 WebAssembly 内部调用函数时,this的取值会被改变,可能导致错误行为;条件 (v) 则源于bind与super对调用方式有严格限制,无法作为导入函数传给 WebAssembly 模块。
笔者注:对(iv)的解释如图

5) 混淆 if 语句(Obfuscating If Statements)
通过利用 WebAssembly 的控制流指令,可以把 JavaScript 中 if–else 语句的行为迁移到 WebAssembly 中,从而隐藏语法结构同时保持语义不变。为此,我们给出变换规则 T5-IfStatement ((L_{T5}, p_{T5}, t_{T5})),其中:
(L_{T5}):该规则适用于
IfStatement节点。(t_{T5}):其定义见表 I 的 T5-IfStatement 行。在翻译位点,(t_{T5})把
if分支与else分支内的代码分别包裹到两个匿名函数中,并将这两个匿名函数作为导入函数传入 WebAssembly(第 2–4 行)。随后调用一个 WebAssembly 导出函数f,并把原if条件的结果转换为整数(0 或 1)作为参数传给f(第 6 行)。在 WebAssembly 模块中,包裹
if与else代码的两个函数分别作为$imp1与$imp2被导入(第 4、6 行)。导出函数$f接收一个整型参数p,其值为 0 或 1,充当布尔值使用(第 1–7 行)。$f内部含有if–else指令,由参数p决定分支:若p ≠ 0,if指令调用包含原if分支代码的$imp1;若p = 0,则走else分支,调用包含原else代码的$imp2。借助 WebAssembly 的if–else指令,我们既保持了原有语义,又在 JavaScript 层面隐藏了控制流结构。(p_{T5}):只有当
if的两个分支不包含以下关键字时,才能进行此变换:break、continue、return、yield或throw。这些关键字与把内层代码封装为函数的做法不兼容。
6) 混淆 for 循环(Obfuscating For Loops)
为混淆 for 循环,我们定义变换规则 T6-ForStatement ((L_{T6}, p_{T6}, t_{T6})):
(L_{T6}):变换位置为
ForStatement节点(C 风格for循环)。(t_{T6}):见表 I 的 T6-ForStatement 行。在翻译位点,(t_{T6}) 将循环条件、自增(更新)表达式与循环体分别包裹为三个 JavaScript 函数,并把它们导入 WebAssembly 模块(第 3–8 行)。循环变量的初始化可以安全地外提到循环作用域之外(第 2 行)。最后,调用一个 WebAssembly 导出函数
f来模拟 JavaScript 的for循环(第 11 行)。在 WebAssembly 模块中,上述三个函数分别作为
$cond(条件)、$incre(更新)与$body(循环体)被导入(第 4、7、8 行)。导出函数$f含有一个代码块,其标签为$L0,该块内部又包含一个标签为$L1的loop块(第 2–3 行)。在loop中,首先调用$cond(第 4 行)以求得测试条件,并用i32.eqz检查结果(第 5 行)。若条件为假,br_if $L0跳转到$L0末尾,从而终止循环(第 6 行);若条件为真,则依次调用$body与$incre执行循环体与更新(第 7–8 行),随后br $L1跳回标签$L1以继续下一轮迭代(第 9 行)。(p_{T6}):与 (p_{T5}) 相同(即循环体与更新表达式中不得出现
break、continue、return、yield、throw)。
7) 混淆 while 循环(Obfuscating While Loops)
与上文类似,我们为 while 循环给出变换规则 T7-WhileStatement ((L_{T7}, p_{T7}, t_{T7})):
(L_{T7}):适用于
WhileStatement节点。(t_{T7}):见表 I 的 T7-WhileStatement 行,其总体流程与 (t_{T6})相似。主要差异在于
while循环没有更新表达式与循环计数器初始化。因此,仅需把循环条件与循环体分别包裹成匿名函数并导入 WebAssembly(第 4、7 行);定义并导出函数$f,通过在loop中调用导入函数来模拟 JavaScript 的while(第 5 行)。(p_{T7}):与 (p_{T5}) 和 (p_{T6})相同。
C. 同步与异步的 WebAssembly 实例化
对第 IV-B 节中的每条变换规则(除 T4-CallExpression(b) 外),我们都给出了两种变体,它们的区别在于:是否同步或异步实例化 WebAssembly 模块——也就是 instanWasm() 原语的不同实现方式。
同步实例化
同步变体使用 WebAssembly.Module 与 WebAssembly.Instance 两个构造器完成实例化。要点如下:
- 将已编译的模块字节传入
WebAssembly.Module构造器。该构造器接收类型化数组作为输入,因此我们把模块字节先编码为 base64 字符串,并在运行时解码为Uint8Array后再传入。 - 随后把得到的 模块对象与导入对象一起传入
WebAssembly.Instance构造器,获得的 实例对象供各个变换函数使用。

上述做法属于标准的同步代码,原则上对如何与原始 JavaScript 应用集成并无限制。然而,WebAssembly.Module 构造器会阻塞 JS 主线程,各浏览器厂商并不推荐这种方式。尤其是在 Chromium 系列中,输入模块大小被限制为 4KB 以内,超出则抛出异常。
为绕过该限制,每个同步变换可以输出一个或多个 WebAssembly 模块:
- 仅产生一个模块/翻译点的规则:T3-FunctionName、T4-CallExpression(a)、T5-IfStatement、T6-ForStatement、T7-WhileStatement。
- 可能产生多个模块的规则:T1-StringLiteral、T2-ArrayInitialization、T4-CallExpression(b)。原因是这些规则在模块中存放的数据规模可能超过 4KB。
当单个模块过大(例如数据段包含大量字符串字面量)时,我们会将其拆分为多个模块以保证每个模块不超过 4KB。对于单个字符串若超过 4KB,也会把其拆分到多个模块中,并在字符串重建阶段再进行拼接。
