RustSan: Retrofitting AddressSanitizer for Efficient Sanitization of Rust
RustSan: Retrofitting AddressSanitizer for Efficient Sanitization of Rust
论文收录于第33届 USENIX Security Symposium(USENIX Security ’24,CCF A) 的会议论文集,链接:https://www.usenix.org/conference/usenixsecurity24/presentation/cho-kyuwon。
摘要
Rust 正在作为一种安全的系统编程语言迅速普及,凭借其强类型与内存安全保证而受到关注。然而,Rust 的保障并非牢不可破。使用 unsafe Rust(Rust 的一个子变体)时,程序员可以暂时跳出 Rust 严格的语言语义,以安全换取灵活性;但 unsafe 代码块中的内存错误会对程序安全造成深远影响。因此,传统的动态内存错误检测(如模糊测试 fuzzing)已成为 Rust 生态中的常见实践,并通过不断披露的 CVE 战果证明了其有效性。
RustSan 是对 AddressSanitizer(ASan)的“改造式”设计,用于高效检测 Rust 程序中的动态内存错误。我们的观察是:将 ASan 编译插桩到 Rust 程序后,许多被插桩的内存访问点在 Rust 语义保证下实际上是冗余的,即这些位置的内存安全在语义上仍然成立。RustSan 的做法是:识别并仅对那些必然或可能破坏 Rust 安全保证的位置进行插桩,同时在安全位置移除插桩。为此,RustSan 采用跨 IR 的程序分析,以精确追踪 unsafe 位置,并扩展了 ASan 的影子内存方案,用于检查 Rust 所需的非均匀内存访问(non-uniform memory access)验证机制。我们在 57 个 Rust crate 上,对 RustSan 的检测能力与性能进行了全面评估。RustSan 成功检测出 31 个实际 CVE 案例中的全部内存错误。在通用基准中(20 个 crate),相较 ASan,RustSan 的性能平均提升 62.3%。在对 6 个 crate 的模糊测试实验中,RustSan 的平均性能提升 23.52%,最高可达57.08%。
1. 引言
Rust 作为一种实用的安全系统编程语言正日益受到欢迎。它通过严格的编译期规则与轻量的运行期检查来保证内存安全。许多新项目已将 Rust 作为主要编程语言(例如文献 [2, 4–8, 17, 21, 41])。此外,Linux 内核中对 Rust 基础设施的纳入 [2] 也是 Rust 持续被广泛采纳的里程碑事件。
然而,这些安全保证并非没有代价。Rust 通过施加严格的语言语义,要求程序员与之“合作”。借此,语言设计与程序员共同产出能够被编译器与最小化运行时检查所验证的代码。Rust 的安全模型在某些需要精细化掌控的场景里可能过于严格。为此,Rust 提供了一个变体 unsafe Rust,它存在于使用 unsafe 关键字声明的代码块中。与在 Rust 中被禁止的行为相比(例如原始指针访问、绕过严格的所有权检查 [9]),unsafe 允许不受限制地访问这些语言语义。在某些程序中(例如与低层组件交互),或当程序员为了灵活性而选择以安全换取效率时,使用 unsafe 往往是不可避免的。
先前的研究已经考察了在 Rust 中使用 unsafe 的常见实践,以及在 Rust 程序中使用 unsafe 的影响 [22, 56]。这些工作发现:在 Rust 程序中,几乎所有内存错误都源自 unsafe Rust 的使用 [56]。作为回应,研究者提出了用于发现 Rust 内存错误的静态分析方法 [14, 26, 36, 37],以及在运行时将安全 Rust与不安全 Rust隔离的方案 [15, 31, 33, 38, 45]。
静态分析方法在检测高度复杂的缺陷或仅在运行时暴露的问题方面能力有限。运行时隔离框架为识别 Rust 程序中不安全的子程序集合、以保护安全 Rust 部分奠定了基础。运行时隔离是遏制影响而非直接检测来自 unsafe Rust 的内存错误。此外,已有隔离方案往往依赖硬件特性(例如 Memory Protection Key,MPK)[15, 31],从而阻碍了可移植性。随着“安全语言”兴起,人们正努力改造既有技术以在 Rust 中实现动态检测。但据我们所知,专为 Rust 设计且可移植的动态内存错误检测工具(即 sanitizers)仍然缺乏。
事实上,Rust 社区已经广泛采用 fuzzing 来测试 Rust,并报告了大量 Rust 程序的内存安全漏洞 [1, 3, 13]。Rust 编译器通过编译选项支持用 AddressSanitizer (ASan) 与其他 sanitizer 编译 Rust 程序 [3]。不幸的是,现有的动态测试实践与基础设施是从不安全语言(如 C/C++)沿袭而来,并未充分考虑 Rust 内存错误的特殊性质。
ASan [24, 47] 由于其良好的检测能力与可移植性,已经成为动态内存错误检测的事实标准。然而,它的运行时开销与内存开销众所周知地较高。既有研究尝试改进 ASan 的运行时与内存负担 [27, 59, 60]。其中,优化 sanitizer 的元数据已被证明能显著降低包括 ASan 在内的运行时开销 [27]。更近的工作表明:消除强加在内存访问点上的冗余sanitizer 检查,是优化 ASan 的一个有前景方向 [59, 60]。
