Translingual Obfuscation
Translingual Obfuscation
论文来自 2016 IEEE European Symposium on Security and Privacy (EuroSP 2016) 的《Translingual Obfuscation》。
摘要
程序混淆是一种重要的软件保护技术,它可以阻止攻击者揭示程序的编程逻辑和软件设计。我们提出 translingual obfuscation(跨语言混淆),这是一种新的软件混淆方案,通过“误用”某些编程语言的独特特性使程序变得晦涩难懂。跨语言混淆将程序的一部分从其原始语言翻译到另一种具有不同编程范式和执行模型的语言,从而提高程序复杂度并阻碍逆向工程。
在本文中,我们研究了使用 Prolog(一个逻辑编程语言)进行跨语言混淆的可行性与有效性。我们在名为 BABEL 的工具中实现了跨语言混淆,它可以有选择地将 C 函数翻译为 Prolog 谓词。借助 Prolog 语言的两个重要特性,即 unification(统一)和 backtracking(回溯),BABEL 同时对 C 程序的数据布局和控制流进行混淆,使其更难以被逆向工程。
我们的实验表明,BABEL 能提供有效且隐蔽的软件混淆,而其成本相较于当前市场上一款最为流行的商业混淆器仅为温和水平。通过 BABEL,我们验证了跨语言混淆的可行性,并认为这是一条颇具前景的软件混淆新方向。
1. Introduction
混淆(Obfuscation)是软件保护中的一项重要技术,尤其用于防止逆向工程侵犯软件知识产权。一般而言,混淆是一种保持语义不变的程序变换,其目标是让程序更难以理解和逆向工程。利用变换来阻止逆向工程的想法可追溯到 Collberg 等人的工作 [17], [18], [52]。此后已经提出了许多混淆方法 [42], [51], [54], [61], [16], [73]。
当前最先进的混淆技术通常结合进程级虚拟化(process-level virtualization)。例如,诸如 VMProtect [9] 和 Code Virtualizer [4] 之类的混淆器会使用新的字节码替换原始二进制代码,并附带一个自定义解释器来解释和执行这些字节码。其结果是,原始的二进制代码已不复存在,只留下字节码和解释器,使得直接逆向工程变得困难 [35]。然而,最新研究表明,这种基于虚拟化的混淆在“解码—派发”(decode-and-dispatch)的执行模式上存在严重漏洞,可能导致有效的去混淆 [21], [62]。这意味着我们需要基于新方案的混淆技术。
我们提出了一种新颖且实用的混淆方法,称为跨语言混淆(translingual obfuscation),它在安全强度和隐蔽性方面都很出色,同时成本仅为温和水平。其关键思想是:与其发明全新的混淆技术,不如利用某些现有编程语言在设计与实现方面的独特特性来实现混淆效果。一般来说,编程语言的特性很少是专为混淆而提出或开发的;然而,其中一些特性确实使二进制层面的逆向工程更加具有挑战性,因此可以被“误用”(misused)于软件保护。尤其是,有些编程语言采用了独特的范式,并具有非常复杂的执行模型。为了利用这些语言特性,我们可以把用某种语言编写的程序翻译到另一种更“令人困惑”的语言中——这里的“困惑”指的是该语言具备能够引发混淆效果的特性组合。
在本文中,我们通过将 C 程序翻译为 Prolog 来对其进行混淆,给出了一种可行的跨语言混淆方案示例。C 是一种传统的命令式编程语言,而 Prolog 则是典型的逻辑编程语言。Prolog 拥有若干显著特性,能够提供强有力的混淆效果。用 Prolog 编写的程序在一种搜索—回溯(search-and-backtrack)的计算模型下执行,该模型与 C 的执行模型截然不同,且复杂得多。因此,把 C 代码翻译成 Prolog 会导致数据布局与控制流均被混淆。尤其是,Prolog 执行模型的复杂性主要体现在程序的二进制形态上,这使得 Prolog 非常适合用于软件保护。
将一种语言翻译为另一种语言通常非常困难,特别是当目标语言与源语言拥有不同的编程范式时。然而,我们有一个对混淆目的至关重要的观察:语言翻译可以以一种特殊的方式来进行。我们并非要从 C 到 Prolog 做“干净的”(clean)翻译,而是提出一种“混淆式”的翻译方案:它在一定程度上保留 C 的内存模型,使两种执行模型在某种意义上混合在一起。我们认为,这以一种据我们所知此前的混淆方法都未曾达到的方式,提升了混淆效果。
因此,在跨语言混淆中,混淆的来源不仅仅是目标语言本身具有的可混淆特性,也来自于翻译过程本身。借助这一新的翻译方案,我们可谓“一石二鸟”:一方面解决了实现跨语言混淆的技术难题,另一方面又同时增强了混淆强度。
有一种担忧认为,缺乏坚实理论基础的混淆技术,从长远来看难以抵御逆向工程攻击。然而,关于混淆的基础理论研究——尽管近来已有令人鼓舞的进展 [43]、[31]、[59]——尚不足以催生切实可行的保护技术。一个广泛认可的共识是:如果熟练的攻击者投入足够精力审查软件,那么没有任何软件保护方案能够始终保持鲁棒性 [19]。最近证明的一个定理 [12] 在一定程度上支持了这一观点:不存在“普适有效”的混淆器;也就是说,对于任一混淆算法,总存在某个程序使其无法被有效混淆。鉴于此情形,试图开发一种对所有(已知或未知)逆向工程威胁都具有鲁棒性的混淆方案,在当下恐怕过于雄心勃勃。因此,把目标设为 让逆向工程变得更困难(而非不可能) 也许更为现实。
我们在名为 BABEL 的工具中实现了跨语言混淆(translingual obfuscation)。BABEL 可以有选择地将某个 C 函数转换为语义等价的 Prolog 代码,并把两种语言的代码一起编译为可执行形式。实验结果表明,跨语言混淆具有较强的晦涩性与隐蔽性。与商用混淆器相比,BABEL 的运行时开销适中。我们还展示了跨语言混淆能够抵御当下最流行的某类逆向工程技术。
总而言之,本文的贡献如下:
- 我们提出了一种新的混淆方法,即跨语言混淆。其新颖之处在于:它利用目标语言中非常规/异质的语言特性来对抗逆向工程,而不是依赖临时性的程序变换。与现有混淆技术相比,我们的方法具备多方面优势,后文将深入讨论。
- 我们在名为 BABEL 的工具中实现了跨语言混淆:在子程序尺度上将 C 翻译为 Prolog(即从 C 的函数到 Prolog 的谓词),以对原始程序进行混淆。语言间的翻译本就具有挑战性,尤其当目标语言拥有异构的执行模型时更是如此。
- 我们按照 Collberg 等人提出的四项评估标准 [18]——强度(potency)、抗性(resilience)、成本(cost)与隐蔽性(stealth)——在一组真实世界且具有相当复杂度与多样性的 C 程序上对 BABEL 进行了评测。实验表明,BABEL 以适中的成本提供了强有力的逆向工程防护。