异步实例化
我们同时支持浏览器推荐的异步实例化方式。与同步方式相比,异步方式具有多项优势:
- 模块大小不受限制;
- 允许将生成的 WebAssembly 模块存放到独立文件;
- 使每个变换都可以只输出一个 WebAssembly 模块。
在这些异步变体中,instanWasm() 通过 WebAssembly.instantiateStreaming() 实现,如图3所示。该 API 会在独立线程上完成编译,不再阻塞主线程;它返回一个 Promise,因此需要使用 await 等待其解析完成后再继续执行。

- 由于
await只能在async函数中使用,我们将实例化过程包装在一个async的匿名函数中。相应地,调用该匿名函数的语句也必须加上await;若把此过程放在某个外层函数(例如someFunction)中,则该外层函数需要标注async。此外,代码中任何调用该外层函数的地方,也都需要增加await。 - 由此可见,在某一处翻译位点引入
async/await,会使这些关键字沿调用链向外传播,影响到整个文件中的相关函数定义与调用点。
这种关键字传播使得异步变体的设计与实现并不简单。我们遇到了三类难以传播 async/await 的代码位置:
- 作为实参传递的匿名函数(如
.map等)——需根据被调用函数的返回类型判断await应添加在被调函数的定义中还是其调用处; - 类构造函数无法被标记为
async——因此需要在整个调用链中检测是否存在构造函数调用; - 若变换后的函数被模块导出,则其他文件在导入并调用该函数时也必须检查并相应地添加
async/await。
小结与限制
除 T4-CallExpression(b) 外,其余所有变换规则均提供同步与异步两个变体。T4-CallExpression(b) 依赖一个实验性的 WebAssembly 提案,其前置条件复杂;若再叠加异步方式的额外限制,可能会破坏原始语义并导致错误的变换。另一方面,T4-CallExpression(b) 相比 (a) 暴露了更多翻译点,从而增加了可能出现的边界情形。因此,将二者结合留作未来工作。
D. 应用变换(Applying Transformations)
我们现在给出将这些变换应用到给定 JavaScript 抽象语法树(AST)的总体算法。算法的输入是:一组变换规则,以及原始 JavaScript 文件的 AST。算法包含三个步骤:(a)识别应当施加变换的 AST 节点,即翻译点(translation sites);(b)通过修改这些翻译点为根的子树来重写 AST;(c)在 AST 根部添加代码以实例化生成的 WebAssembly 模块。算法的输出是对应于混淆后 JavaScript 代码的已变换 AST。
a) 将 AST 节点识别为翻译点(Identifying AST Nodes as Translation Sites)
为了识别翻译点,我们从根节点开始对 AST 执行先序遍历。对每个访问到的节点 n,算法都会遍历变换规则列表并检查哪些规则可用。若某个变换规则 (L, t, p) 适用,则其前提 p 在节点 n 上成立,且 n 所在的位置属于位置集合 L。对每一条变换规则,我们都会产生一个与之对应的翻译点节点集合。
b) 重写 AST 子树(Rewriting AST Subtrees)
在识别出所有翻译点节点之后,下一步是重写以这些节点为根的子树。算法会按目标句法结构的粒度大小来应用各类变换。具体而言,我们按如下顺序遍历变换规则,并且在进入下一条规则之前,对所有可应用的子树都施加当前规则:
T1-StringLiteral, T2-ArrayInitialization, T3-FunctionName, T4-CallExpression, T5-IfStatement, T6-ForStatement, T7-WhileStatement。
这样的排序确保:针对更细粒度句法结构(如字符串与数组字面量)的变换先于针对更粗粒度结构(如循环)的变换执行——否则,先做粗粒度改写可能会阻止后续细粒度变换的应用。对于每条规则 (L, t, p),算法会访问其所有翻译点节点,并应用变换函数 t。该函数就地(in-place)修改 AST,并产生在重写代码中要使用的一个 WebAssembly 模块。该步骤的输出是重写后的 AST以及一组 WebAssembly 模块集合 W。
c) 添加 WebAssembly 实例化代码(Adding WebAssembly Instantiation Code)
最后一步是在代码中添加对集合 W 中 WebAssembly 模块的实例化逻辑。为此,算法会在脚本开头(即 AST 的根部)插入相应的语句。对于同步实例化的模块,我们将 W 中的每个模块编码为 base64 字符串,并加入解码与实例化这些模块的语句。对于异步实例化的模块,我们把模块序列化到单独文件,并在代码中发起相应的 fetch 请求。对异步翻译,算法还会在 AST 根部周围额外添加 async wrapper(见第 IV-A 节),以便后续代码能够使用异步关键字。
5. 实现
我们用Node.js(v14.17.2)和TypeScript实现了Wobfuscator。该工具依靠Esprima(v4.0.1)[3]和Espree(v7.3.1)[2]包来解析JavaScript文件,并依靠Escodegen(2.0.0)[1]将转换后的AST转换回JavaScript文件。Wabt.js(1.0.23)[8]包用于生成混淆中使用的WebAssembly模块。
我们的评估数据已开源:https://github.com/js2wasm-obfuscator/translator. 我们根据要求提供Wobfusctor的实现。我们认为,这一策略最大限度地减少了恶意使用的威胁,同时也帮助研究人员独立复制我们的结果,确认现有恶意软件检测器的已识别弱点,并为未来改进恶意软件检测器研究奠定基础。
6. 评估
我们评估了Wobfusctor及其使用机会翻译到WebAssembly来混淆恶意JavaScript的能力,以及以下主要研究问题:
- RQ1–有效性:该方法在规避最先进的JavaScript恶意软件检测器方面有多有效,哪些转换最有效?我们的方法与其他最先进的混淆器相比如何?
- RQ2–正确性:我们的代码转换是否保留了转换代码的语义?
- RQ3–效率:转换会带来多少运行时和代码大小开销,应用转换需要多长时间?