ASan 与其他 sanitizers 是为 C/C++ 等不安全语言而设计的,默认假定程序各处都可能存在内存错误。然而,即便与其“不安全邻居”比邻而居,Rust 程序中依然有大量代码保持着语言级的安全保证 [15, 31, 38]。这意味着:我们有机会在不牺牲检测能力的前提下,显著减少 ASan 在 Rust 程序上的运行时开销。
我们提出 RustSan:一种对 ASan 的“改造式”设计,充分利用 Rust 程序的独特性质——绝大多数内存访问仍然遵守语言的安全保证。RustSan 能精确识别内存对象与内存访问点的安全性,从而在安全的访问点上消除代价高昂的运行时检查。
RustSan 的跨 IR 分析(cross-IR)是其关键设计之一:它在 Rust 的高阶 IR(HIR)与中阶 IR(MIR)层面引入细粒度分析。我们的发现是:诸如 unsafe 之类的 Rust 语义并不会被充分传播到后端的 LLVM IR 层。这要求我们发展Rust 专属的分析技术。更重要的是,正如我们的分析所展示的,仔细审视 Rust 的多级 IR 能提升精度,并减少后续分析阶段的复杂性。
基于上述安全信息,RustSan 在影子内存方案上扩展了 ASan,支持选择性插桩(selective instrumentation)与非均匀内存访问的校验。RustSan 在安全位置移除影子内存检查,同时对具有不同安全级别的内存访问点执行适当的验证。
我们对 RustSan 进行了广泛评估,涵盖共计 57 个 Rust crate。通过复现 31 个由 CVE 披露的内存错误,我们验证了:即使移除了大量冗余sanitizer 检查,RustSan 仍保持 ASan 的检测能力。同时,我们在 18 个通用 Rust 程序的基准上测量了 RustSan 的性能:相对 ASan,平均提升 62.3%。在模糊测试场景中,RustSan 的平均性能提升23.52%,最高可达57.08%。
总之,我们的贡献概括如下:
- 提出一种改造式 ASan 设计:通过选择性插桩显著降低 Rust 程序的运行时 sanitizer 开销。
- 融合跨 IR 的静态分析:精确识别 Rust 中的
unsafe代码块及其数据流传播。 - 改造 ASan 的影子内存方案:支持选择性插桩,并为安全 Rust与不安全 Rust提供非均匀内存校验模型。
- 对 57 个 Rust crate 进行全面评估:验证检测能力、可扩展性与性能改进。
- 开源发布 RustSan,希望促进社区采用,从而高效开展 Rust 程序的动态测试。
2. 背景(Background)
本节我们简要说明理解本文所需的关键概念。
2.1 AddressSanitizer
ASan [24, 47] 是一种通用的内存错误检测器,因其与主流编译器良好的兼容性与可用性而被广泛采用。值得注意的是,ASan 在许多动态测试场景(包括模糊测试 fuzzing)中,已成为事实上的标准化 sanitizer 组件。
ASan 通过维护一片影子内存(shadow memory)来表示进程虚拟地址空间中各字节地址的有效性,以此提供内存安全。影子内存的每个字节都可以编码成所谓的 redzone 值,用来把相应的内存地址标记为不可访问(invalid)。ASan 在影子内存里编码了多种 redzone 值,以区分不同类型的错误。当检测到一次对带有非零影子值(例如 0xfd)的 redzone 的非法访问时,ASan 会用该 redzone 值去索引一个预定义表(包含根因信息),并据此生成报告。凡是用 ASan 编译的程序中出现的所有内存访问指令,在执行之前都要通过查询影子内存来完成校验。
ASan 通过在对象的前后插入 redzones 来检测对象上的空间(spatial)内存安全违规。这样,所有越界访问都会在 sanitizer 检查里被发现,因为这些检查会查询影子内存。ASan 还会在堆对象(use-after-free)以及可选的栈对象上检测时间(temporal)内存安全违规。通过用 redzones 标记对象的地址范围,该对象会在影子内存中被作废(invalidated)。例如,ASan 会对最近释放的一组堆对象维持一片隔离区(quarantined set),方式是在这些对象上打 redzone 标记,以捕获释放后使用(use-after-free)。
2.2 Rust 的安全模型(Rust safety model)
Rust 通过其所有权(ownership)模型来提供内存安全。在该模型下,Rust 编译器在静态层面强制每个内存对象恰好隶属于一个拥有者变量(owner)。当某个变量离开作用域时,编译器会自动插入释放其所拥有内存对象的代码,从而让程序员摆脱显式内存管理的负担。
然而,这样的所有权模型对一些通用程序来说可能过于严格。为支持更灵活的编程范式,Rust 还支持对内存对象进行借用(borrowing),以便在无所有权的前提下访问资源。为了安全地启用借用,Rust 为资源关联生命周期(lifetime),并引入 借用检查器(borrow checker) 以保证被借用的引用不会活得比其底层资源更久。