论文结构如下: 第 §2 节从高层视角介绍跨语言混淆的洞见与特性;第 §3 节详细解释为何 Prolog 语言可被“误用”来进行混淆;第 §4 节总结实现跨语言混淆过程中遇到的技术挑战;第 §5 和 §6 节分别给出我们的 C→Prolog 翻译方法与 BABEL 的实现细节;第 §7 节评估 BABEL 的性能;第 §8 节讨论与跨语言混淆相关的一些重要议题;随后第 §9 节综述相关工作;第 §10 节对全文进行总结。
2. 跨语言混淆(Translingual Obfuscation)
2.1 概述(Overview)
跨语言混淆的基本思想是:某些编程语言比另一些更难被逆向工程。直观地看,C 语言相对容易被逆向,因为由 C 程序编译得到的二进制代码与源码共享同样的命令式执行模型。然而,对某些编程语言(例如 Prolog)来说,源码与其产出的二进制之间存在更深的鸿沟,因为这些语言在抽象层面上与底层硬件的命令式执行模型根本不同。基于这一洞见,我们从软件保护的视角分析并评估一种“外来”编程语言的特性。同时,我们还开发了一种翻译技术,将原始语言转换为承担混淆职责的目标语言。只有把这些工作都做到位,跨语言混淆才能成为一种切实可行的软件保护方案。
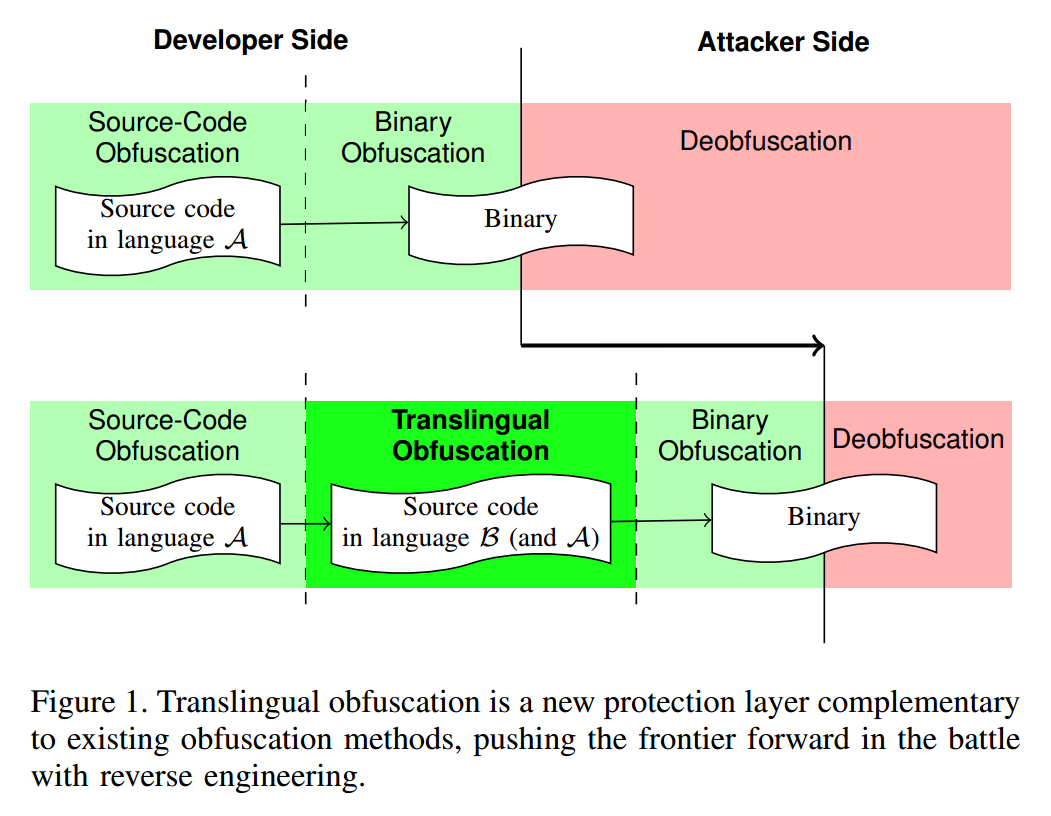
我们将跨语言混淆视为在“混淆—去混淆军备竞赛”中的新一层软件保护,如图1所示。与以往的方法不同——往往要么在二进制层工作,要么在同一种语言内做源到源变换——跨语言混淆是把一种语言翻译成另一种语言。因此,它既可以在源码混淆之后、又能在二进制混淆之前应用,而不会影响现有混淆方法的适用性。
2.2 与基于虚拟化的混淆对比(Comparing with Virtualization-Based Obfuscation)
基于虚拟化的混淆是当前二进制混淆的前沿做法。跨语言混淆的某些特征与其理念相近,但我们想强调一个重要差异。目前,多数虚拟化混淆的实现倾向于:用类似 RISC 的虚拟指令集对原生机器码进行编码,并在decode-dispatch(解码—分发)模式下解释执行被编码的二进制 [63]、[56]、[33]。然而,这种模式已被指出具有显著的安全弱点,并可能被多种攻击所利用 [62]、[21]、[75]。
与之不同,跨语言混淆的安全强度主要来自有意地依赖目标外语中天然有助于混淆的语言特性——这些特性源自其异质(heterogeneous)的编程模型。本质上,只要所采用的外语支持编译为本机代码,跨语言混淆就无须对原始二进制进行重新编码。图2 展示了两种方法之间的关系和关键差异。需要指出的是,我们的跨语言混淆实现 BABEL 与基于虚拟化的混淆并不重叠。
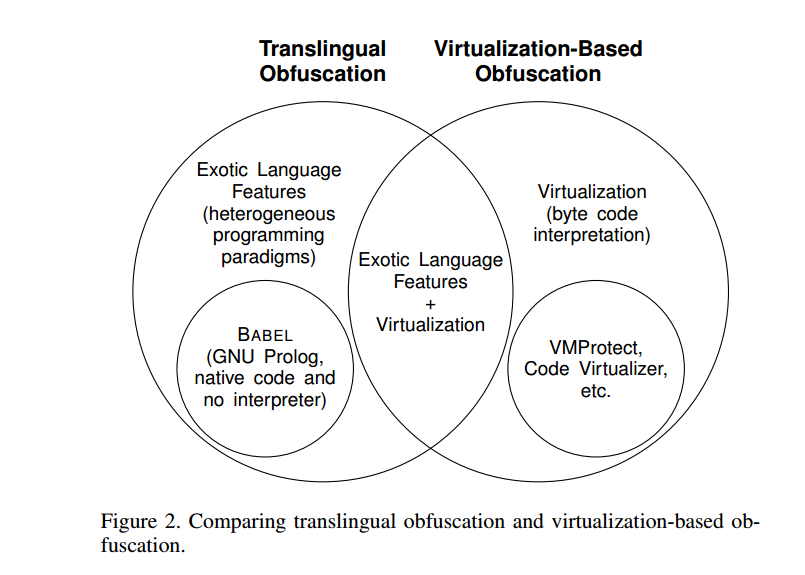
2.3 益处(Benefits)
据我们所知,跨语言混淆带来的若干优势,是以往任何单一混淆方法都难以同时实现的:
更强的混淆强度与多样性。 跨语言混淆通过引入不同的编程范式来提升混淆效果与手段的多样性。若存在一种通用且自动化的方法,能够完全抵消此类混淆的作用——也就是抵消由某种编程语言的执行模型所引入的额外程序复杂度——那就意味着可以显著简化该语言的设计与实现;而对于已经成熟的语言而言,这几乎不可能。
更高的隐蔽性(stealth)。 现实开发中采用多语言编程完全合规且常见;相比之下,基于虚拟化的混淆会把本机代码编码成一种非常规格式的字节码,容易在统计特征上留下异常。跨语言混淆既不会引入异常的字节熵,也不会产生偏离常态的指令分布。
框架而非单一算法。 跨语言混淆不仅是一种具体算法,更是一套通用框架。尽管本文重点利用了 Prolog,但还有其他语言也可被“误用”来实现跨语言混淆。例如,ML 的新泽西实现(SML/NJ) [10] 甚至没有运行时栈:它把所有活动记录与闭包都分配到由垃圾回收管理的堆上,这可能让程序分析更加困难。再如 Haskell,一种纯函数式语言,具有惰性求值特性 [41],其实现可采用与传统命令式计算截然不同的执行模型 [46]。
综合以上优势,我们相信:跨语言混淆有望成为软件保护的一条新方向。
3. 将 Prolog“误用”于混淆(Misusing Prolog for Obfuscation)
本节我们对 Prolog 编程语言做一份简要介绍,并解释为何以及如何“误用”其语言特性来实现混淆。
3.1 Prolog 基础
Prolog 的基本构造单元是项(terms)。无论是 Prolog 程序本身,还是其操作的数据,都是由项构成。项分为三类:常量、变量与结构。
常量可以是数(整数或实数),也可以是原子(atom)。原子是通用名字,类似于其他语言中的常量字符串。
结构项的形式为 ,其中 是一个符号,称为函子(functor), 是其子项。函子的参数个数称为元数(arity)。允许同一个符号以不同元数出现,因此在提及一个结构项时常用记号“”。
当结构项被赋予语义后,就成为子句(clauses)。子句可以是事实(fact)、规则(rule)或查询(query)。如果一个子句的体为空,它就是事实;否则为规则。
例如,parent(jack,bill). 是一个事实,表示“jack 是 bill 的父母之一”。而一个规则可以是:
grandparent(G,C) :- parent(G,P), parent(P,C).该规则可写成以下一阶逻辑公式:
具有相同名称且参数个数相同的若干子句共同定义了一个关系,亦即谓词(predicate)。在给定事实与规则之后,程序员可以发出查询,交由 Prolog 的归结系统求解。延续上例,一个查询可以是 grandparent(G,bill),其语义就是“谁是 bill 的祖辈?”。
一个 Prolog 程序就是一组项。Prolog 的归结引擎在程序执行期间维护一个内部项数据库,并试图以逻辑推理的方式用事实和规则来解决查询。本质上,Prolog 中的计算被归约为一个搜索问题。这与常见的图灵机计算模型不同;但逻辑编程的理论基础保证了 Prolog 具有图灵完备性 [64]。
3.2 有助于混淆的语言特性(Obfuscation-Contributing Features)
3.2.1 合一(Unification)
自动逻辑归结(也即逻辑编程)的核心概念之一是合一。从本质上看,它是一种模式匹配技术。两个一阶项 与 ,若存在某个替换 能使它们相同,即 ,则称二者可合一。
例如, 与 可通过替换 、 而被合一。
合一是 Prolog 计算模型的基础之一。看如下示例。下面这个子句定义了一个“加一”的过程:
inc(Input, Output) :- Output is Input + 1.当对其发起查询 inc(1, R) 时,Prolog 归结引擎首先尝试把 inc(1,R) 与 inc(Input,Output) 合一——这意味着 Input 应当与 1 合一,而 Output 应当与 R 合一。一旦该合一成功,原始查询就被归约为子目标 Output is Input + 1。由于此时 Input 已与 1 合一,表达式 Input + 1 被求值为 。最后,Output 再与 合一(is/2 是“求值并合一”的算子/谓词),从而使 R 也与 合一。