为了研究这些问题,我们对我们的转换在逃避检测方面的有效性进行了全面分析。我们在恶意和良性文件的大型数据集上评估了针对Wobfuscator的最先进的检测工具。我们通过将我们的方法与最先进的开源混淆工具进行比较,来评估Wobfuscator产生的混淆优势。最后,我们使用广泛使用和成熟的npm模块的广泛测试套件来验证我们工具的正确性,并证明运行时和代码大小开销在现实世界中是可以接受的。
A. 实验配置
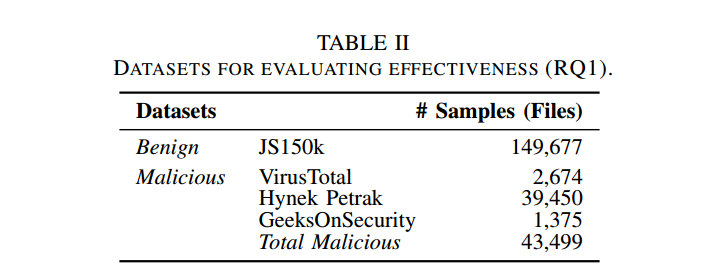
1) 数据集:由于不同的要求,我们为不同的研究问题使用不同的JavaScript程序数据集。为了回答RQ1,我们需要训练最先进的JavaScript恶意软件检测器,并将其应用于大量真实世界的良性和恶意JavaScript代码。表二总结了我们使用的数据集。良性代码由来自JS150k数据集的149677个文件组成[49]。恶意代码由43499个样本组成,其中2674个样本来自VirusTotal[7],39450个样本来自Hynek Petrak JavaScript恶意软件集合[47],1375个样本来自GeeksOnSecurity恶意JavaScript数据集[11]。这些数据集按其包含的恶意软件类别进一步细分,如特洛伊木马、勒索软件、滴管。我们在表IX的前四列中列出了恶意数据集的细分。
回答RQ2和RQ3需要在应用转换之前和之后执行代码。我们使用NPM上流行的大型JavaScript项目及其测试套件的数据集。为了确定合适的项目,我们从最依赖的NPM模块[12]中选择了六个包含广泛测试套件的模块(表V的第一列)。
2) JavaScript恶意软件检测器:我们针对四种最先进的、静态的、基于学习的JavaScript恶意软件探测器来评估我们的混淆技术。为了训练它们,我们将良性和恶意数据集分为训练集、验证集和测试集,分别包含70%、15%和15%的样本。我们按照每个项目提供的步骤,用所需的配置训练检测模型。
Cujo[50]是一种混合JavaScript恶意软件检测器,用于检测驱动器下载攻击。它对网站上运行的JavaScript文件进行词法分析,并通过监控抽象的运行时行为进行动态分析。对于我们的评估,我们使用了静态检测部分,该部分基于Fass等人[18]提供的Cujo的重新实现。
Zozzle[24]是一个主要是静态的浏览器内检测工具,它使用从JavaScript AST获得的语法信息,如标识符名称和代码位置,来识别恶意代码。这些特征被输入到贝叶斯分类器中,以将样本标记为良性或恶意。我们依赖于Fass等人[19]提供的Zozzle的重新实现。
JaSt[28]是一种恶意JavaScript的静态检测器,它使用来自AST的语法信息来生成连续节点的n元语法,以识别指示恶意行为的模式。我们使用项目GitHub页面上提供的实现[16]。
JStap[27]是一种静态恶意软件检测器,根据配置创建AST、控制流图(CFG)和程序依赖图(PDG),利用语法、控制流和数据流信息。该工具通过构造节点的n元语法或将AST节点类型与其相应的标识符/文字值组合来提取特征。在我们的评估中,我们重点关注具有n元语法和值特征提取模式的PDG代码抽象。我们使用GitHub上提供的实现[17]。
3) JavaScript混淆工具:我们将Wobfuscator与四种最先进的开源JavaScript混淆工具进行了比较。JavaScript混淆器[4]是一个JavaScript混淆工具,支持多种混淆技术,包括变量重命名、死代码注入和控制流扁平化。Gnirts[15]专注于在JavaScript文件中修改字符串文字。Jfogs[70]是一个混淆工具,专注于从调用站点中删除函数调用标识符和参数。JSObfu[5]是一个混淆器,支持将函数标识符和字符串文字转换为计算为常量的表达式。此混淆器还支持字符转义、空白删除等。
