Ownership Guided C to Rust Translation
Ownership Guided C to Rust Translation
论文来自 Computer Aided Verification (CAV 2023) 的《Ownership Guided C to Rust Translation》。
摘要
Rust 常被称为更安全的 C,它是一门将内存安全与低层次控制相结合的现代编程语言。正是这种有趣的组合,使得 Rust 在开发者中非常流行;同时,也出现了将遗留代码库(通常是 C)迁移到 Rust 的增长趋势。本文提出了一种以静态所有权分析为核心的 C→Rust 翻译方法。我们设计了一套分析来推断 C 指针的所有权模型,并将这些指针自动转换为在 Rust 中的安全等价物。由此产生的工具 CROWN 能够扩展到真实世界的代码库(在不到 10 秒内处理 50 万行代码),并且实现了较高的转换率。
1. 引言(Introduction)
Rust [33] 是一门现代编程语言,兼具内存安全与低层级控制这两种令人兴奋的特性。尤其是,Rust 借鉴了所有权类型(ownership types)的思想来限制共享状态的可变性。Rust 编译器能够静态地验证相应的所有权约束,从而保证内存与线程安全。可证明的安全性这一独特优势使得 Rust 成为一种非常流行的语言,而将以 C 为主的遗留代码库迁移到 Rust 的前景也因此极具吸引力。
为响应这种需求,来自工业界与学术界的自动化 C→Rust 翻译工具相继出现 [17, 26, 31]。其中,工业级转换器 C2Rust [26] 将 C 代码改写为 Rust 语法,同时保持原有语义。然而,该翻译并不会综合(synthesise)一个所有权模型,因此最多只能复刻 C 中对指针的 不安全 用法。结果是,生成的 Rust 代码必须用 unsafe 关键字进行标注,允许一些编译器不会检查的操作。近期工作将重点放在减少这种 unsafe 标注上。特别地,工具 Laertes [17] 旨在通过搜索由 Rust 编译器给出的类型错误信息所引导的解空间,来改写 C2Rust 产生的(不安全的)代码。该结果令人印象深刻,因为它首次实现在逐行直接转换原始 C 源代码之外,综合(synthesise)出“正确”的 Rust 代码。另一方面,这种试错式方法的局限也很明显:系统既不支持对生成过程的推理,也无法对目标代码产生任何新的理解(除了“它能成功编译”这一事实)。
在本文中,我们提出一种更为系统化的路线:我们开发了一种新颖的指针所有权分析,既高效(可扩展至大型程序,在不到 10 秒内处理 50 万行代码),又复杂精细(能够处理嵌套指针与归纳定义的数据结构),并且精确(对字段与控制流均敏感)。我们的所有权分析在 Rust 的所有权模型上作出了一项加强性假设,从而不再需要别名分析。虽然这一假设排除了少量 Rust 的安全用法(见第 5 节的讨论),但它确保了所有权分析同时具备可扩展性与精确性,而这会进一步体现在 C→Rust 翻译整体的可扩展性与精度上。
该分析的首要目标,当然是促进 C→Rust 的翻译。正如本文其余部分将展示的,我们建立了一个自动化翻译系统,用来将所推导出的所有权模型编码进生成的 Rust 代码中,并由 Rust 编译器证明其安全性。然而,与现有方法常见的“把 Rust 编译器当作求解器”形成对比 [17, 31],这种分析式方法实际上从代码中提取了关于所有权的新知识。这些知识还可能带来更多后续用途,包括防止当前“安全 Rust”中仍允许的内存泄漏、识别先天不安全的代码片段等。
我们的主要贡献如下:
- 设计了一种可扩展且精确的所有权分析,能够处理复杂的归纳定义数据结构与嵌套指针。(见第 5 节)
- 基于所有权分析,提出一种面向 Rust 的重构技术以提升代码安全性。虽然本文聚焦其在 C→Rust 翻译中的应用,但该技术也可用于改进任意不安全的 Rust 代码的安全性。(见第 6 节)
- 实现了一个原型工具 CROWN(意为 C to Rust OWNership guided translation),能够将 C 代码翻译为安全性增强的 Rust。(见第 7 节)
- 使用一个基准套件对 CROWN 进行评估,该套件既包含常用的数据结构库,也包含真实世界项目(规模从 150 行到 50 万行不等),并将结果与当前最先进的方法进行比较。(见第 8 节)
2. 背景(Background)
我们首先对 Rust 做一个简要介绍,尤其是它的所有权系统以及指针的使用,因为它们是内存安全的核心。
2.1 Rust 的所有权模型(Rust Ownership Model)
Rust 中的所有权是一组规则,用来约束编译器如何管理内存 [33]。其思想是:将每个值与一个唯一的拥有者(owner)关联起来。该特性有助于内存管理。例如,当拥有者离开作用域时,为该值分配的内存可以自动回收。
let mut v = ...;
let mut u = v; // 所有权被转移给 u在上面的代码片段中,把 v 赋值给 u 的同时也转移了所有权;此后,除非给 v 重新赋值,否则不允许再访问 v。
这种永久的所有权转移虽然提供了强有力的保证,但在编程时也可能显得笨拙。为了允许在程序的不同部分之间共享值,Rust 使用借用(borrowing)的概念,即创建一个引用(reference)(以和号标记)。引用允许在不取得所有权的情况下指向某个值。借用会在一段有限的时间内授予读取、以及(在某些情况下)唯一地修改被引用值的临时权利。
时间这一维度又引出了所有权管理中的另一个概念——生命周期(lifetime)。对可变引用(在上面例子中以 mut 标记),同一时刻只允许一个;而对不可变引用(没有 mut 标记者),在不存在任何可变引用的前提下,可以并存多个。如你所料,可变/不可变引用与其生命周期的交互是高度非平凡的。本文聚焦于可变引用的分析。
2.2 Rust 中的指针类型(Pointer Types in Rust)
与 C 相比,Rust 拥有更丰富的指针体系。原生的 C 风格指针(写作 *const T 或 *mut T)被称为原始指针(raw pointers),它们不会参与编译器的所有权与生命周期检查。原始指针是不安全 Rust(见下一节)的一个主要来源。