为支持合一,Prolog 将项以有向无环图(DAG)的形式实现。每个项由一个 二元组表示,其中 tag 指示该项的类型,而 content 则是常量的值或变量所合一到的项的地址。图 3 展示了 Prolog 在内存中表示一个项的示例 [11]。
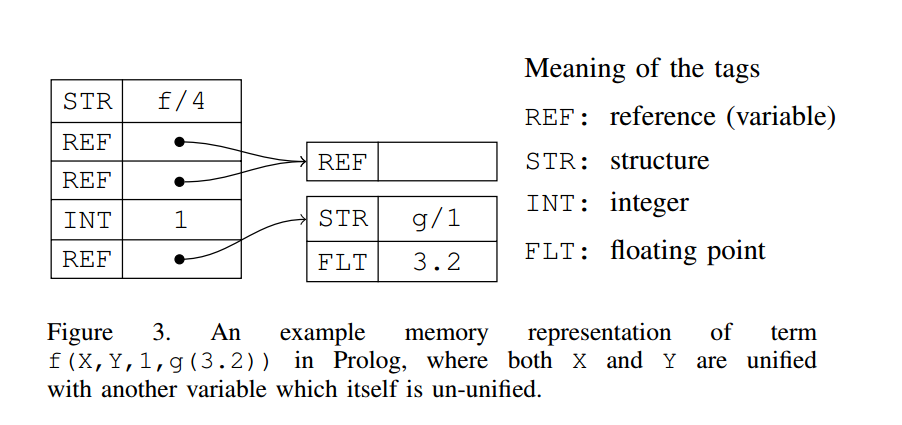
图 3:项 的一个内存表示示例,其中 与 都与另一个尚未合一的变量合一。
tag 的含义:
- REF:引用(变量)
- STR:结构
- INT:整数
- FLT:浮点数
合一使得 Prolog 程序中的数据形状(data shapes)与 C 等语言截然不同,且更加难以理解。合一的图结构实现对二进制数据形状分析提出了巨大挑战——这类分析旨在从二进制程序的内存镜像中恢复高层数据结构 [36]、[32]、[58]、[22]。即使识别出部分图结构,低层次表示与原始数据的逻辑组织之间仍存在显著鸿沟,对攻击者的逆向分析能力构成严苛考验。
合一还会让数据访问变得更复杂:为了获得某变量的真实值,Prolog 引擎必须遍历整个合一链表。众所周知,静态分析对循环与间接内存访问是脆弱的。此外,项二元组中的 tag 往往以位域形式编码,这意味着需要位级(bit-level)分析算法才能揭示由 Prolog 代码编译得到的二进制的语义。然而,由于可扩展性等问题 [60]、[38]、[26]、[74],在静态与动态程序分析中实现位级精度本身就是一项重大的技术挑战。
3.2.2 回溯(Backtracking)
不同于主要混淆程序数据的 Prolog 合一机制,回溯特性会混淆控制流。回溯是 Prolog 归结机制的一部分。前文已述,给一个可归结的公式寻找解,本质上是在寻找一个合适的合一器(即一次替换),从而把经替换后的公式展开为只由事实与已知为真的其它公式构成。由于某个合一问题实例往往可能有多个解,归结过程就有可能以某种方式把两个项合一,从而使之后对公式的求解变得不可行。于是,Prolog 需要一种从错误证明路径回滚的机制,这就是回溯。
为了使回溯成为可能,Prolog 在从多个搜索分支中选择一个之前,会保存程序状态。这份被保存的状态被 Prolog 称为选择点(choice-point),其思想类似于函数式编程中的续延(continuation)。当沿着某条路径的搜索失败时,归结引擎会恢复最近的选择点,并继续搜索尚未尝试的其它分支。

这种“搜索—回溯”的执行模型,使得 Prolog 程序在低层级上的控制流组织,与采用相同逻辑书写、但使用 C 语言实现的程序截然不同。图4 给出了一个示例:某个 C 函数被我们的工具 BABEL 转换为 Prolog 子句(我们对生成代码做了少量人工整理以便阅读),并与该函数在 BABEL 转换前后的执行流一并展示。需要说明的是,Prolog 版本函数的真实控制流远比图示更为复杂,为便于阅读我们对流程图做了大幅简化。
在图4 的 Prolog 部分中,一旦执行流进入谓词 pfoo(它是两个子句的析取),就会立即创建一个选择点。Prolog 的归结过程首先尝试满足第一个子句;若失败,便回溯到最近的选择点,再去尝试第二个子句。
由于回溯模型复杂,Prolog 中相当大一部分控制流迁移是间接的。其实现还涉及长跳转、栈展开等技术。显而易见,从静态分析的角度看,Prolog 的低层执行模型要比 C(以及一般意义上的命令式编程)更为晦涩。与某些通过注入伪控制流(这些流在运行时从不可能达成)来混淆控制流的方法不同,Prolog 的回溯真实发生在程序执行期间,这也让跨语言混淆对动态分析同样具有鲁棒性。更重要的是,经过 C→Prolog 翻译后,原先的 C 控制流将被重新塑造为一种完全不同的编程范式,这从根本上区别于现有的、以控制流为中心的混淆技术。
4. 技术挑战(Technical Challenges)
为了利用 Prolog 的执行模型来混淆 C 程序,我们需要一种翻译技术,将 C 函数“锻造”为其在 Prolog 中的对应体。在这一过程中,需要解决多方面的挑战。
4.1 控制流(Control Flow)
作为一种命令式编程语言,C 通过诸如 continue、break 与 return 等关键字,为构造程序控制流提供了极大的灵活性。相较之下,Prolog 程序必须遵循逻辑公式的通用求值过程,这从根本上禁止了一些在 C 中允许的“花式”控制流。
4.2 内存模型(Memory Model)
在 C 编程中,许多底层细节对程序员并非不可见。就内存操作而言,C 程序员可以通过指针访问几乎任意的内存位置;而 Prolog 缺乏表达直接内存访问的语义。
此外,C 的内存模型还与语言的其他子结构(例如类型系统)紧密耦合。C 的类型不仅是逻辑抽象,而且对数据的底层内存布局具有直接影响。举例来说,在 C 的数组中逻辑上相邻的元素在物理内存上也相邻;在 C 的结构体中相邻字段在物理内存上同样相邻。因此,对 C 数据结构的一些逻辑操作可以实现为直接内存访问——而这些实现只在 C 的内存建模下才与源语义等价。下面是一个示例:
struct ty {
int a;
int b;
} s[2];
/* 等价于 s[0].a = s[0].b = s[1].a = 0;
* (在许多编译器与体系结构上成立)*/
memset((void*)s, 0, 3 * sizeof(int));将上述代码片段直接翻译为纯 Prolog是困难的,因为翻译器必须推断出 memset 语句背后的逻辑效应。
4.3 类型转换(Type Casting)
C 语言的类型转换极其灵活:C 程序员可以将任何类型强制转换为任何其他类型,无论这种转换在语义上是否“合理”。这种灵活性可以通过破坏“存—取一致性(load–store consistency)”来实现——也就是说,先把某种类型的变量值存入某个内存位置,随后再把同一段内存中的内容以另一种类型读出。C 的 union 类型为这类打破存—取一致性的类型转换提供了高级支持;当然,C 程序员也可以直接使用指针达到同样的效果。对其他语言而言,仿真这种类型转换体系往往是个显著挑战。
5. C→Prolog 翻译(C-to-Prolog Translation)
本节说明我们如何解决上一节提及的那些挑战。
5.1 控制流规整化(Control Flow Regularization)
关于精炼 C 程序控制流已有大量研究,特别是关于消除 goto 语句的工作[39][55][70]。在本文中,我们把 goto 消除视为一个已解决的问题,并假定需要保护的 C 程序不包含 goto。
笔者注:这都能假定?