在包含Intel Core i7的台式机上进行的所有实验CPU@3.20GHz运行Ubuntu 20.04的32 GB内存。
B. 躲避探测的有效性(RQ1)
1) 我们方法的有效性(Effectiveness of Our Approach)
为评估 Wobfuscator 逃避静态恶意 JavaScript 检测器的能力,我们将各检测器在原始输入程序上的表现,与应用混淆之后的表现进行对比。由于这些检测器把每个程序分类为良性或恶性,因此可采用二分类器的常用度量:精确率(precision)与召回率(recall)。精确率等于真正例(TP)(被正确识别为恶意的程序数)除以被标记为恶意的总数(无论正确与否);召回率等于真正例除以数据集中所有恶意程序的数量。即:
一个好的恶意软件检测器应当同时具有高精确率与高召回率。低精确率意味着误报(FP)很多,会导致系统去拦截并破坏良性的脚本和常用网站,这样的工具不会被真实用户采纳。低召回率意味着实际的恶意程序只有少数被发现,从而限制了检测器的实用性。我们的混淆的主要目标,是降低检测器的召回率。
部分检测器无法解析某些原始与变换后的代码样本,原因在于它们对 JavaScript 语言的支持已过时或不完整。由于这是检测器实现细节所致(而非检测方法本身的结果),我们选择将这些样本排除在计数之外,而不是把它们记作误报或漏报。因此,各检测器在不同变换下的召回率分母会有所不同。
结果(Results)
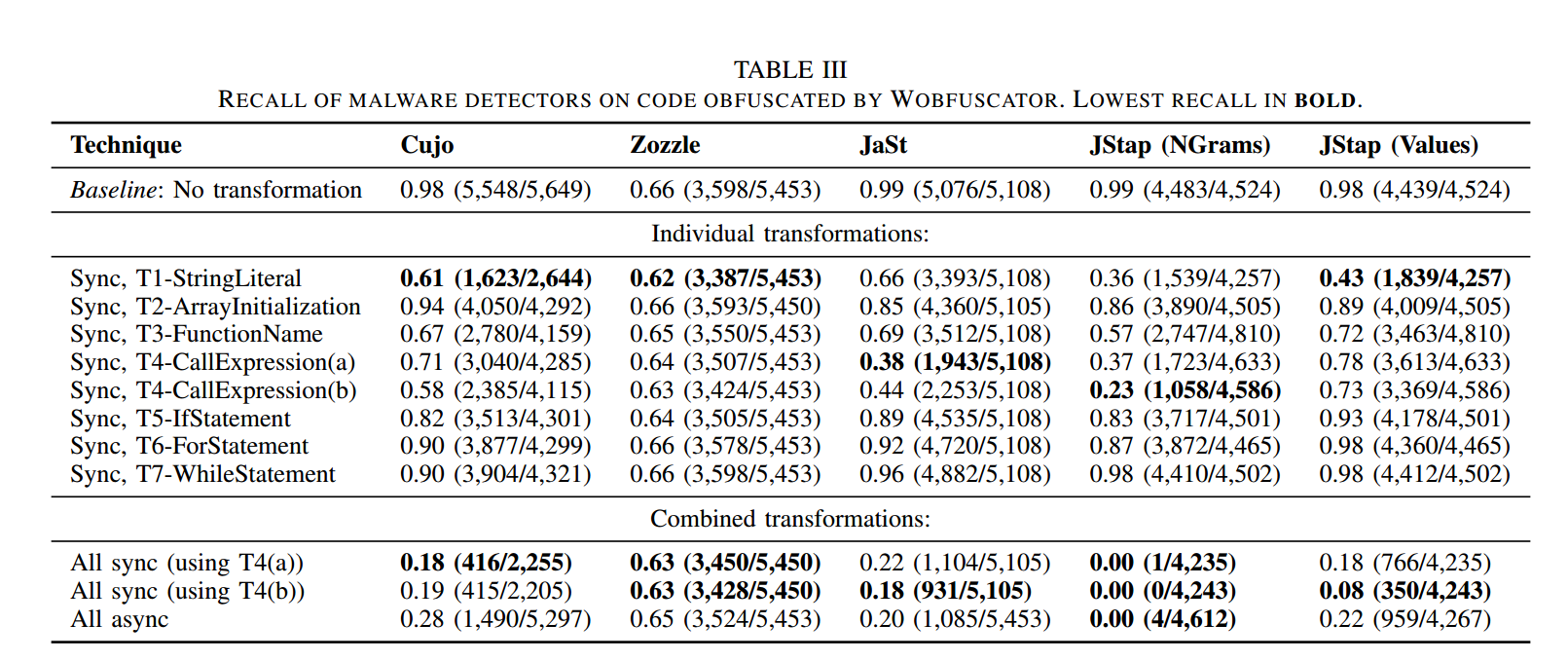
表 III 给出了第 VI-A2 节所述各检测器(列)在运行我们混淆后的代码(行)时的召回率。第一行给出的是在未进行混淆情况下每个检测器的召回率,作为基线。表格的中间部分展示了逐类变换单独应用时的结果——也就是说,每次只应用一种变换。例如,第二行显示:将同步变换技术 T1-StringLiteral 应用于恶意样本测试集时,Cujo 的召回率为 0.61,相较于基线 0.98 有显著下降。结果表明:不同的翻译/变换技术对不同检测器的抑制效果并不相同。对每个检测器,我们将最小的召回率加粗,以突出单一变换下的最佳表现。比如,我们发现 T1-StringLiteral 对 Cujo、Zozzle 以及 JStap 的 values 模式效果最好;T4-CallExpression(a) 对 JaSt 效果最佳,而 T4-CallExpression(b) 则对 JStap 的 n-grams 模式效果最佳。由于每条变换规则至少能降低某一个检测器的召回率,所有变换都是我们方法有效性的关键组成部分。
接下来我们解释为何某些检测工具更不适应某些变换。Cujo 对恶意文件做词法级分析,它会学习到可指示恶意行为的字符串特征;而 T1-StringLiteral 会移除这些标识符,使得 Cujo 无法在文件中找到可疑的词元。Zozzle 识别的是句法特征的恶意组合及其上下文;由于 T1-StringLiteral 会移除恶意字符串(如 shellcode、动态代码)的大量使用,那些高度依赖这些字符串的恶意样本会从 AST 中移除关键指示性特征,从而逃避 Zozzle。JaSt 使用 AST 语法节点的 n-grams(默认长度为 4)来检测恶意模式;T4-CallExpression(a) 会把一个单一的 CallExpression 节点替换为多个节点,用于处理 WebAssembly 模块的实例化。由于这种翻译引入的节点数大于滑动窗口的长度,它会扰乱已知恶意 n-gram 模式的检测。JStap(n-grams 模式)会在输入文件的 AST 上构造程序依赖图(PDG),通过在 AST 上添加表示数据流的边来实现;而 T4-CallExpression(b)(以及其他变换)会把数据流改道至生成的 WebAssembly 模块中,从而削弱 JStap 能够提取的 n-gram 特征,影响其数据流分析。JStap(values 模式)对 T1-StringLiteral 的影响尤为敏感,因为它在选择要提取的特征时依赖字面量;而 T1-StringLiteral 会移除部分字面量。