惯用的 Rust 倡导使用 box 指针(写作 Box<T>)作为拥有指针,它们对堆分配拥有唯一所有权;同时使用引用(写作 &mut T 或 &T,见上一小节)作为非拥有指针,用于访问由他者所拥有的值。Rust 还提供了在运行期检查借用规则的智能指针(例如 RefCell<T>)。我们的翻译目标是不增加运行时开销地维持 CPU 时间,因此我们不会把原始指针重构为 RefCell<T>。
C 风格的数组指针在 Rust 中表示为指向数组的引用或切片引用,它们的数组边界分别在编译期与运行期已知。诸如“数组边界”这类元数据的创建超出了所有权分析的范围。在本文中,我们在翻译后的代码里保留数组指针为原始指针。
2.3 不安全的 Rust(Unsafe Rust)
出于务实的设计,Rust 允许程序包含一些编译器无法验证为内存安全的特性:例如解引用原始指针、调用底层函数等。这类用法必须用关键字 unsafe 标记,形成不安全 Rust 的片段。值得注意的是,unsafe 并不会关闭所有编译器检查;例如安全指针仍会被检查。
不安全 Rust 经常用于实现具有复杂共享的数据结构、弥补编译器尚不完备的能力,以及支持底层系统编程 [2, 18]。当然,它也可以用于其它原因。比如,c2rust [26] 会直接把 C 指针翻译成原始指针;如果没有不安全 Rust,这些生成的代码将无法通过编译。
3. 综述(Overview)
在本节中,我们通过两个示例对 CROWN 进行概述。第一个示例详细描述了单链表的 push 方法,第二个示例展示了一个来自真实基准程序的代码片段。
3.1 将元素压入单链表(Pushing into a Singly-Linked List)

图1a 中的 C 函数 push 会分配一个新结点,用于存放作为参数传入的数据。新的结点随后成为 list 的表头。该代码经由 c2rust 翻译为图 1b 的 Rust 代码。需要注意的是,c2rust 的翻译是基于语法的:它只是把所有 C 指针改写为 *mut 原始指针。由于解引用原始指针在 Rust 中被视为不安全操作(例如图 1b 第 16 行对 new_node 的解引用),push 方法必须用关键字 unsafe 标注(或者把其放入一个 unsafe 代码块中)。此外,c2rust 还为两个结构体定义插入了两条属性指令:#[repr(C)] 和 #[derive(Copy, Clone)]。前者保持与 C 相同的数据布局以便互操作,后者指示相应类型只允许通过“复制”来进行拷贝。
尽管 c2rust 在翻译中使用了原始指针,图 1b 的所有权方案仍然遵循 Rust 的所有权模型,这意味着这些原始指针是可以被转换为安全指针的。对新分配结点的指针在第 15 行被赋给 new_node,这使我们能够推断:新结点的所有权最初属于 new_node。随后在第 18 行,所有权从 new_node 转移到 (*list).head。另外,如果在第 17 行之前 (*list).head 已经拥有某个内存对象,那么在第 17 行该所有权又会转移到 (*new_node).next。这种所有权方案对应了安全指针的用法:(i)每个内存对象只与唯一所有者关联;(ii)当所有者离开作用域时,该对象会被销毁。关于(i)的一个例子是:当新分配内存的所有权在第 18 行从 new_node 转移到 (*list).head 后,(*list).head 成为唯一所有者,而 new_node 失效且不再被使用。关于(ii),由于 push 的参数 list 是一个输出参数(即可以在函数外部观察到),我们假设它在函数返回时必须继续拥有其引用到的对象。因此,在 push 方法中不会丢弃任何内存对象,而是将它们“归还”给调用者。
CROWN 会推断由 c2rust 翻译出的代码的所有权信息,并用这些信息把图 1b 的代码进一步翻译为图 1c 中更安全的 Rust。具体而言,CROWN 首先基于所有权信息把原始指针重新类型化(retype)为安全指针,然后重写它们的使用方式。
在 CROWN 中重新类型化指针(Retyping Pointers in Crown)
如果某个指针在其作用域的任意时刻拥有某个内存对象,CROWN 就把它重新类型化为 Box 指针。例如,在图 1c 中,局部变量 new_node 被重新类型化为 Option<Box<Node>>(安全指针类型被包一层 Option 以处理空指针的情况)。变量 new_node 在进入函数时是非拥有的,在第 13 行变为拥有者,并在第 16 行把所有权再次转移出去。
对于结构体字段,CROWN 会检查该结构体声明作用域内的所有代码。如果一个结构体字段在其结构体声明的作用域内的任意时刻拥有某个内存对象,那么它会被重新类型化为 Box。在图 1b 中,字段 next 与 head 分别在第 17 行与第 18 行被赋予所有权;因此它们在图 1c 中分别于第 4 行和第 9 行被重新类型化为 Box。
一个特殊情况是输出参数(例如本例中的 list)。此类参数虽然可能是拥有者,但 CROWN 会把它们重新类型化为 &mut,以便后续能进行借用(borrowing)。在 push 中,输入参数 list 被重新类型化为 Option<&mut List>。
在 CROWN 中重写指针使用(Rewriting Pointer Uses in Crown)
在重新类型化之后,CROWN 会按新的类型与使用环境重写指针用法。由于 Rust 语义的限制,这些重写规则略显繁琐(参见第 6 节)。例如,第 14 行对 new_node 的解引用会被重写为 (*new_node).as_deref_mut().unwrap(),因为它需要可变借用,并且 Box 的可选包装需要先被解包。同样,第 15 行的 (*list).head 会被重写为 ((*list.as_deref_mut()).unwrap()).head.take() 作为赋值左值(LHS),因为目标位置期望的是一个 Box 指针。
在 CROWN 的重写之后,先前用于包裹代码的 unsafe 代码块注解已不再必要。然而,CROWN 并不会主动移除这些注解。需要特别指出的是:即便在 unsafe 代码块内,安全指针仍会被 Rust 编译器检查。
3.2 在 bzip2 中释放参数列表