在给定一个不含 goto 的 C 函数时,仍有两种控制流模式无法被 Prolog 直接采用:其一是控制流切断(cuts),其二是循环(loops)。我们将这些模式统称为不规则控制流(irregular control flows)。
5.1.1 控制流切断(Control Flow Cuts)
控制流切断指的是在一个 C 函数的中间提前终止控制流,例如:
int foo (int m, int n) {
if (m)
return n; // if 分支在此结束
else
n = n + 1;
n = n + 2;
return n; // else 分支在此结束
}C 语言在构造控制流方面给予程序员很大自由度,即便没有 goto 语句也能做到。
而在 Prolog 中,控制流必须遵循逻辑表达式的短路求值规则来“布线”:并列语句用析取连接,顺序语句用合取连接。
为了说明仅靠短路规则无法实现上面 C 代码的控制流模式,考虑一个函数,其函数体形如:. 按直觉,它会被翻译成 Prolog 句子
,其中“”表示蕴含,“;”表示析取,“,”表示合取。
但是该翻译不保持语义:当 是 return 语句时,如果子句 被求值,那么 与 中至少需要一个被继续求值,以便确定整个逻辑公式的真值——这与原始 C 语义相悖。
我们的做法是:在切断点之后,通过复制与/或重排基本块,来消解控制流切断。对上面的示例,重写为:
int foo (int m, int n) {
if (m)
return n;
else {
n = n + 1;
{ n = n + 2; return n; }
}
}修订后,该 C 代码即可自然翻译为新的 Prolog 子句
,与原始 C 语义一致。
5.1.2 循环(Loops)
大多数循环无法在 Prolog 中直接实现。根本原因是:Prolog 不允许对同一个变量进行多次合一。
我们可将循环改写为递归函数来处理这一点,但循环体内部的不规则控制流会让情形复杂化。其不规则性主要来自关键字 continue 与 return 的使用。
continue 会在循环中途切断控制流,带来与前述函数内非对称返回类似的问题。因此,由 continue 导致的不规则控制流也可用同样方式规整化,即在 continue 之后对基本块进行复制与/或重排。
与 continue 类似,return 在循环中同样切断控制流;但它的影响会越出循环本身,因为它切断的是包含该循环的函数的控制流。于是,由循环改写得到的递归 Prolog 谓词需要额外的实参来携带一个标志,指示“是否在循环体内发生了 return”。
5.2 C 内存模型的模拟(C Memory Model Simulation)
如第 §4 所述,C 的内存模型与该语言的其它部分高度耦合,难以割裂。不过,跨语言混淆保留了原始 C 内存模型,这让保持语义等价容易得多。
我们的设计是:将 Prolog 运行时嵌入 C 的执行环境中,使 Prolog 代码得以在程序的地址空间内直接操作内存。
我们对 C 内存模拟的处理方式,体现了为混淆而做语言翻译的优势。与那些追求“从 C 完整翻译到另一种语言”的工具不同,跨语言混淆不需要用目标语言特性完整模仿C 的内存(例如把 C 指针转换成 Java 的引用 [23])。这意味着我们可以降低翻译复杂度并规避不少限制。
尽管如此,即便只部分地在 Prolog 中模拟 C 的内存模型,仍然不是一件琐碎的工作。
5.2.1 支持 C 的内存访问操作符(Supporting C Memory-Access Operators)
模拟 C 内存模型的第一步,是支持指针操作。我们在目标 Prolog 语言中引入如下新子句:
rdPtrInt(+Ptr, +Size, -Content)
wrPtrInt(+Ptr, +Size, +Content)
rdPtrFloat(+Ptr, +Size, -Content)
wrPtrFloat(+Ptr, +Size, +Content)这些子句由 C 实现。rdPtrInt/3 与 rdPtrFloat/3 允许我们把某个内存单元(其地址与大小由 Ptr 与 Size 给定)的内容读入一个 Prolog 变量 Content。类似地,wrPtrInt/3 与 wrPtrFloat/3 可以把某个 Prolog 变量的内容写入一个内存单元。上述四个子句模拟了 C 中指针解引用(*)操作符的行为。
除了“从指针读/向指针写”,C 还有取地址操作符(&):它以一个左值为操作数(即一个会被分配存储位置的表达式),并返回其关联的存储位置,也就是内存地址。在 Prolog 中无需显式支持这个操作符,因为 C 中任一左值的地址在编译期都有静态表示,编译器可知。我们可以在 C 运行环境中获得“取地址”操作的结果,并把这些数值作为实参传入 Prolog 环境。
我们还处理了若干与内存访问相关的 C 语法糖:下标([])以及取字段(. 与 ->)。我们把这些操作符转换为等价的“指针算术 + 解引用”的组合,从而无需在 Prolog 中再去“发明”对应操作。本转换需要基于对编译器实现与目标体系结构的合理假设来计算类型大小与字段偏移。
5.2.2 保持一致性(Maintaining Consistency)
一个顺理成章的方案是:在 C→Prolog 翻译中,将每个 C 变量映射到一个对应的 Prolog 变量。但 Prolog 不允许变量更新。我们通过把 C 代码转换到接近 SSA(静态单赋值) 的形式来克服这个限制:变量只在程序的某一处被初始化,之后不再更新。在严格的 SSA 形式中,即使作用域彼此不相交,变量也只能静态初始化一次。Prolog 不需要这么做,因为语言在运行时会检查再次合一:这意味着变量可以在互斥执行的程序部分中被更新,例如同一个 if 语句的 then 与 else 分支。因此,在我们的 SSA 转换里,无需实现 函数。
SSA 转换可以通过变量重命名来实现。难点在于:仅仅对原始 C 代码做变量改名,可能会因为内存操作引发的副作用而破坏程序语义——也就是,在不通过变量名的情况下依然可以访问变量内容。这正是我们先前讨论过的“一致性问题”。图 5 展示了该问题的一个例子。

为了解决这一问题,我们会在局部变量与形参有可能通过指针被访问时,保留它们的地址。随后,在执行一次“从指针读”操作之前,我们把变量内容回刷(flush)回内存;在执行一次“向指针写”操作之后,我们再把变量内容回装(reload)进来。
我们也会考虑过程间的指针解引用:当被调函数以指针作为实参时,我们在函数调用之前执行变量回刷,在函数返回之后执行变量回装。回刷确保由 Prolog 代码引起的更改提交到下层的 C 内存,以便后续读取能看到这些更改;回装确保与 Prolog 逻辑变量合一的那些值始终与 C 内存中的内容一致。
我们进行一种指向集分析(points-to analysis),以便在每个程序点上计算需要回装或回刷的变量集合。插入这些回刷/回装操作之后,SSA 的变量重命名将不再破坏原程序语义。图 6 基于图 5 的示例给出了我们的解决方案。

5.3 支持 C 的其他特性(Supporting Other C Features)
5.3.1 结构体、共用体与数组(Struct, Union, and Array)
在第 §4 节我们已经表明:像 struct 与 array 这样的 C 数据类型可以通过内存访问来操纵。既然我们已在 Prolog 中构建了对 C 内存模型的支持,那么最初的挑战如今就转化为:如何“顺带”支持 C 的 struct、union 与 array。做法很直接:仅对原始 C 代码做变换,让所有涉及结构体、共用体和数组的操作都经由指针来完成。完成这一步之后,Prolog 提供的原始数据类型就足以表达任意 C 数据结构。
5.3.2 类型转换(Type Casting)
在我们的 C 内存模拟方法下,通过指针完成的类型转换无需额外工作——即便这些转换会破坏存—取一致性。对于显式的类型转换(例如从整数到浮点),我们使用 Prolog 内置的类型转换子句,如 float/1。