表 III 的下半部分展示了一次性应用所有变换规则时的结果。我们报告了三种变换组合:
- “All sync (using T4(a))” 与 “All sync (using T4(b))”:分别表示所有同步类变换,但在 T4 规则中分别使用 T4(a) 或 T4(b)。
- “All async”:表示表 I 中的所有变换(除 T4(b) 之外)都采用其异步版本。
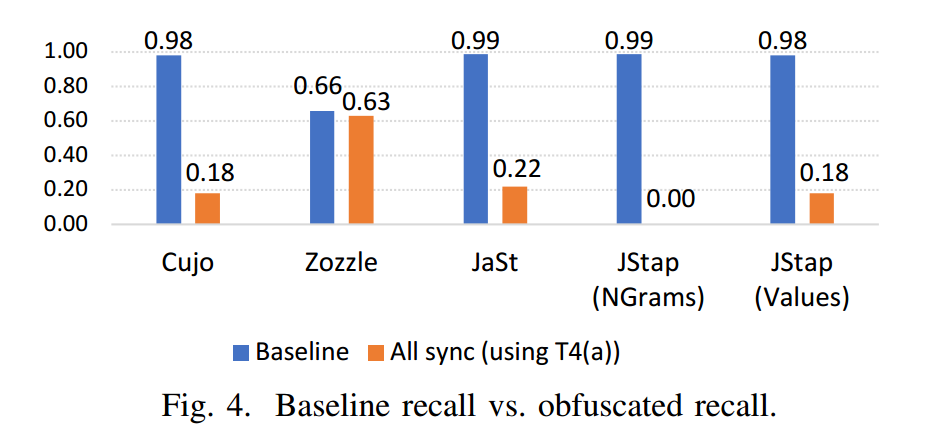
我们发现,将所有变换规则组合起来会显著降低各检测器的召回率。具体而言,在 “All sync (using T4(a))” 这一组变换下,Cujo、Zozzle、JaSt、JStap(NGrams)以及 JStap(Values) 的召回率分别为 0.18、0.63、0.22、0.00 和 0.18。综合其性能以及与 WebAssembly MVP 语言的兼容性,我们选择 “All sync (using T4(a))” 作为 Wobfuscator 的默认配置。图 4 对该配置(“All sync (using T4(a))”)的结果做了可视化。
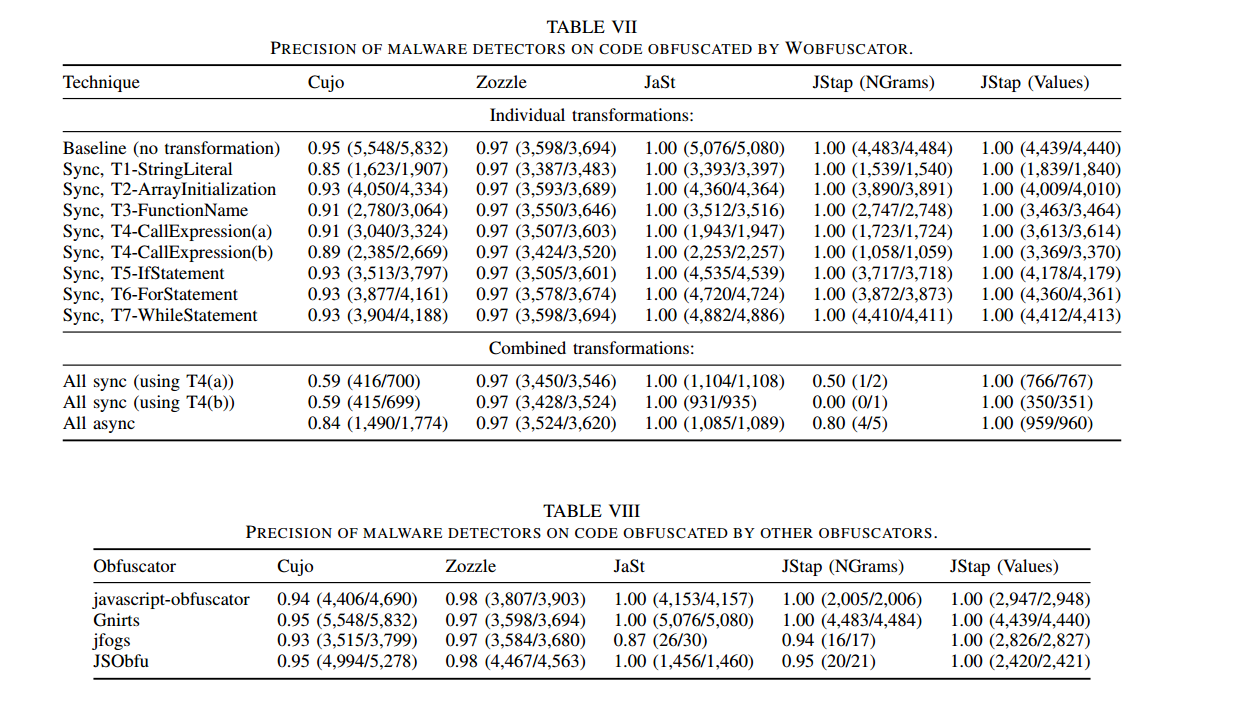
我们的主要目标是降低检测器的召回率,但我们也同时评估了精确率。各类变换的精确率见表 VII。对大多数已应用的变换而言,精确率保持在 0.9 到 1.0 之间。然而,某些具体变换会对某些检测器的精确率产生较大影响,例如:“All sync (using T4(a))” 会将 JStap(NGrams) 的精确率降至 0.5。这表明,尽管降低精确率并非我们的主要目标,Wobfuscator 仍可能降低某些检测器的精确率。
2) 与其他混淆器的比较
为了演示Wobfuscator与当前可用的JavaScript混淆器的对比,我们在第VI-B1节中使用的同一数据集上评估了四种混淆工具。我们收集了五个恶意软件检测工具在对每个工具混淆的数据集进行评估时获得的精确度和召回率值。与第VI-B1节类似,一些检测器无法解析某些模糊文件,导致同一检测器列中的值具有不同的分母。
结果(Results)
表四显示了在第VI-A3节(行)中描述的四种混淆工具中的每一种混淆的代码上运行时检测工具(列)的召回值。最后一行显示了Wobfuscator获得的最佳召回值。
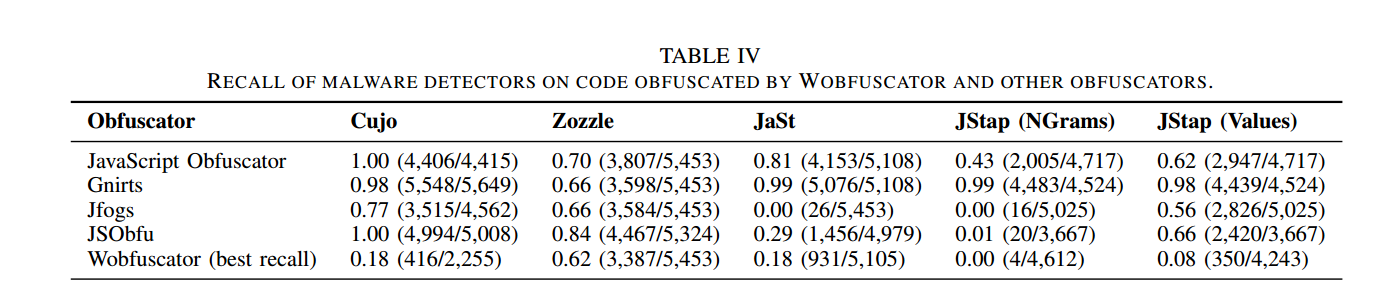
结果表明,在恶意软件检测器的召回率降低方面,Wobfusctor优于当前的混淆器。唯一的例外发生在Jfogs对JaSt进行评估时。在这种情况下,Jfogs的0.00召回率超过了Wobfusctor的0.18召回率。Jfogs的混淆主要是用新的中间变量替换标识符和文字,因此Wobfuscator可用于补充Jfogs。
例如,Jfogs将字符串文字移动到变量中,但它不会更改或删除文件中的字符串。使用T1 StringLiteral转换,可以从JavaScript文件中完全删除字符串文字,从而减少检测器可用的语法信息。
3) 按恶意软件类型细分结果
恶意数据集包含几种不同类别的恶意软件,包括加密矿工、特洛伊木马和滴管。我们提供了数据集中包含的恶意软件类别的细分。VirusTotal提供AV扫描程序报告的恶意软件类型。我们通过将类似的组合并在一起来减少恶意软件类别的数量,例如合并JS:Trojan。Gnaeus和JS:特洛伊木马。将代理程序归入特洛伊木马类别。对于GeeksOnSecurity,我们使用目录名来识别哪些样本是漏洞利用工具包,哪些是JavaScript滴管。Hynek Petrak数据集不提供样本的元数据,因此我们使用ClamAV扫描文件以获取恶意软件类别。为了证明Wobfuscator在混淆一组不同的恶意软件样本方面的有效性,我们测量了数据集中不同恶意软件类别的恶意软件检测器召回率的降低。出于篇幅原因,我们仅列出所有转换中恶意软件类别中观察到的最低召回率。