下面我们展示一个带有循环结构的真实世界代码片段的转换:来自 bzip2 的一段用于释放参数列表的代码。bzip2 定义了一种类似单向链表的结构 Cell,它保存一组参数名。在图 2 中,我们从源代码中抽取了一个释放参数列表的片段。这里,局部变量 argList 已经是一个构造好的参数列表,而 Char 是到 C 风格字符的类型别名。需要注意的是,图 2b 和 2c 中的 Cell 并不指 Rust 的 std::cell::Cell。
CROWN 能够准确地为该片段推断出所有权方案。首先,argList 的所有权被转移给 aa,随后在循环中被释放。在循环体内部,从 aa 访问到的 link 的所有权首先被转移给 aa2,接着从 aa 访问到的 name 的所有权在调用 free 时被释放。条件语句之后,aa 的所有权也会被释放。最后,aa 从 aa2 那里重新获得所有权。
处理循环。 对于循环,CROWN 只对其循环体分析一次,因为这一步已经能暴露出全部的所有权信息。对于像 Cell 这样的归纳定义数据结构,进一步展开循环体虽然可以更深入地探索数据结构,但不会暴露任何新的结构体字段:指针变量与结构体指针字段在循环迭代之间并不会改变所有权。另外,CROWN 还会在循环入口与出口处发出约束,将所有局部指针的所有权状态配平。例如,aa 和 aa2 在循环入口处的所有权状态将分别等同于循环出口处被推断出的“拥有(owning)”与“非拥有(non-owning)”。
处理空指针。 在 C 中,一个常见习惯是在 malloc 之后或 free 之前与空指针比较,例如:if (!p.is_null()) free(p);。这会带来问题,因为 then 分支与 else 分支会为 p 产生彼此冲突的所有权状态。我们采用与 [24] 类似的做法:在空分支中插入一个显式的空赋值,即 if !p.is_null() free(p); else p = ptr::null_mut();。由于我们将空指针同时视为“拥有”与“非拥有”,p 的所有权将由非空分支决定,从而使 CROWN 能够推断出正确的所有权方案。
翻译。 基于上述所有权方案,CROWN 按图 2c 的方式进行改写。需要注意的是,我们并不尝试改写 name,因为它是一个数组指针(其限制见第 7 节)。
4. 架构(Architecture)
在本节中,我们简要概述 CROWN 的架构。CROWN 接收一个包含 unsafe 代码块的 Rust 程序作为输入,并输出一个更安全的 Rust 程序:其中一部分原始指针被重赋型(retype)为安全指针(符合 Rust 的所有权模型),并相应地修改它们的使用方式。本文聚焦于将该技术应用到由 c2rust 自动把 C 程序翻译成 Rust 的情形:这些程序与原始 C 程序保持高度相似,只是把 C 语法替换成了 Rust 语法。
CROWN 在 Rust 的 MIR 上进行若干静态分析,以推断指针的属性:
- 所有权分析(Ownership analysis):计算代码中指针的所有权信息,即对每个指针在特定程序位置推断它是否为“拥有/非拥有”。
- 可变性分析(Mutability analysis):推断哪些指针被用于修改它们所指向的对象(受文献 [22,25] 启发)。
- 胖瘦分析(Fatness analysis):区分数组指针与非数组指针(受文献 [32] 启发)。
这些分析结果被汇总为类型限定符(type qualifiers) [21]。类型限定符是“原子属性”(例如:所有权、可变性与胖瘦)来修饰标准指针类型。随后,我们利用这些限定符进行指针重赋型。例如,一个“拥有的、非数组”的指针会被重赋型为 Box。指针被重赋型后,CROWN 会相应重写它们的用法。
5. 所有权分析(Ownership Analysis)
我们的所有权分析目标是:为给定程序计算一个所有权方案(ownership scheme),且该方案服从 Rust 的所有权模型(若此类方案存在)。该方案包含关于程序中指针在特定程序位置是否“拥有或非拥有”的信息。高层来看,我们的分析通过生成一组所有权约束(见第 5.2 节),并用 SAT 求解器(见第 5.3 节)来求解。对这些约束的一个满足赋值就是一个服从 Rust 语义的所有权方案。
我们的所有权分析对控制流与字段均敏感;字段敏感使得我们能够为结构体字段上的指针推断所有权信息。为达到字段敏感性,我们对访问路径(access paths)跟踪所有权信息 [10,14,29]。一个访问路径以“如何从初始的基变量被访问”来表示一个内存位置,它由基变量和一串字段选择操作组成。以图 1b 的程序为例,访问路径的示例包括:new_node(仅包含基变量)、(*new_node).next、以及 (*list).head。
我们的分析为每个访问路径都关联一个所有权变量;例如,p 关联所有权变量 ,而 (*p).next 关联所有权变量 。每个所有权变量可取值 1(该访问路径为拥有)或 0(为非拥有)。当我们说“某访问路径的所有权”时,我们指的是沿该访问路径最后访问到的 字段(或更一般地,指针) 的所有权;例如,“(*new_node).next 的所有权”即字段 next 的所有权。
5.1 所有权与别名(Ownership and Aliasing)
设计所有权分析的一个主要挑战是所有权与别名(aliasing)之间的相互作用。为理解问题,考虑下列代码清单中第 3 行的指针赋值。我们假设在该赋值之前的若干行允许推断:q、(*q).next 与 r 是拥有的,而 p 与 (*p).next 是非拥有的。另假设赋值之后的若干行要求 (*p).next 必须为拥有(例如稍后会显式释放 (*p).next)。据此,一个所有权分析可能合理地得出结论:所有权转移发生在第 3 行(因此 (*p).next 变为拥有),并且由此得到的所有权方案服从 Rust 语义。
let p, r, q : *mut Node;
// p 和 (*p).next 为非拥有;q、(*q).next 与 r 为拥有
(*p).next = r;
// 之后 (*p).next 必须具有所有权现在考虑别名。一种可能的假设是:在第 3 行之前,p 与 q 互为别名,这意味着 (*p).next 与 (*q).next 也互为别名。于是,在第 3 行之后,(*p).next 与 (*q).next 仍然别名(指向同一内存对象)。然而,根据上面的所有权方案,二者都是拥有的;这在 Rust 中是不允许的,因为一个内存对象必须有唯一拥有者。上述(简化的)所有权分析未能检测到该不一致,问题在于它忽略了别名。确实,若存在某个拥有的别名在所有权转移之后仍继续指向与 (*p).next 相同的对象,那么所有权就不应被转移给 (*p).next。