不安全 Rust 与 Rust 的安全保证。 Rust 提供了一个以 unsafe 关键字标示的不安全子语言,用于在暂时绕过其严格的所有权模型时使用。正如既有研究所报道的那样 [22],unsafe Rust 在实践中相当普遍,我们的评测对象中也能见到这种情况。需要强调的是,unsafe 的不安全性并不局限于 unsafe 代码块的边界之内;事实上,在 unsafe 块里发生交互的对象会沿着数据流路径被传播到代码块之外,从而危及原本对安全 Rust所作的安全假设 [15, 31, 38]。位于 unsafe 内部的被破坏对象可能会被安全 Rust 消费,并诱使安全 Rust 产生内存错误。因此,即便某些内存访问点位于安全 Rust(即不在 unsafe 块内),它们也可能被转化为不安全。
在运行时隔离不安全 Rust。 既有工作提出了运行时隔离方案,用于把安全 Rust 从 unsafe 带来的内存不安全中保护起来 [10, 15, 31, 33, 38, 45]。这一任务不仅要约束 unsafe 代码块本身的操作,还要处理由于越界传播的受损对象在安全 Rust 中被使用而可能发生的漏洞 [15, 38]。
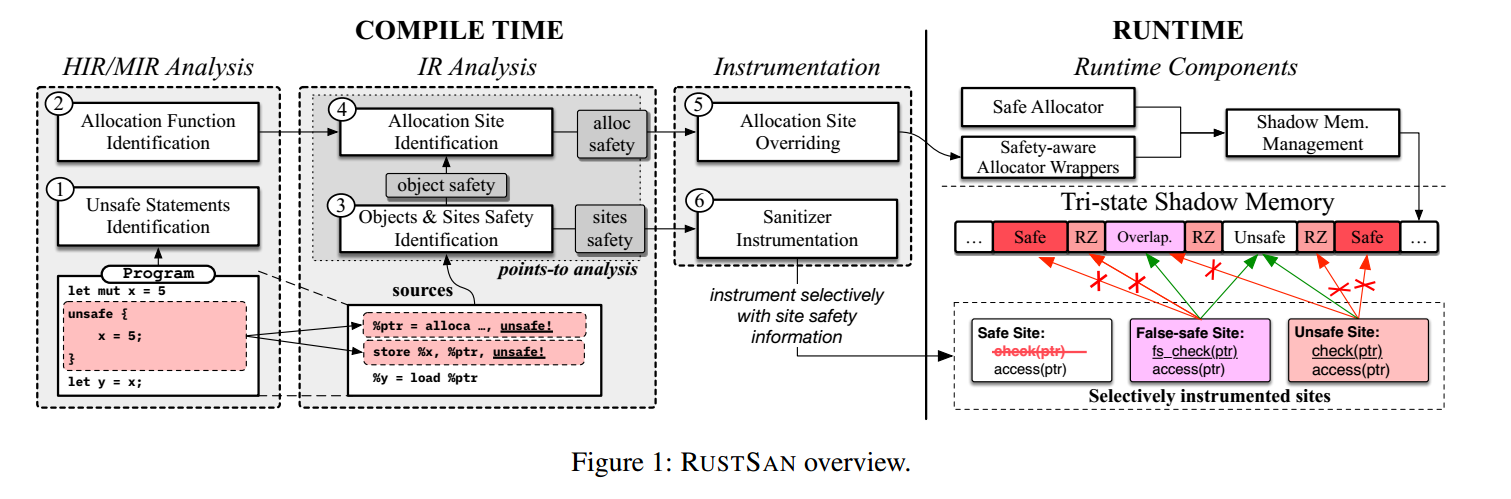
3. RUSTSAN 概览
图1 展示了 RustSan 的整体框架。本文这一节将先介绍后续用于描述 RustSan 设计所需的概念与术语(见 §3.1),随后给出 编译期(§3.2)与 运行期(§3.3)两部分操作流程的总览。
3.1 定义与内存校验模型
本小节介绍贯穿全文的术语体系,用以描述 RustSan 的设计。
对象(objects)与访问点(access sites)。 RustSan 在影子内存(shadow memory)中维护内存对象的有效性状态。程序中的内存访问指令(即 load 与 store)会被插桩,在执行前查询影子内存以进行有效性校验。我们将这些插桩指令统称为访问点(access sites,简称 sites)。
对象的安全性。 我们与既有工作 [15, 38] 一样,区分安全对象与不安全对象:当某个对象在 unsafe 代码块内被修改时,它会成为不安全传播的源(source)。所有经由该不安全源沿数据流受到影响的对象,均被视为不安全对象。安全对象含义不言自明——凡非不安全者皆为安全对象。RustSan 还定义了另一类与对象安全性相关的概念,称为重叠对象(overlapping objects)。在介绍其他相关概念之后,我们会再回到这一概念。
访问点的安全性。 访问点是否安全由其可能访问到的对象决定。举例来说,安全访问点按定义应当在任何控制流路径下都只能访问到安全对象。不安全访问点是指位于 unsafe 代码块内部的访问点。我们用术语 伪安全访问点(false-safe site) 表示位于安全 Rust 中、但可能会访问到不安全对象的那些访问点。更具体地说,若某访问点不在 unsafe 代码块内,但在运行时可能访问到不安全对象,则它是伪安全的。
重叠对象(overlapping objects)。 可借助 points-to 关系 [11] 来解释。当一个伪安全访问点在运行时既可能访问到安全对象又可能访问到不安全对象时,凡可能被该访问点指向的所有对象构成其 may-point-to 集合。我们将属于该 may-point-to 集合中的安全对象定义为重叠对象(它们与不安全对象同属一个 may-point-to 集)。这种对象安全性的划分在 RustSan 的内存校验模型与其影子内存方案中具有重要意义;在后文展开程序分析时我们还会再次讨论它。
访问点的内存校验模型。 在移除安全访问点上的 sanitizer 检查的同时,RustSan 会对剩余的不安全与伪安全内存访问点实施分离的访问校验;这些校验与 ASan 基于 redzone 的越界错误检查并行存在。RustSan 会检测来自不安全访问点对安全对象的一切访问——注意,按定义且经离线分析识别,安全对象本不应从不安全访问点可达。对于伪安全访问点,RustSan 只允许访问两类对象:1)重叠对象(安全对象的一个子集),以及 2)不安全对象。
unsafe 关键字 与 “unsafe”。 在阐明了访问点与对象的(不)安全性之后,我们再强调本文术语中的区分:当我们指 Rust 的关键字 unsafe 时,始终写作 unsafe(加粗并打字机体);而 “unsafe”(不加代码体)一词用于一般意义,指可能被破坏、并且在任意访问点都可能被访问的对象。
3.2 跨 IR 分析(Cross-IR analysis)
RustSan 的第一项任务,是依据前述定义为对象与访问点划分安全性。为此,RustSan 实现了一个细粒度分析,以提取仅存在于 Rust IR(HIR 与 MIR)中的信息。其中之一是:位于 unsafe 块中的会修改内存的语句。这些语句在后续的 LLVM IR 分析中,会被作为不安全性的源(source),用于判定对象与访问点的安全性(图 1 中的 ①)。向 LLVM IR 阶段提供越细粒度的信息,可使该阶段的分析更加高效。下一类关键信息是:Rust 特有的分配函数;我们的 LLVM IR 分析需要识别它们,才能可靠追踪堆分配点(②)。