5.3.3 外部与间接函数调用(External and Indirect Function Call)
库函数的源码通常不可得,因此将其翻译成 Prolog 并不现实。通常,跨语言混淆的翻译可以借助外部语言接口支持对外部子程序的调用。就 C+Prolog 混合的混淆而言,多数 Prolog 实现都提供了从 Prolog 环境调用 C 函数的接口;同样的接口也可用于通过指针间接调用函数。
5.4 混淆性的翻译(Obfuscating Translation)
我们的翻译方案充分利用了 §3.2 中介绍的“有助于混淆”的语言特性,主要体现在:
- 从 C 的数据结构到 Prolog 的数据结构的转换是默认发生的,并且每一个 C 赋值都会被翻译为 Prolog 的合一。
- 原本在 C 中过程内的控制流迁移,现在由 Prolog 的回溯机制实现,这会显著复杂化生成二进制的低层逻辑。
尤其需要强调的是:我们在 Prolog 中支持 C 内存模型的方法。高层来看,翻译后沿用原始 C 的内存布局;但 C 侧内存的行为会与原程序大不相同。为了维持 C 侧内存与 Prolog 侧“逻辑内存”的一致性,我们引入了回刷—回装(flush–reload)方法,它会打乱内存访问的时序。因此,被混淆程序的内存占用轨迹将不再与原程序执行时一致。
我们相信,这套翻译方法是促使跨语言混淆同时对语义驱动与语法驱动的二进制对比(binary diffing)保持鲁棒性的关键因素之一(参见 §7.2)。
6. BABEL 的实现(Implementation of BABEL)
BABEL 是我们的跨语言混淆原型。其工作流包含三步:C 代码预处理、C→Prolog 翻译以及 C+Prolog 编译。
第一步(预处理)会重整原始 C 源码,使其适合逐行翻译到 Prolog。第二步把 C 函数翻译为 Prolog 谓词。最后一步,BABEL 通过精心设计的接口把 C 与 Prolog 代码组合编译。
我们选择 GNU Prolog [24] 作为 Prolog 实现。与许多 Prolog 系统一样,GNU Prolog 先把 Prolog 源码编译成“标准 Warren 抽象机(WAM)”指令 [69];更让我们受益的是:GNU Prolog 还可以把 WAM 代码继续编译成本机码。这使 BABEL 与那些基于虚拟化的混淆工具(把原程序编译成字节码并在自定义虚拟机上执行)区别更为显著。
6.1 预处理与 C→Prolog 翻译(Preprocessing and Translating C to Prolog)
在把 C 实际翻译为 Prolog 之前,需要先对 C 代码做预处理。我们借助 CIL 库 [53] 完成以下步骤:
- 将 C 代码简化为三地址形式:不含
switch语句与三目条件表达式; - 将循环转换为尾递归函数;
- 消除控制流切断;
- 把对全局变量、结构体、共用体与数组的操作转换为指针操作;
- 在必要处执行变量回刷与回装;
- 消除除指针解引用以外的所有内存操作符;
- 重命名变量,使 C 代码形式接近 SSA。
完成预处理后,我们即可逐行把 C 翻译为 Prolog(翻译规则见图 7)。需要注意的是:当开始翻译时,预处理后的 C 代码中已经没有 switch 与循环语句——它们要么被转换为嵌套的 if 语句,要么被转换为递归函数。正如 §5.1 所述,我们也不考虑 goto 语句。

我们把算术与逻辑表达式的翻译视为相对“琐碎”的工作,但这也带来一个局限:由于 Prolog 不细分整数类型,其整数算术并不与 C 的严格等价。
例如,给定两个 C 变量 x、y 都是 int(4 字节),表达式 x + y 在 Prolog 中的等价形式理应写成 (X + Y) & 0xffffffff,其中 与 分别是 x、y 的对应逻辑变量。
因此,若某个 C 程序有意依赖整数的溢出/下溢行为,我们的翻译在少数情况下可能失效。不过,完全仿真 C 语义会带来显著的性能代价。
笔者注:也就是说整数溢出行为和C语言不一致
此前很多把 C 翻译到其他语言的工作也遇到同样问题,且不少工作选择忽略它 [15]、[48]、[66]。例如 C→JavaScript 的转换器 Emscripten 提供了完全仿真 C 语义的选项 [76],并配有一组启发式方法来推断在哪些程序点需要做完全仿真;但该方法无法保证始终正确。我们在实现 BABEL 时并未特别处理这个问题。不过,我们预期 BABEL 的翻译失败概率很低,原因在于:
- Prolog 侧使用写指针(write-to-pointer)操作;
- 采用了变量回刷—回装机制。
写指针操作会显式给出数据大小,因此每当整数变量被回刷或回装时,都会自动触发截断。在 64 位平台上的 GNU Prolog 中,所有整数都以61 位的二进制补码表示(另外 3 位被 WAM 标签占用),这足以容纳大多数实际的整数与指针值。
6.2 组合 C 与 Prolog(Combining C and Prolog)
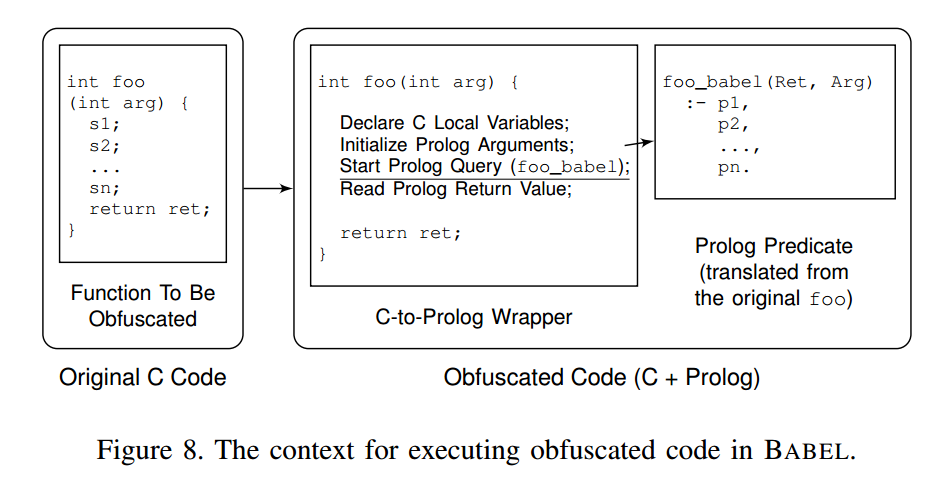
BABEL 将 C 与 Prolog 的运行时环境组合在一起,程序从执行 C 代码开始。当执行遇到一个已被混淆的函数(此时它是一个包装器,用于发起对相应 Prolog 谓词的查询)时,包装器会在求值 Prolog 谓词之前完成上下文设置:
- 包装器分配若干局部变量,这些变量的地址会在预处理后的 C 函数中被引用;
- 随后,包装器把这些地址连同函数实参一起,通过 GNU Prolog 提供的 C→Prolog 接口传递给目标 Prolog 谓词。
图 8 示意了两种语言如何在该体系中被组合。
6.3 定制 Prolog 引擎(Customizing Prolog Engine)
尽管 GNU Prolog 具备一些优点,使其大体上适合作为 BABEL 的实现基础,但它仍然不能完全满足我们的需求,因此需要定制。一个显著问题是:其从 C 调用 Prolog 的接口不是可重入的。这点很关键,因为按设计,BABEL 的用户可以自由选择他们要混淆的函数。为了支持这种自由度,通常无法避免出现交错着 C 与 Prolog 子程序的栈回溯。我们发现,这一不可重入的问题源自整个 GNU Prolog 引擎中使用了全局的 WAM 状态。我们的修复方法是:维护一个栈,在每次新的 C→Prolog 接口调用之前保存 WAM 状态,并在调用结束后恢复该状态。
另一个问题是:GNU Prolog 没有实现垃圾回收,因此内存占用可能迅速膨胀。这个问题并没有看起来那么严重,因为我们无需在程序整个生命周期为 Prolog 运行时维护一个堆。由于我们知道所有 Prolog 变量的生命周期都受其谓词作用域约束,当执行过程中没有挂起的 Prolog 子程序时,我们可以安全地清空 Prolog 堆。GNU Prolog 把堆实现为一个大的全局数组,并用堆顶指针标记使用量,因此只需把堆顶指针重置到堆数组的起始位置就能清空堆,效率很高。
笔者注:这个清空内存的方式很不错啊,值得借鉴
7. 评估(Evaluation)
Collberg 等人 [18] 提出从四个维度评估混淆技术:强度(potency)、抗性(resilience)、成本(cost)与隐蔽性(stealth)。
- 强度衡量程序被混淆后变得多么晦涩与复杂;
- 抗性表示被 BABEL 混淆的程序抵御逆向工程(尤其是自动去混淆)的能力;
- 成本衡量混淆带来的执行时开销;
- 隐蔽性衡量在给定混淆后二进制的情况下,识别出混淆存在的难度。
我们据此对 BABEL 进行评估,以观察其在这四项标准上的表现。
笔者注:对混淆的评估标准可以学这个
为证明我们的工具能有效保护不同类别的真实软件,我们把 BABEL 应用于六个开源 C 程序,这些程序已被广泛部署多年甚至数十年。其中四个是 CPU 密集型应用,两个是 IO 密集型服务器。
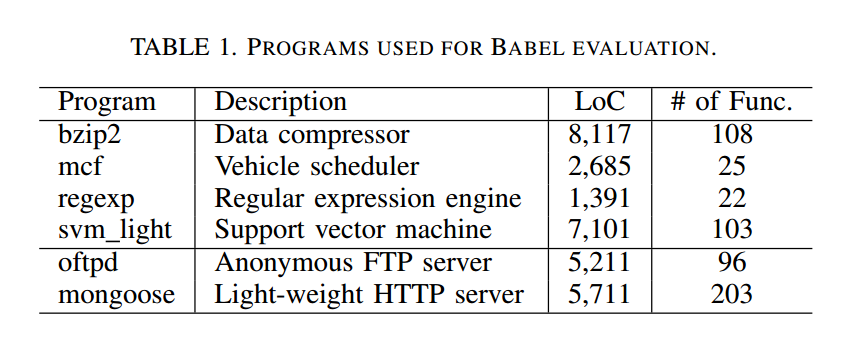