结果:表IX的第5-9列显示了当来自每个恶意软件类别(行)的样本被混淆时,恶意软件检测器(列)获得的召回值。除了召回率外,每个单元格还列出了检测器正确标记为恶意的文件数量,以及检测器在该类别中测试的恶意文件数量。标有“-”的列表示检测器无法解析恶意软件类别中的任何测试文件。对于网络钓鱼恶意软件类别,我们的测试数据集中没有出现样本,因此没有可用的召回值。五个最大的恶意软件组(Downloader、Misc.、Trojan、malware和Exploit)的结果表明,Wobfuscator可以显著降低不同恶意软件类别的召回率。
C. 转换的正确性(RQ2)
我们应用的转换改变了程序的句法结构。当然,这样的更改可能会影响程序语义,可能会使模糊程序的行为与原始程序不同,从而破坏功能的正确性。这就引出了两个相互矛盾的问题:首先,我们是否保持了输入程序的功能正确性,即我们的代码转换是否保持了语义?第二,多久应用一次转换?为了验证程序的正确性,我们利用了现有广泛使用的JavaScript项目的全面测试套件。我们将转换应用于测试代码,然后验证转换后的代码是否仍然通过测试。解决第二个问题,一个简单的正确性解决方案是只转换一小部分代码位置,以牺牲更少的代码混淆为代价来保留语义。因此,我们还评估了应用每个转换规则的频率。
转换的同步和异步变体之间的验证设置不同。在同步的情况下,我们可以简单地将转换应用于任何现有代码。为了验证异步转换的正确性,必须修改项目以支持异步执行,如第IV-C节所述。由于自动将任意JavaScript代码转换为异步代码并非易事,我们转而关注一个已经异步的NPM项目,即节点获取,因此简化了异步转换的应用。我们使用此项目来验证异步变体,并使用其他五个项目来验证同步变体。
结果:测试套件运行的结果如表5所示。该表列出了测试项目、其版本以及应用规则T1-T7的翻译站点的数量。最后两列列出了测试套件中的测试总数,以及受至少一个转换影响的测试数量。每个项目中的所有测试都成功通过,表明我们的混淆是语义保留的。
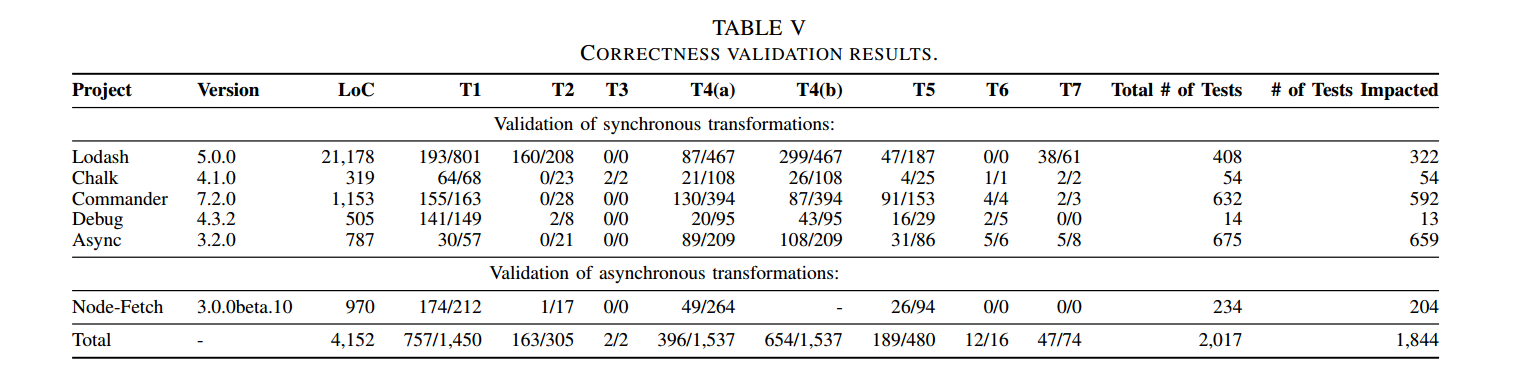
表V的第4-11列显示了与转换相关的可用代码位置总数中满足转换先决条件的转换代码位置的数量,无论它们是否满足先决条件。表V的最后两列显示,在五个测试套件中的2017个单元测试中,1844个(91.42%)依赖于至少受一个转换规则影响的函数。结果表明,我们的转换规则适用于现实世界中使用的代码位置。
D. 运行时和代码大小方面的效率(RQ3)
我们提出的Wobfuscator转换在WebAssembly模块中重新实现了原生JavaScript功能,例如调用函数、执行while循环、初始化数组等。因此,这将对翻译程序的性能产生影响。为了量化转换对性能的影响,我们使用了第VI-C节中描述的六个模块的测试套件。此外,还分析了转换引起的代码大小增加,包括添加的JavaScript和WebAssembly代码。
1) 翻译运行时:首先,我们测量对项目文件执行转换所需的时间。时间是用Linux中可用的time命令测量的,平均重复10次。我们通过将项目中使用的每个JavaScript文件的转换时间相加来计算项目的总转换时间。转换时间结果如表VI所示。
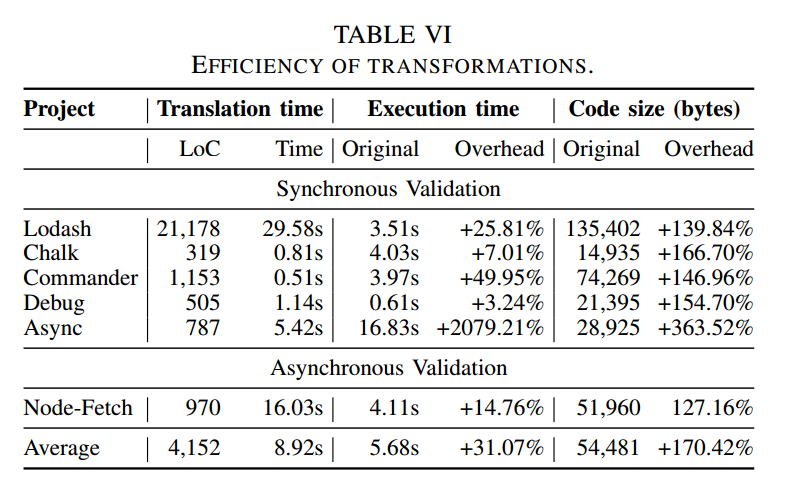
该表显示,对于最大的项目Lodash,它有21178行代码,应用所有同步转换的平均时间为29.58秒。对于最小的项目,包含319行代码的Chalk,应用转换的平均时间仅为0.81秒。此外,我们发现在表VI中的所有项目中,应用所有转换的平均时间仅为8.92秒。这些低转换时间表明,Wobfuscator对于JavaScript混淆是实用的。