更具象的分析与插桩发生在LLVM IR 编译阶段。在 LLVM 中,RustSan 采用依赖 Value-Flow Graph [50] 的 points-to 分析 [11],以迭代地确定对象与访问点的安全性;其起点是前一阶段 MIR/HIR 分析中提炼出的源(sources)(③)。同时,RustSan 还通过分配点识别方案跟踪 Rust 的分配位置,使其在插桩中能够可靠地重载堆对象的分配(④)。
3.3 RustSan 的影子内存方案(RustSan shadow memory scheme)
编译期分析得到的信息与能力,随后会在 RustSan 的影子内存方案中被物化为影子内存管理与插桩。RustSan 将其非均匀访问校验模型改造并嵌入 ASan 的影子内存机制之中,从而为被分类为安全、不安全与伪安全的访问点,强制执行不同的内存视图(memory views)。
RustSan 首先引入一种分配器重载(allocator overriding)方案:在影子内存中对安全对象与不安全/重叠对象进行上色(coloring)。做法是:将不安全对象与重叠对象的堆内存分配点替换为 RustSan 的分配器封装(allocator wrappers)(图 1 的 ⑤)。
随后,RustSan 基于其跨 IR 分析得到的访问点安全信息,扩展了 ASan 的插桩方案:对被判定为安全的内存访问点移除 ASan 插桩;而对不安全与伪安全的访问点,则插桩以在访问前查询影子内存,获取被访问对象的安全性,从而落实其感知安全性的内存校验模型(⑥)。
4. 跨 IR:Rust 的 HIR/MIR 分析
RustSan 在 Rust 的 HIR/MIR 层实现了细粒度分析,使对 Rust 特有信息的分析更加准确且高效。已有工作 [15, 38] 也使用了 MIR,但它们大多仅将 unsafe 块内的所有语句统一打标并一路传播到 LLVM IR。我们的发现是:Rust 的 unsafe 语义并不能很好地传播到 LLVM IR。unsafe 是一种供 HIR/MIR 编译阶段消费的语言语义,最终生成的 LLVM IR 并不携带这类信息;同时,与 unsafe HIR 语句相对应的 LLVM IR 指令在多轮变换后难以区分。此外,若在 HIR/MIR 层进行预分析,某些分析还能变得更高效。
因此,我们在 HIR/MIR 层必须识别如下四类关键信息(information):
- I1:
unsafe块中的内存访问语句 - I2:
unsafe块中的内存修改语句 - I3:分配堆内存的 Rust 函数
- I4:可能分配堆内存的 Rust 特有方法
若不在此阶段收集,上述信息在后续的翻译或编译中可能丢失,也会让后续阶段的分析更加复杂。I1 将用于访问点安全性分类时定位内存访问点,并最终用于在 RustSan 的影子内存方案中实施选择性插桩(见 §3.1)。I2 是不安全对象的“出生地”:凡在 unsafe 中至少被修改过一次的对象,都被视作不安全,这些语句也就构成了不安全传播的源。因此,对内存修改语句与其超集(I1)做精细区分,能够减少对对象过度着色(overtainting)。I3 与 I4 则是后续 LLVM 分析准确识别堆分配点所必需的信息。
在提取这些信息的过程中,RustSan 的 HIR/MIR 分析器引入了三项新技术:
- 语句级内存访问跟踪(Statement-level memory accesses tracking),
- 递归安全作用域分析(Recursive safety scope analysis),
- 分配函数识别(Allocation function identification)。
下面详细说明 RustSan 的分析流程。
4.1 背景:Rust 的 HIR/MIR
Rust 前端编译器 rustc 在内部使用两种 IR:HIR 与 MIR。unsafe 块只能在 HIR 层被识别;一旦代码被翻译到 MIR,unsafe 的边界就不可见。因此,RustSan 使用 HIR 来提取与 unsafe 块相关的信息;而在更细粒度的语句级分析上,则使用对分析更友好的 MIR。另外,MIR 与 HIR 之间存在一一映射,从而允许我们在分析 MIR 语句时回查其对应的 HIR 以获取 HIR 专属信息。
4.2 语句级内存访问跟踪(Statement-level memory access tracking)
RustSan 实现了语句级分析来精确跟踪内存访问语句(I1),并从中进一步提炼出写入语句(I2)。若对 I2 采用过度保守的近似,就会在 LLVM IR 阶段人为扩大不必要的不安全对象集合,并以级联方式增加不安全与伪安全访问点的数量。因此,即便能减少很小一部分 I2,对 RustSan 的性能收益也至关重要——其来源正是移除了安全访问点上的检查。
区分写入语句。 我们通过分析 MIR 语法在 I1 中将写入与读取区分开来。我们系统梳理了 Rust MIR 中所有可能的“写内存”语句形式,从而构建出 I2(是 I1 的一个子集)。注意:虽然我们只跟踪 unsafe 中的写语句(因为它们是不安全对象的来源),但对由此产生的不安全对象进行 sanitizer 检查时,读写都会被检测到。
剔除严格局部写入。 语句级分析还允许进一步缩减 I2。RustSan 使用 MIR 数据流分析来找出修改严格局部(strictly-local)变量的语句:这类变量从其当前不安全作用域没有向外的数据流边,因此可以安全剔除,因为它们不会污染任何安全变量。对于修改了严格局部变量的语句,RustSan 将该局部变量的栈分配标记为“分配了一个不安全对象”,并从 I2 中移除对应写语句,以减轻后续 LLVM IR 分析的负担。