要精确获得别名信息非常困难,尤其是在存在递归定义的数据结构时。本文通过在 Rust 所有权模型下提出一个强化假设来减轻对别名检查的需求:我们限制指针在某条访问路径上获得所有权的方式,从而限制所有权与别名的相互作用。具体而言,我们引入一个新概念:所有权单调性(ownership monotonicity)。该性质指出:沿着一条访问路径,指针的所有权值只能不增加(只能下降)。
笔者注:文章不尝试完整分析别名关系
形式化地(见定义 1),令 在访问路径 是 的前缀时返回 true,否则返回 false——例如,。
回到前述代码清单,所有权单调性蕴含:对访问路径 (*p).next 有
而对访问路径 (*q).next 有
这意味着:如果允许 (*p).next 取得所有权,则 p 必须已经是拥有的。从而,p 的所有别名都必须是非拥有的;这又意味着 (*p).next 的所有别名——包括 (*q).next 在内——都是非拥有的。
定义 1(所有权单调性,Ownership monotonicity)
给定两条访问路径 与 ,若 ,则有 。
所有权单调性比 Rust 语义更为严格,这会使得我们的分析能够拒绝一些虽然会被 Rust 编译器接受、但我们不希望在翻译中接受的情形(见§5.4 的讨论)。在本文工作中,我们刻意选择用所有权单调性而非别名分析作为基础,因为这能让我们对翻译精度拥有更强的可控性。相反地,若采用别名分析,翻译精度就会直接受该分析准确率的支配(例如别名分析的误报,参见 [23, 40]),这可能导致 CROWN 放弃翻译那些其实是安全的指针。有了所有权单调性,我们能确切地知道哪些有效的所有权方案被排除了,并且我们可以显式地启用它们(同样见§5.4 的讨论)。
5.2 生成所有权约束(Generation of Ownership Constraints)
在生成约束时,我们假设给定一个 ,它表示程序中最长访问路径的长度。这样可以覆盖代码里所有被暴露出来的访问路径的所有权信息。稍后我们会讨论循环的处理,因为循环可能暴露更长的访问路径。
令 表示程序中所有访问路径的集合;记 返回访问路径 的基变量,而 表示从基变量出发、沿字段选择算子前进的步数。以上一节代码为语境,、,因此 、。接着,定义 返回以变量 为基变量、其路径长度位于下界 与上界 之间的所有访问路径集合:
例如,当 时,
所有权转移(Ownership Transfer)
程序中可发生所有权转移的语句包括 (指针)赋值与函数调用。本节讨论赋值;由于篇幅限制,跨过程的所有权分析规则见扩展版本[41]。我们在赋值处的所有权转移规则遵循 Rust 的 Box 语义:当一个 Box 指针发生移动时,它所指向的对象所有权也随之移动。如下伪 Rust 代码所示:
let p, q: Box<Box<i32>>;
p = q; // 发生所有权转移
// 之后禁止使用 q 以及 *q当所有权从 转移到 时, 也失去所有权。除重新赋值外,失去所有权后的 Box 指针不允许再被使用,因此上面第 3 行的对 或 的使用都是禁止的。
据此,我们强制如下所有权转移规则:若对某个指针变量(如例子中的 、)发生所有权转移,则对从该指针可达的所有访问路径(如 、)也必须发生所有权转移。而从当前正在讨论的指针可达的其他指针变量的所有权保持不变(例如若代码中出现赋值 导致发生所有权转移,则 与 自身仍保留其先前的所有权状态)。
指针赋值处的可能所有权转移(Possible Ownership Transfer at Pointer Assignment)

在赋值点的所有权转移由图3 中的规则 ASSIGN 给出。记判定式
表示:在约束集合 的前提下分析赋值 ,并生成新的约束集合 。我们使用撇号表示赋值后的变量状态。
给定指针赋值 。令 与 分别表示从 与 出发的所有访问路径集合;令 与 分别表示从 与 的基变量出发、能抵达 与 的访问路径集合。于是,等式
表达了:对起源于 与 的所有访问路径,存在发生转移的可能。更具体地:
- 若发生转移,则 的所有权转移到 (即 且 );
- 否则不发生转移,所有权保持不变(即 且 )。
最后两个等式
表示:无论(1)还是(2),集合中的访问路径 与 都保留其原有所有权。注意,“” 按照自然数集 上的通常算术加法解释,但我们对每个所有权变量 隐式施加约束
C 语言中的内存泄漏(C Memory Leaks)
在 ASSIGN 规则中,我们向 额外加入约束 ,用于强制 在赋值之前为“非拥有”。反之,若在赋值前 已经拥有所有权,而赋值又让其被重新指向,这就暗示着原始 C 程序中存在一次内存泄漏。由于在 Rust 中,内存会被自动回收,若允许该翻译继续,将会通过修复泄漏而改变原程序的语义。因此,我们的设计选择是:不允许所有权分析产生这种改变语义的解。正如§8 将进一步解释的,我们希望翻译过程保留原先的内存使用行为(包括可能存在的内存泄漏)。
访问路径上的“同时转移”(Simultaneous Ownership Transfer Along an Access Path)
可以注意到,仅靠 ASSIGN 生成的约束并不能完整刻画上节定义的所有权转移规则:它并未显式保证“只要 发生转移,则对所有访问路径 与 上的所有对应指针也同时发生转移”。这一点由所有权单调性隐式保证,如定理 1 所述。
定理 1(所有权转移,Ownership transfer).
若所有权自 转移到 ,则依据 ASSIGN 规则与所有权单调性,所有权也会在访问路径 与 上的对应指针间转移:
(证明见扩展版 [41])
所有权与别名: §5.1 指出,别名可能导致“同一内存对象在转移后有多个所有者”的情况。定理 2 说明在所有权单调性下这不会发生。
定理 2(在所有权单调性下指针赋值的健全性,Soundness).
在所有权单调性下,若所有已分配的内存对象在赋值之前都有唯一所有者,则在该赋值之后也各自仍有唯一所有者。
(证明见扩展版 [41])
直观地,定理 2 的作用是:指针在获取所有权时无需显式考虑别名;发生转移后,这个指针将成为该对象的唯一所有者。这一思想与强更新(strong update)[30] 相呼应。
额外的访问路径(Additional Access Paths)