2) 执行时间开销:执行开销时间是指完成转换项目的测试套件执行所需的运行时间的增加。我们使用time命令来测量应用转换前后项目测试套件的运行时间,报告十次重复测量的平均值。执行时间结果如表六所示。我们的转型增加了性能开销,从增加3.24%到增加2079%不等。虽然最高开销数字很大,但值得注意的是,这个大型运行时源于异步项目中的一个测试,该测试同时将异步函数应用于1048576个元素的集合。在大多数情况下,恶意软件样本不太可能遵循导致如此大开销的执行模式。平均而言,Wobfuscator增加了31.07%的性能开销。
3) 代码大小开销:代码大小开销是指项目中所有代码文件之间原始文件和转换输出之间的代码大小的增加。表VI列出了代码大小与原始大小相比的增长百分比。平均而言,在项目中应用所有转换后,代码大小增加了170.42%。总体而言,代码大小开销对于实际应用来说是可以接受的。
7. Discussion
本节讨论了防御基于WebAssembly的混淆的局限性和可能的缓解措施。
A. Limitations
Wobfusctor基于静态分析来定位恶意软件检测器,尽管它可以有效地绕过它们,但对于基于动态分析的检测器来说,它不太可能同样有效。这些转换将一些行为转移到WebAssembly中,同时保持最终的运行时行为不变。也就是说,例如,观察网站进行的浏览器API调用的动态检测器将观察到相同的行为,无论我们是否混淆。然而,在实践中,静态检测器更容易部署(例如,作为网络代理或浏览器扩展),而观察动态行为的设置更复杂,运行时成本更高。
另一个限制是,该方法仅对某些给定代码应用转换。如果代码位置不满足特定转换的先决条件,则无法转换。保守地保护转换对于确保我们的方法保留给定代码的语义至关重要,但也限制了它的适用性。
最后,我们的混淆依赖于浏览器中可用的WebAssembly。由于94%的已安装浏览器支持WebAssembly,这种限制在实践中可能是可以接受的。为了确保混淆的恶意软件按预期运行,攻击者可以检查WebAssembly支持,并仅在支持该语言的情况下加载混淆的代码。
B. Mitigations
尽管我们进行了混淆,但我们讨论了三种旨在检测恶意软件的缓解策略。第一种是基于动态分析的恶意软件检测。因为我们的方法保留了原始的JavaScript行为,所以动态检测器关注的许多运行时特征[53]不受混淆的影响。WebAssembly代码通过JavaScript调用web API,这意味着任何封装API函数或在浏览器中截取这些函数的运行时分析都可以看到该调用。然而,动态恶意软件检测器通常会带来不可忽视的运行时开销,并可能错过在特定配置中隐藏其恶意行为的恶意软件。
第二种缓解策略是基于防御者知道我们混淆的细节。由于混淆代码中的WebAssembly使用(例如加载许多小模块)可能是异常的,因此可以定义启发式规则来检测是否应用了Wobfusctor。同样,可以在用于学习恶意软件分类器的训练数据中包含用我们的技术混淆的代码。这些缓解措施的主要缺点是混淆并不意味着恶意。混淆代码是有正当理由的,例如保护知识产权。因此,将我们的技术或任何其他混淆技术混淆的所有代码归类为恶意代码可能会导致不可接受的大量误报。
最后,第三种缓解策略是联合分析JavaScript和WebAssembly。对于基于传统程序分析(静态或动态)的检测器,联合分析将解释数据和控制如何在两种语言之间流动。同样,基于学习的检测器,如我们评估中使用的检测器,可以将两种语言的代码输入到它们的模型中。我们不知道有任何支持WebAssembly的现有恶意软件检测器,但希望我们的工作能够提高人们对联合分析有用的认识。
8. 相关工作
混淆研究和技术:混淆技术已在各种编程语言和软件领域中被观察到用于恶意和良性目的。先前的研究对应用于恶意代码的混淆技术进行了分类[69],而其他研究则比较了不同混淆技术的有效性[22]、[32]、[61]。一些研究通过调查现实世界中恶意和良性文件中使用的混淆技术,分析了混淆技术在JavaScript代码中的使用情况[66],[55]。