4.3 递归安全作用域分析(Recursive safety scope analysis)
除了限制过度近似,我们还缓解了 MIR 分析中可能出现的一类漏报。在 Rust 中,作用域(scope)是代码块的基本单位(例如 unsafe { ... } 本身就是一个作用域)。我们观察到:当 MIR 级优化器在 unsafe 块内将内联函数调用包上一层内部作用域(例如插入花括号)时,unsafe 内部经常出现嵌套作用域。
回忆:一个代码块是否安全(即是否处于 unsafe 内)在 MIR 中不可见。因此,在 MIR 分析中判定作用域安全与否,必须通过带作用域 ID 的回查去查询 HIR。我们发现,若不显式地把作用域分析做成递归(即向上遍历到最外层作用域)且感知 HIR,则 unsafe 内部的嵌套作用域可能被误判为安全。后果是:可能遗漏整段内联函数中的不安全内存访问语句。既有工作 [38] 并未正确识别这些嵌套作用域,导致在 I1 上出现漏报。由于相关实现尚未公开,我们无法确认 TRust [15] 是否也存在同类问题。
笔者注:也就是说,需要递归将unsafe从外部作用域传递到子作用域
4.4 分配函数识别(Allocation function identification)
最后,RustSan 基于仅在 MIR 可用的类型信息提出两条 Rust 特有的启发式,用于识别可能的堆分配函数/方法:
基于分配器 trait 的实现。 若某类型实现了分配器相关 trait(如
Global或bumpalo),我们就把其实现的方法(如Global::alloc())标记为堆分配函数(I3)。后续在 LLVM 中基于 SVF 的 points-to 分析会使用这些信息来建模 Rust 的堆对象分配。以分配器 trait 为边界的类型。 对于以分配器 trait作为边界(bounds)的类型(如
Vec<T, A: Allocator>),RustSan 将其所有实现的方法都视为潜在的堆分配方法(I4)。随后在 LLVM 中,我们通过检查调用图(§5.2)这些方法是否实际触发了堆分配,把这些“潜在方法”细化为真实的分配方法集合。
识别这些分配函数并将其作为污点源,可降低程序分析复杂度。此启发式避免了在 LLVM 分析中,从 Rust 层的分配函数一路追踪到本地分配函数(如 C 库的 malloc)所带来的不必要复杂度提升。
5. 跨 IR:LLVM IR 分析
图2 展示了 RustSan 在 LLVM IR 层执行的各类分析。当上一阶段的 MIR 已被翻译为 LLVM IR,并携带了前述提取的关键信息(I1–I4)后,RustSan 会据此识别如下信息:
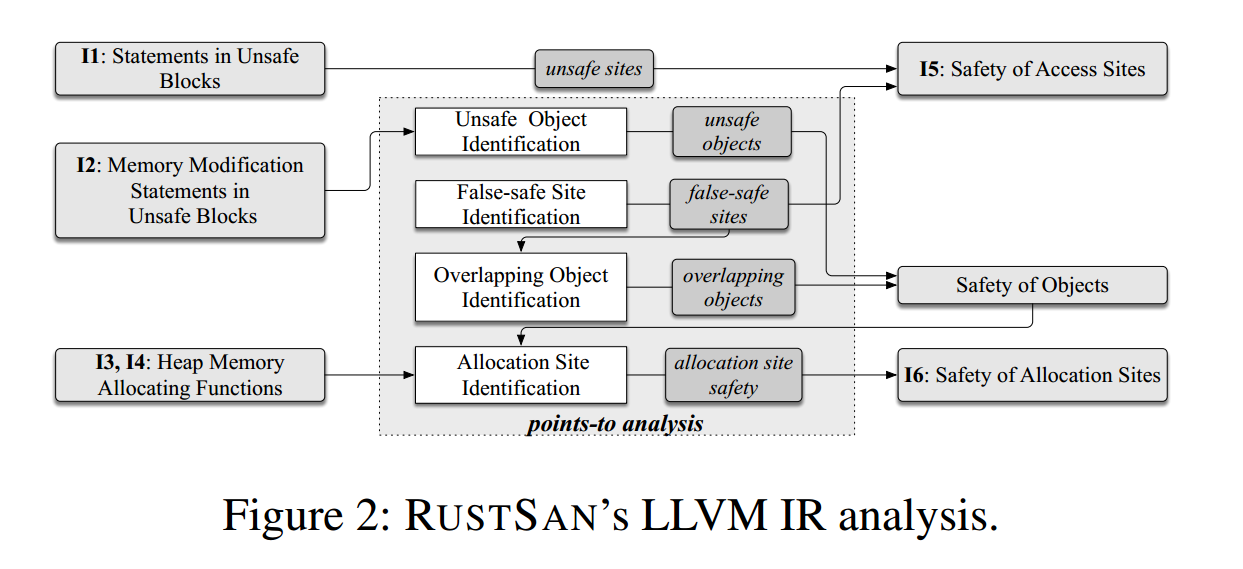
- I5:内存访问点的安全性(safe / unsafe / false-safe)
- I6:内存分配点的安全性(safe / unsafe / overlapping)
以上信息用于支撑 RustSan 运行期组件对影子内存的管理以及对访问点插桩的实施。
I5 使 RustSan 能按访问点的安全级别选择性地应用检查:对安全访问点省略插桩;而对不安全与伪安全访问点,则提供不同的内存访问视图(详见 §6)。
I6 则用于识别所有可能被用来分配不安全/重叠堆对象的 Rust 分配函数(例如已得到的 I3、I4 集合中的函数)。这些分配点(allocation sites)将被替换为包装分配函数,以便更新影子内存中与对象安全信息对应的条目。
5.1 对象与访问点的分类流水线(Object and site classification pipeline)
RustSan 采用 SVF 中对 Andersen 指针分析的实现(字段敏感、上下文不敏感、流不敏感)[11],以分类内存对象与内存访问点的安全性(I5)。这种“上下文不敏感、但字段敏感”的流不敏感分析在保证一定精度的同时,能扩展到大型程序——这是 sanitizer 的必要要求。
笔者注:
字段敏感(field-sensitive): 把同一结构体/对象的不同字段当作彼此独立的内存位置来分析。 例:对
struct S { A *f; B *g; },分析会区分p->f与p->g的指向,不会把它们混为一谈。这样能减少“不同字段被误认为可达”的假阳性。上下文不敏感(context-insensitive): 不区分函数在**不同调用点(调用上下文)**下的行为;一个函数只分析一次,把所有调用者的影响都合并。 例:
foo(x)被多处以不同实参调用,分析把这些调用的别名关系合在一起,可能导致保守的(过近似的)结果,但可显著提升可扩展性。流不敏感(flow-insensitive) 忽略程序内语句的执行顺序与控制流,把同一变量的所有可能赋值统一考虑;等价于“把块内语句当作可任意排列”。 例:对
p = &a; p = &b;或者相反顺序,分析都会得到
p可能指向{&a, &b}。这同样是保守近似,换来更快的全局解。综合起来:字段敏感 +(上下文、流)不敏感 是一种常见折中:在对象内部保持较高精度(区分字段),而在跨调用与控制流层面做合并,以保证在大型程序上的可扩展性。