需要提醒的是: 也可能能被程序中的其它基变量访问。对这些未在赋值处显式出现的访问路径,我们不会为其生成新的所有权变量;因此它们当前的所有权变量按默认保持不变。
所有权转移示例(Ownership Transfer Example)
以下用单链表示例说明 ASSIGN 规则。设 类型均为 *mut Node,需要考虑的四条访问路径为 。采用 SSA 形式时,我们在每行都会为当行出现的访问路径生成新的所有权变量(通过为其下标加 1)。第一次赋值时,可以在 间发生转移;第二次赋值时,可以在 与 间发生转移;而 必须保持原有所有权。
p = q;$O_{p1} = 0 ∧ O_{p2} + O_{q2} = O_{q1} ∧ O_{(*p1).next} = 0 ∧ O_{(*p2).next} + O_{(*q2).next} = O_{(*q1).next} $
(*p).next = (*q).next;$O_{p3} = O_{p2} ∧ O_{q3} = O_{q2} ∧ O_{(*p2).next} = 0 ∧ O_{(*p3).next} + O_{(*q3).next} = O_{(*q2).next} $
条件与循环的处理(Handling Conditionals and Loops)
如§3.2 所述,我们只分析一次循环体,因为这足以暴露所有所需的所有权变量。对归纳定义的数据结构而言,进一步展开循环体虽会延长访问路径,但不会暴露新的结构体字段(结构体字段在循环迭代间并不会改变所有权)。
为处理控制流的汇合点(join points),我们采用 SSA 构造算法的一个变体 [6]:不同路径在 结点处汇合。所有被合并的路径上的每个所有权变量的取值必须一致,否则分析失败。
5.3 解决所有权约束(Solving Ownership Constraints)
所有权约束系统由一组三变量线性约束与一元等式约束组成:三变量线性约束的形式为 ,一元等式约束的形式为 和 。
定义 2(所有权约束系统)
一个所有权约束系统 由以下部分构成:一组取值为 或 的所有权变量 ;一组三变量等式约束 ;以及两组一元等式约束 。其中, 中的等式为 的形式,而 中的等式为 的形式。
定理 3(所有权约束求解的复杂性)
判定定义 2 中所有权约束系统的可满足性是 NP 完全的。(证明见扩展版本 [41])
我们通过调用 SAT 求解器来求解所有权约束。所有权约束可能无解:这发生在不存在同时满足 Rust 所有权模型与“所有权单调性”性质(在某些情形下它比 Rust 模型更严格)的所有权方案,或原始 C 程序本身存在内存泄漏的情况下。若约束存在多个解,我们取 SAT 求解器返回的第一个赋值。
笔者注:NP完全只是一种最坏情况的复杂度结论,并不等于“不可解”,使用SAT只求一个解还是比较容易的。
鉴于 Rust 语义较为复杂,我们并未形式化证明任意可满足赋值都遵循 Rust 的所有权模型。相反,我们在翻译之后通过运行 Rust 编译器来进行该检查。
5.4 关于“所有权单调性”的讨论(Discussion on Ownership Monotonicity)
如第 5 节先前所述,“所有权单调性”比 Rust 语义更为严格,这可能导致我们的分析拒绝一些本会被 Rust 编译器接受的所有权方案。我们识别出两个这样的场景:
(i) 引用输出参数(reference output parameter):
这是指作为函数参数传入的引用,但其行为像“输出”——因为它可以在函数外被访问(例如图 1a 中的 list)。对这类参数而言,基变量是“非拥有”(因为它是引用)且是可变的,而从它可达的指针则可能是“拥有”的(见图 1c 的示例,其中 被赋值为指向新分配节点的指针)。我们能够检测到这类情况并显式地使之可用。具体来说,我们在翻译阶段会把拥有指针 显式转换为 。
(ii) 局部借用(local borrows):
下面这段涉及“可变局部借用”的代码在 CROWN 中被视为无效,因为它违反了“所有权单调性”:赋值之后,local_borrow 是“非拥有”的,而 *local_borrow 却是“拥有”的。
let local_borrow = &mut n;
*local_borrow = Box::new(1);尽管理论上我们可以在翻译时显式处理“局部借用”,但若要健全地这么做,就必须对生命周期信息进行推理(例如,CROWN 需要检查:同一对象的不同可变引用的生命周期之间不存在重叠)。在本工作中我们选择暂不处理,将其留作未来工作(第 7 节“局限性”中亦有提及)。已有研究 [13] 观察到,场景 (i) 的出现频率远高于场景 (ii)。此外,我们在基准中还观察到:输出参数约占 93% 的可变引用(这也解释了 CROWN 中为何加入针对场景 (i) 的特殊处理来启用其翻译)。
笔者注:尚未解决生命周期问题
6. 从 C 到 Rust 的翻译(C to Rust Translation)
CROWN 利用前述所有权、可变性以及“胖指针(fatness)”分析的结果来执行实际的翻译工作,翻译包含两部分:指针重类型化(第 6.1 节)以及重写指针用法(第 6.2 节)。
6.1 指针重类型化(Retyping Pointers)
如第 2.2 节所述,我们并不尝试把数组指针翻译为安全指针。以下内容仅聚焦于可变的、非数组指针。
该翻译需要对指针所有权进行全局视角的把握;而所有权分析本身给出的信息是针对具体程序位置的。出于翻译的目的(并考虑到我们会把“拥有指针”重构为 Box 指针),我们采用如下约定:若某指针在其作用域内的任一程序位置上“拥有”某个内存对象,就将其视为(全局)拥有;否则将其视为(全局)非拥有。
当我们给结构体的指针字段重类型时,必须把整个结构体声明的作用域纳入考虑,这个作用域一般跨越整个程序。在该作用域内,每个字段通常会被多个基变量访问,这些基变量都需要被纳入考量。举例来说,给定图1b 中的 List 声明,以及两个类型为 *mut List 的变量 l1 与 l2。为了确定字段 next 的所有权状态,我们必须考虑所有从 l1 与 l2 这两个基变量出发到达 next 的访问路径。
下表展示了针对可变、非数组指针的重类型规则;为处理空指针的可能,我们将安全指针类型用 Option 包裹:
| 非数组指针 | |
|---|---|
| 拥有(Owning) | Option<Box<T>> |
| 非拥有(Non-owning) | *mut T 或 Option<&mut T> |