很少有研究提出对JavaScript代码进行新的混淆攻击。Fass等人[26]构建了HideNoSeek,它将恶意程序的AST重写为已知良性程序的AST,以避免被检测到。作者对91020个样本进行了HideNoSeek抗VirusTotal、Yara、JaSt、Zozzle和Cujo的评估。模糊技术能够实现99.98%的探测器假阴性率。
恶意软件检测:学术研究中的一个活跃领域产生了静态分析技术,旨在即使在存在混淆代码的情况下也能识别恶意行为。
一类静态检测工具使用从JavaScript文件中导出的词汇和句法信息来识别指示恶意代码的特征[50]、[24]、[16]、[20]、[54]。技术通过结合控制流和数据流分析[27]或通过添加动态分析来确认恶意软件的存在[67],[59],以此语法信息为基础。其他静态检测技术通过机器学习和深度学习方法分析JavaScript源代码[63],[46]。Wobfusctor会影响这些检测器的检测率,因为它减少了可用的句法信息。此外,一些行为被转移到WebAssembly模块,这些检测器会忽略这些模块。
其他恶意软件检测技术动态分析程序以识别恶意行为。一些技术侧重于收集运行时统计数据来构建识别恶意软件的模型[23]、[53]、[68]。其他技术利用符号执行[39]或强制执行[38]来触发隐藏在复杂输入序列后面的恶意软件。Wobfusctor不太可能降低对这些检测器的检测率,因为我们不会显著改变运行时的行为。
混淆检测:一些现有的工作只专注于检测混淆,而不是混淆的恶意软件。NOFUS[35]和JSOD[13]使用句法和上下文信息作为机器学习分类器检测混淆的特征。Sarker等人[53]通过检测浏览器API并确定跟踪的API调用是否对应于静态代码位置,开发了一种混合方法。
WebAssembly和WebAssemblySecurity:Haas等人[31]解释了将新的字节码语言引入Web的动机和好处。一些作品研究了WebAssembly的安全方面,例如浏览器中未经请求的加密挖掘[40]、[45]、[52]以及如何检测和防御它[37]、[51]、[62]。Lehmann等人表明,源代码级内存漏洞可能会传播到WebAssembly二进制文件[41],这是一个影响许多现实世界二进制文件的问题[33]。然而,这两项工作都没有使用WebAssembly来隐藏任意的JavaScript行为。未来JavaScript和WebAssembly的联合恶意代码检测器可以基于Wasabi框架[42]或WebAssembly[29]的污染跟踪框架[57]构建。
9. 结论
许多工作都集中在使用静态分析识别JavaScript恶意软件上。然而,这些技术忽略了攻击者可用的最新web标准,即WebAssembly。为了绕过静态检测器,我们提出了Wobfuscator,这是一种基于一组七条转换规则的混淆方法,可以将JavaScript代码的特定部分机会主义地转换为功能相同的WebAssembly模块。我们针对四种最先进的静态JavaScript恶意软件检测器评估了我们的转换,并表明我们的方法有效地减少了对真实恶意软件样本的召回。我们证明,我们的技术优于仅基于JavaScript的其他混淆工具。最后,我们使用六个NPM包的测试套件来验证我们的转换的正确性,并展示它们的低性能开销。我们的结果表明,当前的静态检测器对实现跨语言代码混淆的技术无效,这激励了未来应对这一挑战的工作。
References
Citations
XMal: A lightweight memory-based explainable obfuscated-malware detector
Computers & Security 2023、CCF B
Finding the Dwarf: Recovering Precise Types from WebAssembly Binaries
PLDI 2022、CCF A