我们遵循 SVF 的内存模型 [50]:把内存对象按照其分配点建模,分配点既可以是栈分配(alloca 指令),也可以是堆分配(调用 I3 中识别的 exchange_malloc 等堆分配函数)。RustSan 与既有工作 [15, 38] 类似,使用points-to 与数值流分析来找出每个内存访问点可能访问到的对象集合(may-points-to set)。随后我们依据 §3.1 的定义利用这些 points-to 信息来对对象与访问点进行分类。细节如下:
不安全访问点集合(Unsafe site set)。 首先把位于 unsafe 中的内存访问语句标记为不安全访问点。做法是将 I1 中语句在 LLVM 中的等价指令加入“不安全访问点集合”。
不安全对象集合(Unsafe object set)。 接着识别不安全对象:回忆“凡在 unsafe 块内被修改的对象都是不安全对象”。由 HIR/MIR 阶段精炼得到的写语句集合 I2 已被翻译为一组 LLVM IR 指令。RustSan 在这组指令上执行 points-to 分析,找出这些指令可能指向的内存对象——也即可能被 unsafe 修改的对象。由此得到的对象即被归类为不安全对象集合。
伪安全访问点集合(False-safe site set)。 在这一阶段,所有不在“不安全访问点集合”中的访问点暂视为安全。RustSan 需要从中识别并分离出伪安全访问点:按照我们的定义,凡不属于 unsafe 块,但会访问至少一个“不安全对象集合”中的对象的访问点,都是伪安全。因此,我们对这批“暂时安全”的访问点再次执行 points-to 分析,从而得到分离出的伪安全集合。
重叠对象集合(Overlapping object set)。 最后识别重叠对象:它是安全对象集合的一个子集(即与“不安全对象集合”互补的那部分中的子集)。若某个对象与至少一个伪安全访问点之间存在被指向(pointed-by)关系,则把它纳入重叠对象集合。我们在已识别的伪安全访问点集合上迭代执行 points-to 分析以得到该集合。
需要注意的是,重叠对象与不安全对象共同构成伪安全访问点的同一组 may-points-to“住户”(tenants),因此名为 overlapping(“重叠”)。
5.2 分配点安全性的识别(Allocation site safety identification)
到这里,我们已经具备判定分配点安全性(I6)所需的信息。RustSan 必须识别出对象的分配位置,以便在后续插桩中对其进行重载,从而把对象的安全信息写入影子内存(§6 将解释)。Rust 通过对象的 trait 还表现出间接的堆分配行为。因此,除了直接堆分配点之外,我们还提出了一个面向 Rust 的方法来处理间接堆分配点。
直接堆分配点。 首先确定由 I3 中“堆分配函数”直接产生的堆内存分配点的安全性。针对这类分配点,其安全性已经在 §5.1 的分析中完成了分类。因此,我们只需要把该分配点打上“所分配对象的安全级别”的标记,以便后续的插桩能据此进行重载处理。
间接堆分配点。 RustSan 还实现了一套方案来给由 trait 方法调用触发的间接堆分配进行安全性分类。我们在 Listing 1a 中演示了这种间接分配:第 1 行定义了一个 Rust 对象,第 4 行在 unsafe 中对其进行了修改。其编译后的 LLVM IR 对应代码见 Listing 1b;其中,第 4 行的 Vec::set_len 调用被分类为不安全访问点,而第 1 行分配的栈对象被分类为不安全对象。第 3 行调用 Vec::reserve()(一个会触发堆分配的 trait 方法),并把结果写回栈对象 %v。然而,如果我们只看第 4 行实参 %v 的 points-to 集合,它只包含栈对象 %v 本身,就检测不到这次堆对象分配。

为了追踪这类分配点的安全性,RustSan 从分析 I4 所识别的方法在 LLVM 中的调用点入手。针对这些调用点,RustSan 检查如下条件:
1)被调用的对象方法在其调用图上必须能连接到某个堆分配函数(I3);
2)该方法调用中使用的某个实参必须指向一个不安全/重叠对象。
若某次方法调用同时满足这两个条件,RustSan 便把该调用标记为“堆分配点”,并把“被指向的对象”的安全级别附着到该分配点上。利用这一启发式,RustSan 将 Listing 1b 的第 5 行识别为不安全对象的间接堆分配点。
笔者注:原文如此,实际是第3行,“第5行”应该为笔误
5.3 将分析技术适配到 Rust(Adapting analysis techniques to Rust)
我们的 LLVM IR 分析依赖 SVF [50] 的先进数值流(Value-Flow)分析与 Andersen 指针分析实现 [11]。不过,我们对 SVF 进行了若干改动,以便更好地兼容 Rust:
面向 Rust 的分配函数。 首先,我们修改 SVF,使其能识别我们在 HIR/MIR 分析(I3)中发现的Rust 堆分配函数。这样,SVF 就能把这些函数返回的对象指针识别为新分配的堆对象。
指针操作 trait 的模拟。 若某对象类型没有重载其指针运算符,那么可重载运算符实际会从 Rust 标准库的运算符模块(std::ops)中调用到默认符号。我们发现,只需把这些运算替换为默认的取址/解引用语义,就能最小化 points-to 分析的复杂度。