被保留为裸指针(*mut T)的那些非拥有指针,对应于可变的局部借用。正如第 5.4 节与第 7 节所解释的,目前 CROWN 尚不能把可变局部借用翻译为安全形式,原因在于我们缺少生命周期分析。需要强调的是,这一限制不适用于输出参数(它们覆盖了大多数可变引用),对这些情况我们会把它们翻译成可变引用。同样由于缺少生命周期分析,我们也无法处理不可变的局部借用,因此本工作的翻译重点放在可变指针上。
笔者注:这些都是未来可以做的内容
6.2 重写指针用法(Rewriting Pointer Uses)
对某个指针表达式的重写取决于它新的类型以及其所处的上下文。例如,在重写赋值语句 中右侧的 时,所采用的重写方式取决于变量 被重类型后的新类型。基于这个新类型,我们区分四类上下文:BoxCtxt(需要 Box 指针)、MutCtxt(需要 &mut 引用)、ConstCtxt(需要 & 引用)以及 RawCtxt(需要裸指针)。例如,若上例中的 被重类型为 Box 指针,那么我们就把 置于 BoxCtxt 中进行重写。
随后,重写按照下表进行:列对应“被重写的指针”的新类型,行对应可能的上下文。
Option<Box<T>> | Option<&mut T> | *mut T | |
|---|---|---|---|
| BoxCtxt | p.take() | ⟂ | Some(Box::from_raw(p)) |
| MutCtxt | p.as_deref_mut() | p.as_deref_mut() | p.as_mut() |
| ConstCtxt | p.as_deref() | p.as_deref() | p.as_ref() |
| RawCtxt | to_raw(&mut p) | to_raw(&mut p) | p |
(表中标记为 ⟂ 的单元格由于我们对输出参数的处理方式而不适用)
我们的翻译依赖于 Rust 标准库中的函数,具体如下:
- 当
Option<Box<T>>处在 BoxCtxt 中时,我们期望发生移动(move);因此使用take将选项中的值取出,并把原位置置为None; - 使用
as_deref与as_deref_mut的目的是不消耗原始的Option值,同时基于其中的引用创建新的Option值; as_mut与as_ref将裸指针转换为引用;Box::from_raw将裸指针转换回Box指针;
此外,我们定义辅助函数 to_raw,用于把安全指针转换为裸指针:
fn to_raw<T>(b: &mut Option<Box<T>>) -> *mut T {
b.as_deref_mut().map(|b| b as *mut T).unwrap_or(std::ptr::null_mut())
}下面以 Box 为例解释 to_raw 的工作原理(对 &mut 的解释相同,因为 as_deref_mut 是多态的):
- 为了把
Option<Box<T>>转为裸指针,我们首先对整个Option进行可变借用,作为辅助函数的可变借用形参。这一步是必要的,因为Option不可拷贝,否则会被消耗; as_deref_mut将&mut Option<Box<T>>转换为Option<&mut T>;map把可选引用中的Some(&mut T)映射为Some(*mut T)(即选项里的引用被转换为裸指针的选项);- 最后,
unwrap_or返回选项中的Some值;若为None,则返回空指针std::ptr::null_mut()。
解引用(Dereferences):当指针 p 作为更大表达式的一部分被解引用时(例如 (*p).next),我们需要额外调用一次 unwrap()。
Box 指针检查(Box pointers check):Rust 不允许在 Box 失去所有权之后继续使用该 Box。由于所有权分析无法捕获这条规则,我们在翻译阶段检测到此类情形时,会将相关的 Box 指针回退为裸指针以避免违规。
为简洁起见,我们省略了对非指针类型结构体字段的(略有不同的)处理方式。
7. 处理真实世界代码的挑战(Challenges of Handling Real-World Code)
我们将 CROWN 设计成能够分析并翻译真实世界代码的工具,但这会带来一系列重大的工程挑战。本节讨论 CROWN 在工程实现上的一些难点以及其当前的局限。
7.1 预处理(Preprocessing)
在对 C 代码库进行“跨语言转译”(transpilation)时,c2rust 将每个文件都视为一个独立的编译单元,并把它翻译成一个单独的 Rust 模块。由此带来的结果是:结构体定义会重复出现,而可用的函数定义会被放进 extern 块中【17】。我们采用与 Laertes 的 resolve-imports 工具【17】相似的预处理步骤,把这些定义在不同文件之间链接起来。
7.2 所有权分析的局限(Limitations of the Ownership Analysis)
有一些 C 语言结构与习惯用法并未被我们的实现完全支持;在这些情形下,CROWN 只能生成部分的所有权约束。CROWN 的翻译策略是:只要有任意约束涉及某变量,我们就尝试对该变量进行重写。其结果是在理论上既非健全(sound),也非完备(complete):它可能生成无法通过编译的代码(不过在 CROWN 能产出结果的基准上我们并未观察到这种情况——见第 8 节),并且它可能把某些指针保留为裸指针,导致翻译次优。下面列举可能出现这种情形的具体场景。
某些不安全的 C 构造(Certain Unsafe C Constructs)。
对类型转换(type casts),我们只为头指针(head pointers)生成所有权转移约束;对 union,我们假定其不含指针字段,因此不生成任何约束;类似地,我们对变参(variadic)实参也不生成约束。我们注意到,union 与变参在某些情况下会导致我们的工具崩溃(例如【17】中的三个基准,详见第 8 节)。出现崩溃的情形包括:分析的访问路径中包含对 union 字段的解引用(而我们此前假定其无指针字段),以及分析向带变参的函数进行调用、且指针作为实参传入的情况。
可变参数示例:
#include <stdarg.h> #include <stdio.h> int sum_ints(int count, ...) { va_list ap; va_start(ap, count); int total = 0; for (int i = 0; i < count; ++i) { // 注意:小于 int 的整数类型会发生“默认整型提升” // 这里用 int 取是安全的(因为 char/short 都已提升为 int) total += va_arg(ap, int); } va_end(ap); return total; } int main(void) { printf("%d\n", sum_ints(5, 1, 2, 3, 4, 5)); // 输出 15 return 0; }
函数指针(Function Pointers)。
CROWN 不会为函数指针生成任何约束。
C 库中的非标准内存管理(Non-standard Memory Management in C Libraries)。
部分 C 库会对 malloc 与 free 做封装,常见做法是借助静态函数指针(指向分配/释放器的指针存放在静态变量中),或把函数指针置于结构体中。对于这种情形,CROWN 不生成任何约束。在 C 中,还可以用一次 malloc 分配一大块内存,然后把它切分为若干子区域,分别赋给不同的指针。在我们的所有权分析中,只有单个指针会因一次对 malloc 的调用而获得那块内存的所有权。另一类我们未完全支持的 C 习惯用法是:某些指针可能同时指向堆上分配的对象,或者静态分配在栈上的数组。CROWN 仅为堆生成所有权约束;因此,这些变量会被欠约束(under-constrained)。
示例(某些指针可能指向堆上对象或栈上数据):
// 约定:如果 take_ownership = true,则函数会在内部保存并在稍后 free; // 如果为 false,则只借用这段内存,绝不负责释放。 void set_buffer(int *p, size_t n, bool take_ownership); void example(bool use_heap) { int *p; size_t n = 1024; if (use_heap) { p = malloc(n * sizeof(int)); // 堆:可转移所有权 set_buffer(p, n, true); // 交出所有权,后续不再 free(p) } else { int local[1024]; // 栈:仅借用 p = local; set_buffer(p, n, false); // 不可转移所有权 // local 作用域一过期,任何延迟使用/释放都会是 UB } }
7.3 CROWN 的其他局限(Other Limitations of CROWN)
数组指针(Array Pointers)。 对于数组指针,尽管 CROWN 能推断到正确的所有权信息,但它不会生成综合 Rust 代码所需的元数据。
可变的局部借用(Mutable Local Borrows)。
如第 6.1 节末段所述,CROWN 不会把可变的非拥有指针翻译为局部可变引用,因为这需要专门的生命周期分析。需要注意的是,CROWN 会为输出参数生成可变引用。
破坏“所有权单调性”的访问路径(Access Paths that Break Ownership Monotonicity)。
如第 5.4 节所讨论,所有权单调性在某些情况下比 Rust 语义更严格;因此这些访问路径会被我们拒绝,尽管它们在 Rust 中可能是被接受的。
8. 实验评估(Experimental Evaluation)
我们将 CROWN 实现在 Rust 编译器之上,使用的编译器版本为 nightly-2023-01-26。我们采用 c2rust 版本 0.16.0。对于 SAT 求解,我们依赖 z3 的 Rust 绑定【20】(版本 0.11.2)。所有实验均在一台搭载 Apple M1 芯片的 MacBook Pro 上进行,8 核(4 性能核 + 4 效率核),16GB 内存,操作系统为 macOS Monterey 12.5.1。
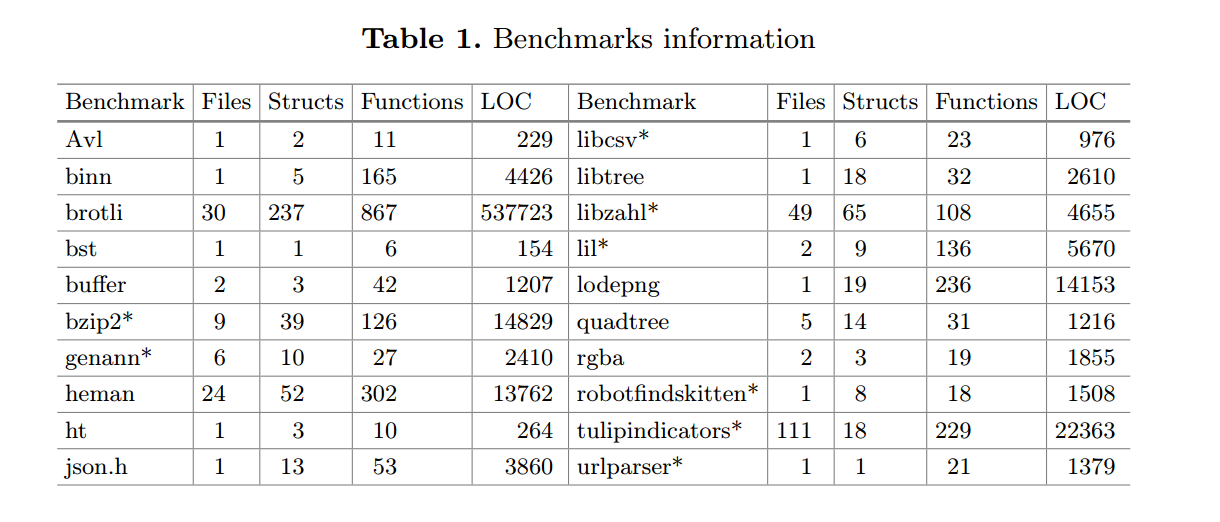
基准选择(Benchmark Selection)。 为评估 CROWN 的实用性,我们收集了由 20 个程序组成的基准套件(见表1)。其中包含 Laertes【17】随论文提供的工件【16】中的基准(表1 中以 * 标记),以及额外的 8 个真实项目(binn, brotli, buffer, heman, json.h, libtree, lodepng, rgba),另加 4 个常用数据结构库(avl, bst, ht, quadtree)。
功能与非功能保证(Functional and Non-functional Guarantees)。
在功能属性方面,我们希望原始程序与重构后程序在观测上等价,即对每个输入产生相同输出。我们使用所有可用的测试集对这一点进行了实证验证(表 1 中的 libtree, rgba, quadtree, urlparser, genann, buffer 等均提供测试)。所有测试在翻译后依然全部通过。
在非功能属性方面,我们期望保持内存占用与 CPU 时间,也就是说不希望翻译引入显著的运行时开销。我们同样使用这些测试集对该点进行了验证。
8.1 研究问题(Research Questions)
我们拟回答以下研究问题:
- RQ1. CROWN 能将多少裸指针/指针用法翻译为安全指针/安全指针用法?
- RQ2. CROWN 的结果与当前最先进方法【17】相比如何?
- RQ3. CROWN 的运行性能如何?
RQ1:不安全指针的减少(Unsafe pointer reduction)。
为评估 CROWN 的有效性,我们测量了裸指针声明与裸指针用法的减少率。这一指标能直接反映安全性的提升,因为即使在 unsafe 区域内,安全指针仍然会被 Rust 编译器检查。正如前文所述,我们聚焦于可变、非数组指针。结果见表2:其中,#ptrs 统计某个基准中裸指针声明的数量,#uses 统计裸指针被使用的次数;表头的 Laertes 与 CROWN 分别给出了两种工具对“裸指针数量”和“裸指针用法次数”的减少率。例如,在基准 avl 中,100% 的减少率意味着所有裸指针声明及其所有用法均被翻译为安全形式。注意,robotfindskitten 这一行中的 “–” 符号是因为该基准没有任何裸指针用法。