CPU 密集型应用包括:代数变换(bzip2)、整数运算(mcf)、状态机(regexp)与浮点运算(svm_light);两个 IO 密集型服务器覆盖最常用的两种网络协议:FTP(oftpd) 与 HTTP(mongoose)。我们认为该选择具有代表性,覆盖了广泛的真实软件场景。表1 给出了这些程序的细节。
我们将混淆级别(obfuscation level)定义为:一个 C 程序中被混淆的函数比例。
例如,“20% 混淆级别”的 bzip2 实例指:其源代码经编译后,80% 的函数仍为 C,而其余 20% 的 C 函数被 BABEL 翻译为 Prolog 谓词。所有混淆级别均通过在可被 BABEL 混淆的函数集合中随机选择候选来实现——需注意,这种随机选择只是为了避免研究中的主观挑选偏差。在实践中,BABEL 的用户应自行决定哪些函数是关键且需要保护的。这与主流的商业虚拟化混淆工具的使用方式相同 [4]、[9]。
在评估中,我们把 BABEL 与最流行的商业混淆器之一 Code Virtualizer(CV) [4] 进行对比。CV 基于虚拟化,自 2006 年起投入市场。对比覆盖四个评估维度;不过,我们为 BABEL 设计的一些评测方法未必适用于 CV。对于我们认为不适合用于 CV 的评测,我们会解释原因,并提示读者在解读这些数据时应保持审慎。
7.1 强度(Potency)
我们使用两组静态度量来展示 BABEL 向被混淆程序注入了多少复杂性。
第一组是关于调用图与控制流图(CFG)的基础统计量,包括两类图中的边数以及基本块数量。这些度量在相关工作中已被用于评估混淆技术 [16]。
除基础统计外,我们还计算了历史软件工程研究中用于量化程序复杂度的两项指标:圈复杂度(cyclomatic number)[49] 与 结数(knot count)[71]。这两项指标呼应了 Gilb 的观点:逻辑复杂度是衡量系统决策程度的一种方法 [34],并且也常用于评估混淆效果 [18]。
圈复杂度定义为 ,其中 与 分别为 CFG 中的边数与结点数。直观地,它代表程序中决策点的数量 [20]。
结数是指在把所有结点按一条直线排布、并把所有边画在同一侧时,CFG 中边的交叉数量。
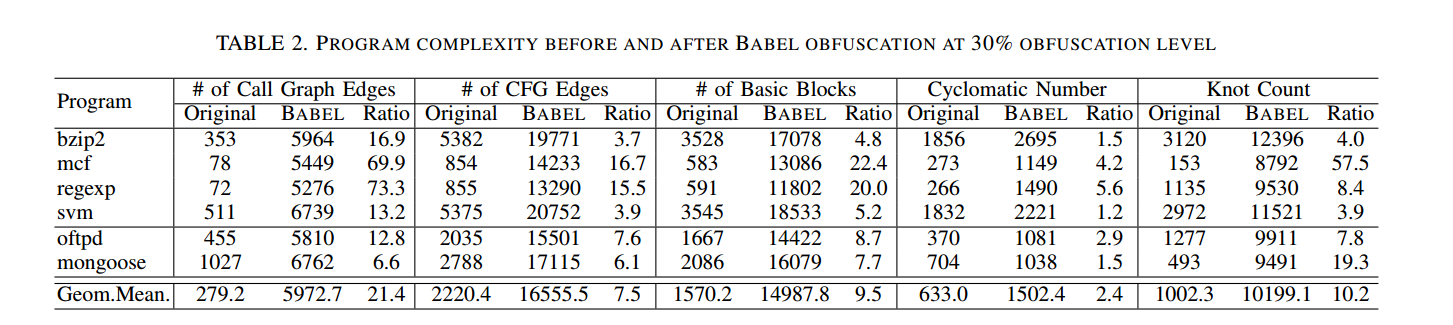
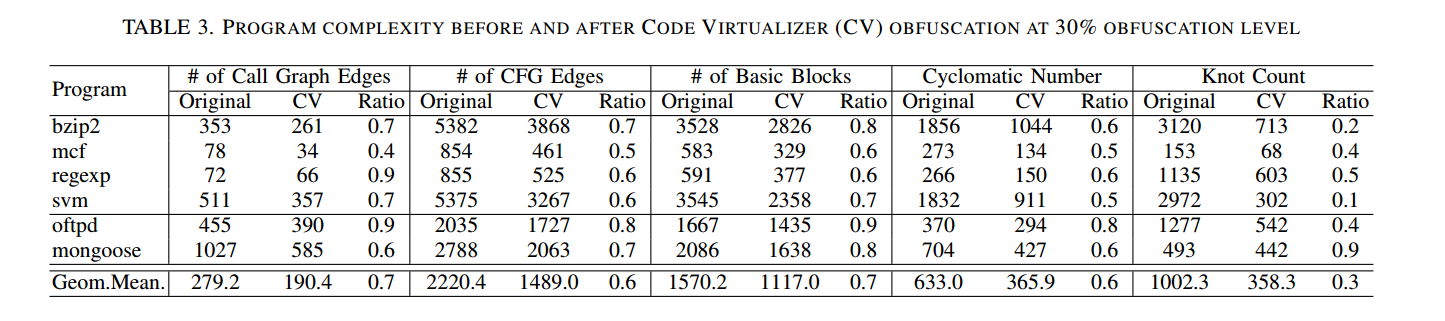
表2 对比了我们所选六个程序在30% 混淆级别下,应用与不应用 BABEL 混淆时的复杂度度量。为了保守起见,在测量时我们剔除了 GNU Prolog 运行时自身的代码,因此任何额外复杂性(若存在)都应完全归因于 BABEL 的混淆。
我们使用高级商业逆向工具 IDA Pro [6] 反汇编二进制并生成调用图与控制流图。可以发现被混淆二进制在所有度量上都显著增加。对六个程序几何平均的结果表明,BABEL 能显著提升程序复杂度。需要注意的是,与那些使用不透明谓词产生静态复杂度的方法不同,BABEL 注入的额外控制流分支在运行时都是可达的“真实”分支。
我们的强度评估并不适合用来测量 Code Virtualizer 的相同维度。原因在于:Code Virtualizer 会把二进制指令转换为字节码,而我们使用的逆向工具(IDA Pro)无法处理这种情况。表 3 以与表 2 相同的方式给出了有/无 Code Virtualizer 混淆的二进制复杂度。数据表明,在应用 Code Virtualizer 后,被保护二进制的复杂度显著下降,这实际上是前述局限的结果——由于 IDA Pro 无法分析被重新编码的函数,强度评估不可避免地遗漏了相当一部分复杂度。
7.2 抗性(Resilience)
总体而言,评估一种混淆技术的抗性并不容易,因为逆向工程往往是一个临时性/经验性的过程;另一方面,面向公众的实用去混淆工具非常少。由于这些困难,一些以往的软件混淆研究未能恰当地评估抗性。在我们的评估中,经过充分调研,我们选择使用二进制差异(binary diffing)来评估 BABEL 的抗性——当然,这并不意味着binary diffing 是唯一的去混淆技术。
二进制差异是常用的逆向技术,用于计算两个二进制之间的相似度。我们把它视作一种去混淆方法,因为它揭示了被混淆程序与其原始版本之间的联系。给定一个程序及其被混淆版本,如果 binary diffing 工具(忽略可能的假阳性)对二者给出很高的相似度分数,某种意义上就表明diff 工具成功“抵消”了混淆效果。我们所知的大多数历史去混淆研究都使用基于相似度的度量来评估其技术的有效性 [62]、[21]、[75]。
二进制相似度可基于语法或语义来计算。
- 语法主要指二进制的控制流;语法型 diffing 通常采用图论方法:比较两个二进制的调用图,并进一步比较两者中成对函数的 CFG,寻找图或子图同构。直觉是:如果两个二进制的调用图相似,那么位于同构图中对应结点的函数也很可能相似;如果两个函数的控制流相似,它们很可能实现了相同的计算逻辑。
- 语义型 diffing 则关注二进制的可观察行为。描述程序行为的方式有多种,例如给定代码块的前/后置条件、以及代码造成的某些效果(如系统调用)。若两个二进制表现出匹配的行为,语义型 diff 工具会认为它们相似。
一般而言,语法相似度比语义相似度更宽松:语法型 diff 往往更容易出现假阳性,而语义型 diff 往往更容易出现假阴性。为尽可能避免评估中的偏见,我们同时选择两类 diff 工具来测试 BABEL 的抗逆向性:
- CoP [44](语义型二进制 diff 工具),
- BinDiff [2](语法型 diff 工具)[65]。
为衡量 BABEL 对 diff 工具的抗性,我们从表 1 中每个程序随机选取 50% 的函数,用 BABEL 进行混淆,然后用上述 diff 工具计算原始与混淆后函数之间的相似度。
7.2.1 面向语义的二进制比对的抗性(Resilience to Semantics-Based Binary Diffing)
CoP 是一种“对语义型去混淆具有鲁棒性”的二进制相似性检测器 [44],当前属于语义型二进制差异工具的前沿代表。CoP 的检测算法基于“语义等价基本块的最长公共子序列”这一概念。
通过构造符号公式来描述基本块的输入/输出关系,CoP 使用定理证明器检查两个基本块的语义等价性。已有报道指出,这种新的二进制比对技术能够击败多种传统混淆方法。CoP 构建在多个逆向领域的前沿技术之上,包括二进制分析工具包 BAP [14] 与约束求解器 STP [29]。CoP 定义的相似度分数为:匹配到的基本块数量 / 原函数全部基本块数量。
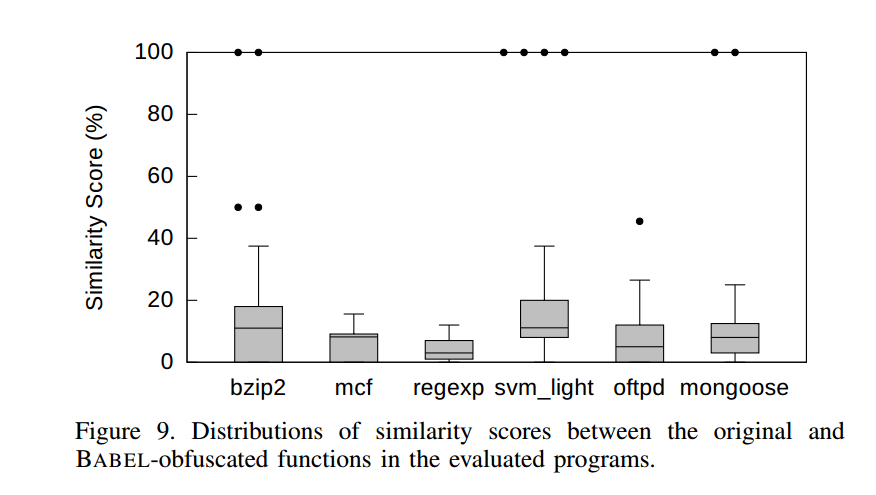
图9 给出了相似度分数分布的箱线图。对所有程序而言,第三四分位数都低于 20%。考虑到 CoP 原始论文在大多数经过变换/混淆的程序上报告的相似度超过 70%,我们从 BABEL-混淆函数计算得到的这些分数并不足以支持“高度相似”的结论。
需要注意,图9 中存在少量离群点(某些函数的相似度可达 100%)。这些函数都是“简单”的:仅包含一个基本块与极少的 C 代码行数。在假阳性存在的情况下,按照 CoP 的相似度定义,二进制比对器对这类函数给出 100% 的相似度很有可能。
7.2.2 面向语法的二进制比对的抗性(Resilience to Syntax-Based Binary Diffing)
BinDiff 是一种闭源的语法型二进制差异工具,事实上已成为工业标准并被广泛使用;它也推动了若干学术二进制比对器的诞生,如 BinHunt [30] 及其后继 iBinHunt [50]。
给定两个二进制,BinDiff 会基于一组不同算法输出被认为相似的函数对。除相似度分数(类似 CoP 的报告)外,BinDiff 还会给出结果的置信度,即该分数源自哪一类算法。我们并不完全清楚 BinDiff 各算法的工作细节以及它如何分级置信度。因此,我们报告的指标是:不论相似度与置信度如何,只统计被 BinDiff 正确匹配到原函数的混淆函数数量。这样可以避免 BABEL 在性能评估中获得任何不公平优势;换句话说,这些结果可视为 BABEL 对语法型二进制比对的抗性下界。