支持常用指令。 我们为 LLVM 指令 ExtractValue 与 InsertValue 等添加了对 SVF 的支持。这些指令在 Rust 编译中被大量使用,但原版 SVF 并不识别。最近一篇工作 [15] 也提到了对 SVF 的类似改动;由于其实现发表时尚未公开,我们文中的 SVF 修改均为自研实现。
6. RustSan 的影子内存方案(shadow memory scheme)
RustSan 对 ASan 影子内存机制的改造,会利用编译期得到的信息(I5、I6),以执行感知安全性的对象分配与选择性插桩。
6.1 感知安全性的对象分配(Safety-aware object allocation)
RustSan 实现了感知安全性的对象分配:把对象的安全信息(I6)编码进影子内存。为达此目的,RustSan 在 ASan 的堆内存分配器之上做扩展,使其在管理影子内存时能够反映对象的安全类别。随后,RustSan 的插桩会把对象的分配点替换为三类之一的分配器封装(wrapper):safe、unsafe、overlapping。这些封装会在堆分配成功后,依据新返回的堆地址为对应对象更新影子内存条目。
分配点重载(Allocation site override)。
RustSan 通过 ASan 现有的方法,钩住程序默认使用的安全分配器。对不安全对象与重叠对象的分配点,RustSan 编译器依据 I6 的安全信息进行替换:从分配点出发,遍历其调用图,把被调用的函数克隆成专门用于“在某一安全级别下分配对象”的版本;例如把 foo 克隆为 foo、foo_unsafe 与 foo_overlapping。然后在调用图上以“分配点的安全级别”为依据,替换对应的函数调用。最后,再把调用图上出现的“堆分配调用”,统一替换为 RustSan 的分配器封装,以执行影子内存管理。
影子字节方案(Shadow byte scheme)。
RustSan 按对象的安全类别为对象“着色”。不安全对象不着色;为了便于读者理解(见图3),我们将安全对象概念性地对应为洋红色,重叠对象对应为粉色(pinkzone)。在影子字节的高 5 位中,ASan 已用来表示各种 redzone;RustSan 选取其中的第 4 与第 5 位来表示安全对象与重叠对象:
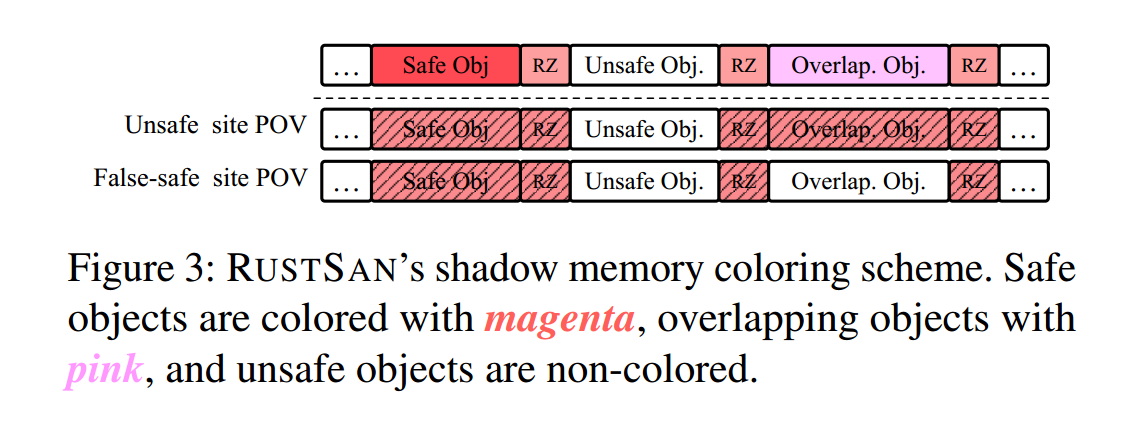
安全对象与重叠对象的影子字节形如 0b00001aaa 与 0b00010aaa,其中低 3 位 aaa 由 ASan 使用,用于在影子内存映射的“每 8 字节真实内存”区间内,表达可寻址字节的位置。
笔者注:低3位表示8字节空间中可寻址字节的offset
除“安全/重叠”两种着色外,我们还使用了此前未占用的两种5 位组合来表示隔离(quarantined)的不安全对象与隔离的重叠对象。例如,当一个重叠对象被释放时,会把其对象内存对应的影子字节更新为隔离的粉色对象。随后,我们扩展了 ASan 在检测到内存错误后调用的 report() 函数,使其能够报告发生在不安全对象或重叠对象上的 use-after-free 情况。
6.2 选择性插桩(Selective instrumentation)
在依据 I5 完成对象安全性分类之后,RustSan 需要按各访问点的安全级别进行插桩。通过移除安全访问点上代价高昂的、基于影子内存的检查,RustSan 显著降低了运行时开销。不过,对伪安全与不安全访问点,RustSan 仍会执行其跨安全级别的内存访问校验,同时保留 ASan 既有的内存错误检测功能。下面对这两点做更细致的说明。
跨安全级别的内存访问校验(Cross-safety memory access validation)。
RustSan 引入一种独特的跨安全级别内存访问校验模型:对伪安全与不安全访问点施加不同的内存访问校验逻辑(见 Listing 2)。

- 对不安全访问点,只要影子字节值非零,RustSan 就报告非法访问错误(Listing 2a)。这意味着:对 洋红色(安全对象) 与 粉色(重叠对象) 的访问都会在 sanitizer 检查时被发现。
- 另一方面,伪安全访问点被允许访问粉色的重叠对象,因此它们既可以访问不安全对象,也可以访问重叠对象(Listing 2b)。
由此,对安全对象的访问会在不安全与伪安全访问点上被检测出来。
请注意,RustSan 在伪安全访问点上的设计是有意识的取舍:ASan 的“基于地址”的净化方式无法进行上下文敏感的检查,因为没有可行的办法在运行时区分对象到底沿哪条数据流路径传播而来。因此,我们的设计选择是继承 ASan 的兼容性与性能,同时在伪安全访问点上放宽检测覆盖面。
与 ASan 既有能力的互操作(Interoperability with existing ASan capabilities)。
RustSan 的影子内存方案在不安全与伪安全访问点上完整保留了 ASan 的检测能力。回顾 ASan 的检测机制:它通过两种方式利用 redzone——(1)在对象之间插入 redzone 以检测越界;(2)在对象被释放时,以 redzone 作废对象本身。由于(1)中“对象间 redzone”与对象安全级别无关,因此在不安全与伪安全访问点发生的越界都能被检测。例如,如果一次合法的对象访问(如伪安全点上对重叠或不安全对象的访问)越界触碰到“对象末端 redzone”,该错误就会被发现并报告。