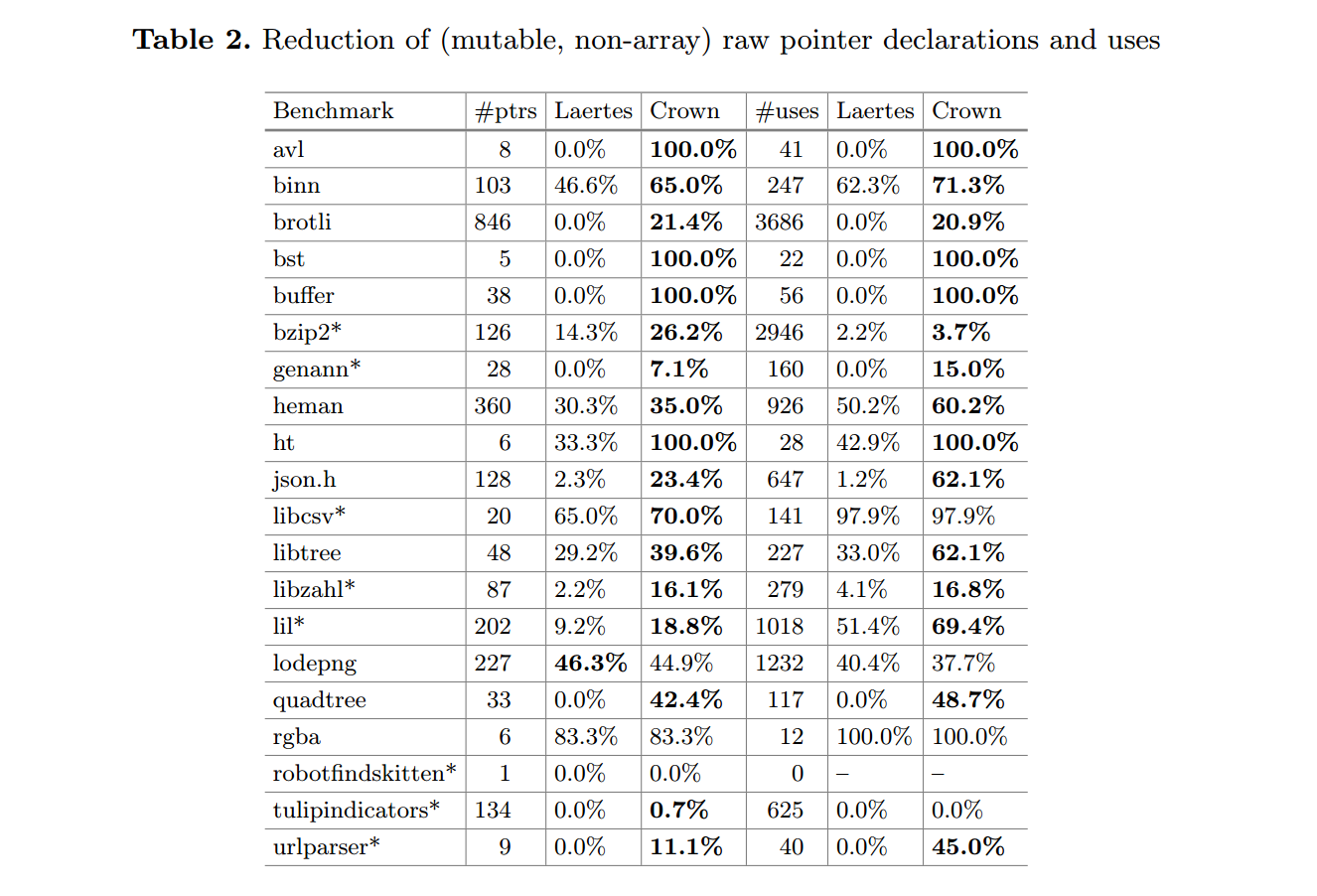
CROWN 在全部基准上的中位减少率为:
- 对裸指针数量:37.3%;
- 对裸指针用法次数:62.1%。
CROWN 在许多非平凡数据结构(avl, bst, buffer, ht)中实现了100% 的减少率,在 rgba 上也表现良好。对于我们体量最大的基准 brotli(由 Google 开发的无损压缩算法),减少率分别为 21.4% 与 20.9%。brotli 及少数其他基准(tulipindicators, lodepng, bzip2, genann, libzahl)的较低减少率,源于它们使用了非标准内存管理策略(详见第 7 节)。
值得注意的是,所有被翻译的基准都能在上述 Rust 编译器版本下成功编译。作为语义保持性的进一步检验,对于提供测试集的那些基准(libtree, rgba, quadtree, urlparser, genann, buffer),我们翻译后的版本全部通过其自带测试。
RQ2:与最先进方法的对比(Comparing with state-of-the-art)。
CROWN 与 Laertes【17】的比较亦见表 2(表中加粗表示更好的结果)。Laertes 的数据或是直接摘自其工件【16】,或经作者私下确认。可以看出,CROWN 在多数情形下优于当前最先进方法(且往往有显著优势)。唯一的例外是 lodepng,我们推测其原因同样与前述非标准内存管理策略有关;而 Laertes 较少受此影响,因为它不依赖所有权分析。
RQ3:运行性能(Runtime performance)。
尽管我们的分析依赖求解一个被证明为 NP 完全 的约束满足问题,但在实际中 CROWN 的运行性能始终表现出较高的效率:对整个基准套件完成“分析 + 重写”的总时间不超过 60 秒(其中对我们最大的基准 brotli 的用时不足 10 秒)。
9. 相关工作(Related Works)
关于所有权的讨论(Ownership Discussion)。
在面向对象(OO)程序设计中,“所有权”常被用来在运行时堆上的对象图之上施加限制,以实现受控的别名共享【11,12】;围绕自动推断所有权信息也有诸多工作【1,4,39】;同时,“所有权”的思想也被用于内存管理【5,42】。类似地,“所有权”概念也被用于分析 C/C++ 程序。Heine 等【24】为了检测内存泄漏而推断指针的所有权信息;Ravitch 等【37】利用静态分析为自动生成库绑定推断所有权。由于应用场景不同,这些工作做出了不同的假设:Heine 等【24】假定间接访问到的指针(例如经由访问路径访问到的任意指针,如 )无法获得所有权;而 Ravitch 等【37】则假定所有结构体字段在未显式注释时默认是拥有的。我们借鉴了【24】对流敏感(flow sensitivity)的处理,但进一步加入了对嵌套指针和归纳定义数据结构的分析——我们发现这对翻译真实世界代码至关重要。【24】中的分析将所有间接访问到的指针一律赋予默认的“非拥有”状态,这排除了许多有趣的数据结构(链表、树、哈希表等)以及常见的习惯用法(例如按引用传参)。相较之下,我们在工作中依赖一个更强的、关于 Rust 所有权模型的假设,从而能够处理上述场景与数据结构。最后,“所有权”的思想也被广泛用于并发分离逻辑【7–9,19,38】,但这些工作并非旨在构建自动的所有权推断系统。
笔者注:所有权在C/C++内存泄漏检测方面也有一席之地; 本文相当于是把一些现有的所有权的方法迁移到c2rust领域;
Rust 形式化验证(Rust Verification)。
以分离逻辑为基础的推理框架 Iris【28】被用于形式化 Rust 的类型系统【27】,并对 Rust 程序进行验证【34】。尽管这些工作覆盖了unsafe 的 Rust 片段,但它们并非全自动。当把推理仅限制在安全 Rust时,RustHorn【35】给出了 Rust 代码行为的一阶逻辑表述,便于进行完全自动的验证;而 Prusti【3】利用 Rust 编译器的信息生成分离逻辑的验证条件,并由 Viper【36】自动消解。在本文中,我们为unsafe Rust 程序提供了一种自动的所有权分析。
类型限定符(Type Qualifiers)。
类型限定符是一种轻量、实用的机制,用于指定与检查那些传统类型系统所不能捕获的性质。通用的、流不敏感(flow-insensitive)的类型限定符框架已被提出【21】;其后续应用包含:分析 Java 引用的可变性【22,25】与 C 的数组边界【32】。我们将这些工作迁移到 Rust,分别用于本文中的可变性分析与胖指针分析。
笔者注:静态程序分析的相关知识运用:引用可变性分析、胖指针分析
从 C 到 Rust 的翻译(C to Rust Translation)。
我们已在前文讨论了 c2rust【26】:这是一款工业级工具,用于把 C 转换为 Rust 的语法。c2rust 并不尝试修复不安全特性(如裸指针),其生成的程序总是带有 unsafe 注解。尽管如此,它仍是其它翻译工作的基础。CRustS【31】通过基于 AST 的代码变换来移除由 c2rust 产生的多余的 unsafe 标注,但它也不会修复不安全特性。Laertes【17】是第一个能够自动减少不安全代码比例的工具:它把 Rust 编译器当作黑盒预言机,并搜索那些移除裸指针的代码修改;这与 CROWN 的方法不同(实验性比较见第 8 节)。后续工作【15】提出了一个评测方法,用于研究把不安全裸指针翻译为安全引用的现有技术的局限性。该工作采用了一个新的“伪安全(pseudo safety)”概念,在此概念下,原始程序的语义保持不再得到保证。正如第 8 节所述,我们的目标是保持语义等价。
10 结论(Conclusion)
我们提出了一种针对由 c2rust 翻译得到的 Rust 程序的所有权分析。该分析具有可扩展性(可在 10 秒内处理50 万行代码)与精确性(能够处理归纳式数据结构),其关键在于我们对 Rust 所有权模型进行了强化,并将其称为“所有权单调性(ownership monotonicity)”。基于这一新的分析,我们实现了一个原型重构工具,用于把 C 程序翻译为 Rust 程序。实验评估显示,所提出的方法能够处理真实世界基准,并在多数情形下优于当前最先进的方法。