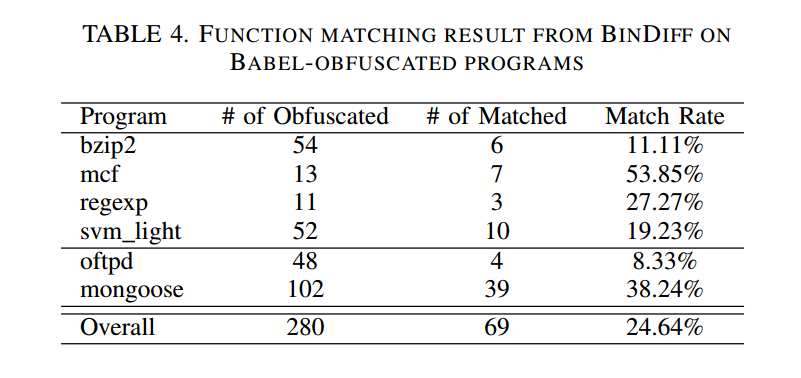
表4 展示了各程序中被匹配到的混淆函数数量(其中一些匹配的相似度或置信度较低)。由于 BinDiff 仅凭函数在调用图中的坐标就能进行匹配,即便语义完全不同的两个函数也可能被匹配上。这解释了为什么 BinDiff 在 mongoose 上获得相对较高的匹配率:它拥有最多的函数数目,且调用图可能更具标识性。
尽管如此,在六个程序上被 BinDiff 匹配到的混淆函数仅占 26.22%。需要强调的是,“被匹配”并不意味着成功完成去混淆或恢复程序逻辑,尤其对于语法型差异工具而言。在这个意义上,我们认为 BABEL 的表现是令人满意的。
7.2.3 与 Code Virtualizer 的比较(Comparing BABEL with Code Virtualizer)

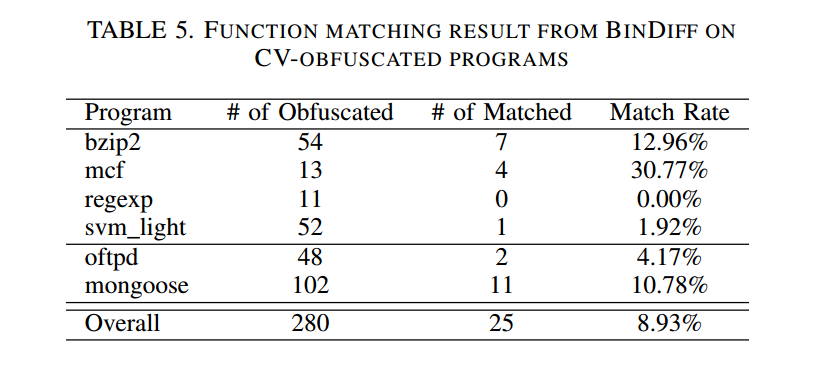
我们在图10 与表5 中分别给出了 Code Virtualizer(CV) 对 CoP 与 BinDiff 的抗性。实验设置与对 BABEL 的抗性评估保持一致。数据表明,就 CoP 与 BinDiff 而言,CV 似乎比 BABEL 更具抗性。然而,正如在强度评估中已提到的,对基于虚拟化的混淆器(如 CV)进行逆向需要专门的方法。由于 CoP 与 BinDiff 都未意识到“被混淆的二进制部分已从代码转变为数据”的事实,它们的较差表现并不意外。
归根结底,虚拟化混淆的一项主要弱点在于:虽然原程序可能被很好地混淆了,虚拟机本身仍暴露在攻击之下。一旦攻击者逆向虚拟机逻辑并揭示字节码的编码格式,就能有效地对受保护的二进制进行去混淆 [62]、[75]。
7.3 成本(Cost)
我们测量 BABEL 在不同混淆级别(10%~50%)下引入的执行减速。对 CPU 密集型应用,我们使用程序自带的测试用例作为性能输入;对 FTP 服务器 oftpd,我们顺序传输 10 个文件,大小从 1KB 到 128MB;对 HTTP 服务器 mongoose,我们连续发送 100 次对一个 2.5KB HTML 页面的请求。实验环境为:Xeon E5-1607 3.00GHz CPU、4GB 内存、Ubuntu 12.04 LTS(64 位),经由 1Gbps 以太网连接。每项测试运行 10 次,报告平均减速。对服务器而言,网络通信耗时也计入测量。
与强度和抗性不同,我们可以较容易地对 BABEL 与 Code Virtualizer 的运行时开销做公平对比。在对比中,我们将 Code Virtualizer 配置为最小化混淆强度、最大化执行速度。这种设置的含义是:若 BABEL 能达到可比或更好的性能,则其引入的运行时开销对于实际使用应是可接受的。为表明我们混淆的函数并非微不足道,我们使用 gprof 获得它们的性能覆盖率,即这些被混淆函数在原程序执行中占用的 CPU 时间百分比。需要注意,这个百分比只是下界:因为一些函数可能被内联,其时间会被 gprof 计入其它函数。我们仅对四个 CPU 密集型应用得到覆盖率数据,因为两款原始服务器程序的 CPU 时间都过短,不足以做有意义的剖析。服务器程序的分析通常需要专门的性能分析器,而我们并不了解适用于这两款服务器的此类工具。
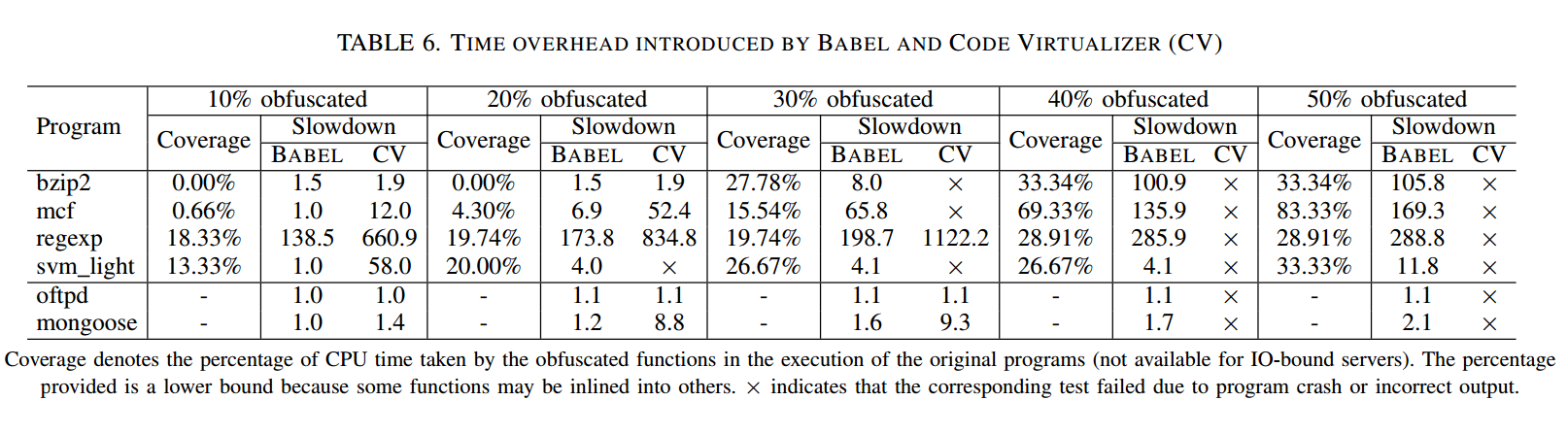
表6 给出了实验结果,显示 BABEL 在多数测试中优于 Code Virtualizer。尤其是,BABEL 的混淆更可靠:被混淆程序正常退出并对测试输入给出正确结果;而在多数被测程序中,当混淆级别达到 40% 时,Code Virtualizer 无法提供可靠的混淆。对于许多 CPU 密集型应用,当混淆级别达到 30% 后,BABEL 与 CV 都会带来相当高的性能开销。这是意料之中的,因为一般应避免对热点代码施加重量级混淆 [7]。在我们的评估中,许多应用在混淆级别达 50% 时覆盖率超过 30%;而若要在实践中部署 BABEL 或 CV,这种情况并不常见。无论如何,本节的要点是:BABEL 的性能成本低于一个与其理念相近的、工业级的混淆器。
7.4 隐蔽性(Stealth)
隐蔽性评估旨在调查 BABEL 是否会给被混淆代码引入异常的统计特征。在本评估中,我们选择 30% 的混淆级别。
有些既往工作使用程序二进制的字节熵来衡量混淆的隐蔽性 [73];字节熵也被用于检测加壳与加密二进制 [45]。由于 BABEL 不会重新编码原始二进制代码,仅凭“字节熵正常”并不能有力证明其隐蔽性。因此,我们采用另一种统计特征——指令分布——来评估 BABEL;该度量在先前工作中也被采用过 [54]、[16]。
为了判断 BABEL 混淆后的程序是否具有异常的指令分布,我们需要把它们与正常程序比较。鉴于我们的评估规模相对较小,我们选取 SPEC2006 基准作为正常程序的代表。我们把常见的 x86 指令划分为 27 类,计算每类在 SPEC2006 程序中的百分比均值与标准差。由于整数与浮点程序的分布不同,我们仅将 bzip2、mcf、regexp、oftpd、mongoose 与 SPECint2006 做比较。
图11 展示了整数程序的对比。对大多数指令类别,BABEL-混淆程序的分布都落在“正常均值 ± 正常标准差”的区间内。也存在少数例外(如 mov、call、ret、cmp 与 xchg),但它们仍受 SPEC 分布的上下界约束(图中未示出)。因此我们认为,这些例外不足以得出“BABEL-混淆程序在指令分布上异常”的结论。
与此同时,被 Code Virtualizer 混淆的二进制,在指令分布上呈现出显著更大的偏离(见图 12)。需要指出,当我们尝试反汇编由 Code Virtualizer 处理过的二进制时,反汇编器报告了数百个解码错误,推测是因为 CV 将合法指令转换为字节码,而反汇编器无法正确解码。不过,这种反汇编异常本身也可被视为混淆的强烈证据。总体而言,实验表明 BABEL 的隐蔽性优于 Code Virtualizer。
或许有人担心:仅仅存在 Prolog 运行环境就可能成为“混淆存在”的证据。对此可以通过定制 Prolog 引擎来缓解。既往研究表明,一个 Prolog 引擎用不到 1000 行的 Pascal 或 C 代码即可实现 [37]、[72]。
8. 讨论(Discussion)
8.1 推广跨语言混淆(Generalizing Translingual Obfuscation)
虽然把一种语言的程序翻译到另一种语法、语义与执行模型都大不相同的语言通常很有挑战,但当翻译的目的只是用于混淆、不要求“完整可替代”时,许多障碍是可以绕开的。在我们从 C→Prolog 的翻译中,我们把支持 C 内存模型这一(在 C 翻译中最具挑战的)任务,部分地转交给了C 的执行环境本身来完成。此方案并不适用于通用目的的语言翻译。与此同时,我们的一些翻译技术对一类具有某些相似性的目标语言是普适的。比如,我们提出的控制流正规化方法在把 C 翻译到许多声明式编程语言时都可以采用。我们相信,跨语言混淆有潜力被打造成支持多种源/目标语言的通用框架。
8.2 多线程支持(Multithreading Support)
我们当前的 BABEL 实现不支持 C 的多线程。主要原因在于 GNU Prolog 的某些组件非线程安全。由于 GNU Prolog 面向研究与教育用途,某些语言特性未被支持。然而,许多更成熟的 Prolog 实现可以很好地支持多线程[8]。投入足够的工程努力,我们应当能够改进 GNU Prolog 的实现,并确保它支持并发编程;因此我们不把当前限制视为根本性问题。
8.3 随机性(Randomness)
一些混淆技术通过引入随机性来增强安全性。例如,虚拟化型混淆器通常会随机化其虚拟指令集的编码[28],使攻击者不能仅凭学习单个实例的编码就破解所有被随机化的二进制。尽管一旦攻击者学会了系统化逆向虚拟机的方法,这种随机化会失效,但随机化的思路仍然有价值。
我们当前的跨语言混淆设计没有明确内置随机性。不过,跨语言混淆与既有混淆技术正交,它可以与那些引入随机性的技术叠加。跨语言混淆本身也有潜力具备随机性。其中一个有前景的方向是:让某些外语编译策略具有不确定性。先前研究表明,改变编译配置可以有效干扰部分去混淆工具[27]。
笔者注:随机性一直是一个很重要的思路
8.4 如何对抗跨语言混淆(Defeating Translingual Obfuscation)
一般而言,跨语言混淆是开放式设计,不依赖任何秘密(当然也可以与其他基于秘密的混淆方法组合)。我们关于跨语言混淆安全强度的所有论证都假设攻击者知道我们把 C 翻译到了 Prolog。确实,掌握这点知识后,攻击者可以选择先把二进制转换回 Prolog,再回到 C;无论哪条路线,攻击者都会遭遇严峻挑战。
需要再次强调的是,我们并不声称跨语言混淆无法被破解;我们的观点是:在跨语言混淆语境下,Prolog 比 C 更难破解。只要 BABEL 翻译得到的 Prolog 谓词被编译为本机代码,把它恢复成高层程序表示将要面对 C 逆向工程的所有困难,包括反汇编与分析的艰难[68]。在 §3 中我们揭示了 Prolog 源代码与其低层实现之间巨大的语义落差。受益于这层落差,我们预计:想要恢复由 Prolog-化的 C 源代码编译得到的本机代码中的计算逻辑,将消耗可观的逆向工程工作量。
进一步增加难度的是:被混淆代码并不是“普通 Prolog + 普通 C”的简单拼接,而是二者交缠的混合物。被混淆程序在执行过程中会频繁地在两种语言环境间切换,并在不同内存模型之间交替(见 §5),这同样会给逆向带来挑战。
还有一点使跨语言混淆有潜力显著拖慢逆向攻击:正如 §2.3 所述,跨语言混淆并不局限于 Prolog。还有许多其他编程语言也可被“挪作他用”来提供保护。把这些语言混合到同一套混淆流程中,会进一步提升逆向工程的难度。
9. 相关工作(Related Work)
9.1 程序语言翻译(Programming Language Translation)
人们寻求把一种编程语言翻译为另一种语言,尤其是源到源的翻译,目的包括可移植性、再工程以及安全性。将 C/C++ 翻译为 Java 是该领域研究最为广泛的主题之一,催生了诸如 C2J [40]、C++2Java [3]、Cappuccino [15] 等工具。Trudel 等[66] 开发了一个将 C 翻译为 Eiffel(另一种面向对象语言)的转换器。Emscripten 可以把 LLVM 中间表示翻译为 JavaScript [76]。由于 C/C++/Objective-C 源代码可以被编译成 LLVM 中间表示,Emscripten 也能在无需太多额外工作的情况下充当源到源的翻译器。
本文提出的 C→Prolog 翻译是不完整/部分性的,因为我们需要保留原始的 C 执行环境;然而,我们的翻译用于软件混淆,这种“部分性”并不构成限制。相反,我们表明:就我们的目的而言,编程语言翻译中常见的许多技术问题都可以被解决或绕开。
笔者注:当时(2016)把程序翻译引入代码混淆的领域的idea很新
9.2 混淆与去混淆(Obfuscation and Deobfuscation)
软件混淆可以发生在源代码层或二进制层。在源代码混淆方面,Sharif 等[61] 使用依赖输入数据并结合单向哈希函数的加密相等条件;评估表明,用符号执行几乎不可能推断出哪些输入能满足该相等条件。Moser 等[51] 证明了不透明谓词能够有效地把控制转移目的地与数据位置隐藏起来,从而躲避高级恶意软件检测技术。
面向混淆的程序变换也可在二进制层进行。Popov 等[54] 通过以异常处理替代控制转移、在异常处理代码中实现真实的控制转移、以及在异常之后插入冗余的垃圾转移,来对程序进行混淆。Mimimorphism[73] 把一个恶意二进制伪装成一个仿真善意程序,使其统计与语义特征与目标极为相似,从而使被混淆的恶意软件能够成功规避统计异常检测。Chen 等[16] 提出了一种控制流混淆方法,利用 Itanium 处理器在信息流追踪方面的体系结构支持;具体地,他们使用 Itanium 寄存器中的延迟异常标记来实现不透明谓词。Domas[25] 开发了一个编译器,仅使用 mov 指令家族即可生成二进制,基于的事实是 x86 mov 具备图灵完备性。
还有一些二进制混淆方法严重依赖压缩、加密与虚拟化 [35]、[47]、[57]。其中,压缩/加密壳可能易受动态分析的影响,因为原始代码必须在某个执行点被还原。至于虚拟化型混淆,当前多数方法采用解码-分派(decode-dispatch)方案 [63]。近期工作 [56]、[62] 已识别出此类虚拟化混淆二进制中解码-分派模式的特征,从而能对其进行有效逆向。
关于去混淆,近期多数工作聚焦于攻击虚拟化混淆。Sharif 等[62] 提出了一种由外到内(outside-in)的方法:先逆向虚拟机,再解码字节码以恢复被保护程序。Coogan 等[21] 则提出了由内到外(inside-out)的方法,使用等式推理来简化被保护程序的执行轨迹,从而提取与程序逻辑真正相关的指令。Yadegari 等[75] 近期改进了 inside-out 方法,提出了更通用的控制流简化算法,能够对嵌套虚拟化保护的程序进行去混淆。由于我们无法获得这些工具,不能直接测试 BABEL 对它们的抗性;不过,由于 BABEL 完全重构了 C 程序的数据布局并以截然不同的编程范式改造了控制流,我们对 BABEL 在面对这些方法时的安全强度持有信心。
二进制差异是另一类广泛使用、会考虑程序混淆的逆向技术。该类工具识别两个不同二进制在语法或语义上的相似性,可用于检测编程抄袭以及发起基于相似度的攻击[13]。我们用于评估 BABEL 抗性的 BinDiff[2] 与 CoP[44] 是当前最先进的代表。其它二进制比对器还包括 DarunGrim2[5]、Bdiff[1]、BinHunt[30] 与 iBinHunt[50]。尽管这些工具能击败某些类型的程序混淆,但没有一个是为应对跨语言混淆的复杂性而设计的。
10. 结论(Conclusion)
本文提出了跨语言混淆:一种基于将程序从一种语言翻译到另一种语言的新型软件混淆方案。通过利用目标语言的某些设计与实现特性,我们能使原程序抵御逆向工程。我们实现了 BABEL,一个把 C 程序的部分翻译为 Prolog 的工具,并借助 Prolog 独特的语言特性使程序更加晦涩。我们从强度、抗性、成本与隐蔽性四个维度,对一组真实世界的 C 程序(类别各异)进行了评估。实验结果表明:跨语言混淆是一种足够有效且切实可行的软件保护技术。
Citations
Diversification and obfuscation techniques for software security: A systematic literature review
Information and Software Technology(2018)、CCF B
Layered obfuscation: a taxonomy of software obfuscation techniques for layered security
Cybersecurity(2020)、CCF C
Challenging machine learning-based clone detectors via semantic-preserving code transformations
TSE 2023、CCF A
Wobfuscator: Obfuscating javascript malware via opportunistic translation to webassembly
SP 2022、CCF A
MBA-Blast: Unveiling and Simplifying Mixed Boolean-Arithmetic Obfuscation
USENIX Security Symposium (SECURITY)(2021)、CCF A