同样地,不安全对象与重叠对象也适用 ASan 基于隔离区(quarantine)的 use-after-free 检测:通过对象作废实现。RustSan 的堆分配器保留了 ASan 分配器的“对象作废与放入隔离区”的机制——即用 redzone 标记对象地址范围并放入隔离列表。RustSan 的一个关键增补是:利用影子字节中未使用的位来表示“隔离的不安全对象”与“隔离的重叠对象”(前文已述),这有助于在错误检测时生成更丰富的报告(同时包含访问点与对象安全级别的信息)。
笔者注:ASan也能检测use-after-free,只是RustSan利用影子字节中未使用的位,使检测结果更细化
7. 评估(Evaluation)
本节我们评估 RustSan 的实现。实现基于 LLVM 13.0.0 [39] 与 rustc 1.66.0 nightly [46]。所有实验均在一台工作站上完成:AMD Ryzen Threadripper 3990X(64 核 @ 2.9GHz)、256GB RAM、Ubuntu 20.04 LTS。
我们用大规模测试集从检测能力、可扩展性与相对 ASan 的性能改进三方面评估 RustSan。为此,我们构建了四类 Rust 程序测试集:CVE 复现实验集、可扩展性评估集、通用性能基准集与模糊测试基准集。
其中,CVE 复现实验集是一些含有一个或多个CVE 披露的内存错误的程序版本,并附带确定性的输入序列来触发这些缺陷。我们在 §7.2 中通过复现这些 CVE 来经验性验证 RustSan 的检测能力。
可扩展性评估集包含相对较大的代码库,我们在 §7.4 中用它评估 RustSan 的程序分析过程在大型 Rust MIR 与 LLVM IR 上的可扩展性。
通用性能与模糊测试两套基准用于度量 RustSan 对目标程序引入的运行时开销变化(见 §7.6 与 §7.7)。
7.1 unsafe Rust 的使用统计(Unsafe Rust usage statistics)
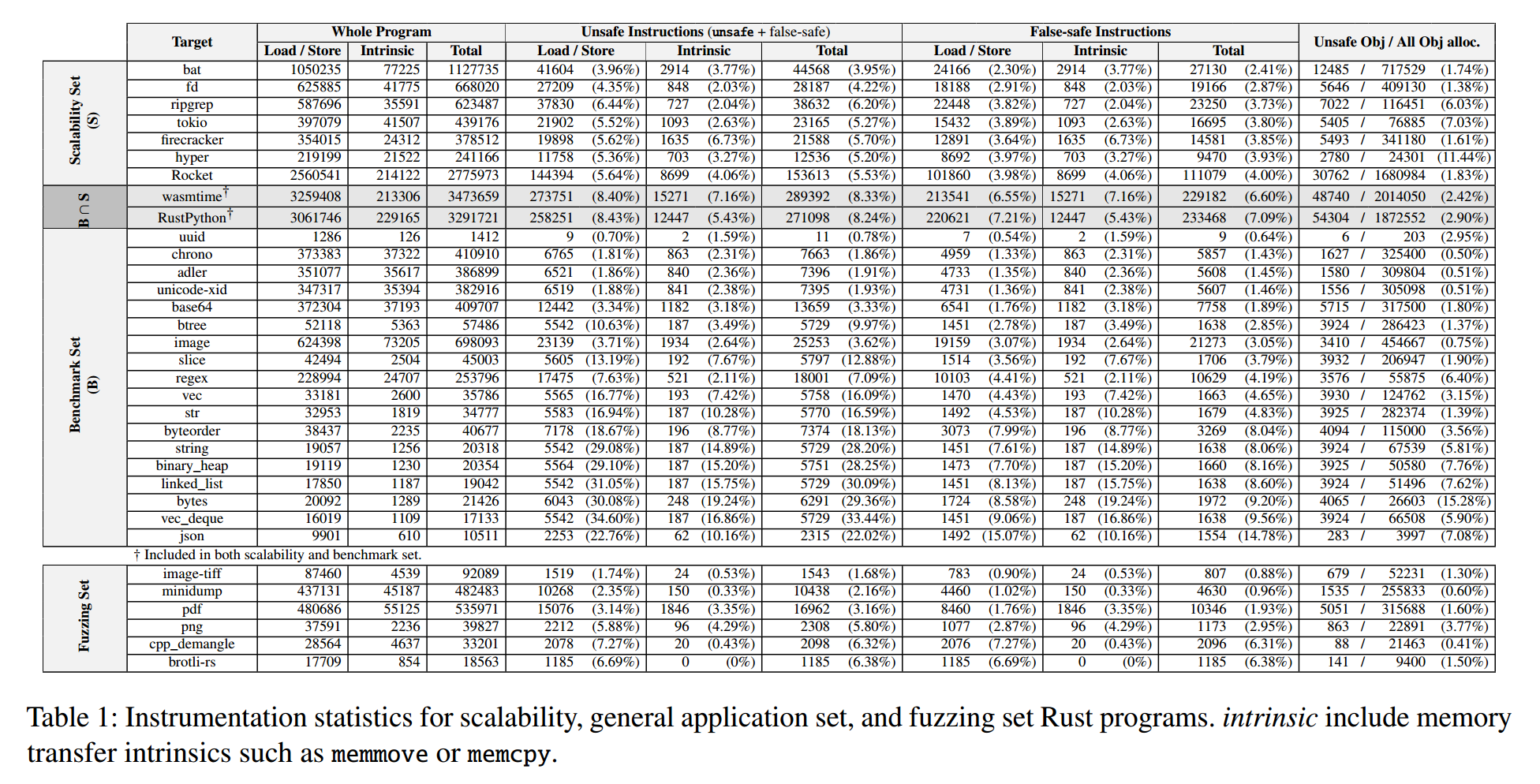
Table 1 展示了我们用于评估的全部 Rust crates 中,内存访问点的出现与安全性统计。表中给出了所有内存访问指令(包括内存内建指令)的总数。跨所有 crates 统计,不安全访问点比例(unsafe 代码块 + 伪安全)的平均值为 10.24%。值得注意的是,那些需要原始指针操作(如 linked_list)或处理底层数据(如 string、bytes)的 crates,往往具有更高比例的 unsafe Rust。
这一不安全访问点比例支持了 RustSan 的动机与方法:需要 sanitizer 检查的内存访问点,最多可达34.60%(vec_deque),而最低仅0.7%(uuid)。不过,这些数字并不直接等价于 RustSan 能消除的运行时开销,因为实际性能还取决于程序执行期间实际遇到的检查次数。关于运行时开销降低,我们在后文的 crate 基准(§7.6)与模糊测试实验(§7.7)中详细讨论。
7.2 检测能力:选择性插桩的稳健性(Detection capability: robustness of selective instrumentation)
围绕检测能力,我们对 RustSan 可能的漏报(false negatives)进行经验性验证;换言之,我们验证 RustSan 所移除的检查不会导致漏报。为此,我们选取了31 个可被 ASan 检出的内存相关 CVE,并用 RustSan 复现这些结果。
CVE 测试集收集(CVE test set collection)。
我们从常见 Rust 程序中收集了一批可复现、且可被 ASan 检测的CVE 级内存漏洞测试用例。漏洞来源于 RustSec Advisory Database [55](其中汇总了来自 crates.io 的 Rust 程序 CVE 报告)。我们收集了数据库中全部 408 条 CVE,并评估其可复现性。在这 408 条中,依据数据库里的类别字段,我们识别出227 条为内存相关漏洞;其中 91 条包含可复现漏洞的 PoC 代码,52 条能被 ASan 成功检测。RustSan 同样全部检出了这 52 个案例。
笔者注:可以学一下怎么去找CVE
检测结果(Detection results)。
表2 重点列出了 52 个复现案例中的 31 个,用以展示 RustSan 的稳健性。这些案例是通过内联的影子内存检查(受 RustSan 的选择性插桩控制)检出的。尽管 RustSan 大幅减少了 Rust 程序中的影子内存检查(见 Table 1),但所有 CVE 案例都成功检出。另外 21 个未在 Table 2 列出的复现案例(如双重释放),是通过拦截标准库调用(例如 free)来检测的;这部分不受 RustSan 的“检查消除”影响,因而如预期般被 RustSan 检出。
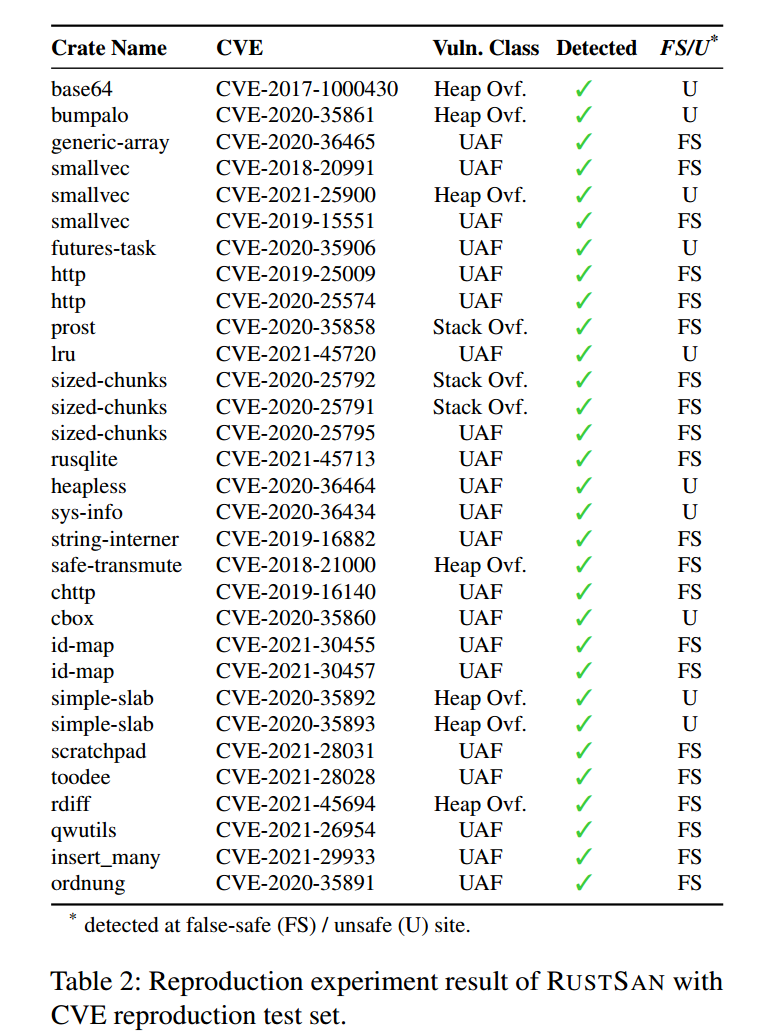
伪安全访问点中的内存错误(Memory errors in false-safe sites)。
Table 2 的 FS/U* 列显示:31 个复现的内存错误中,有 21 个是在伪安全访问点被检测到的。我们还在 unsafe 内部的内存指令上额外放置插桩,由此识别出 10 个位于 unsafe 内部的案例。大量发生在伪安全内存指令上的错误,进一步印证了 RustSan 对伪安全访问点识别的准确性,以及所改造的影子内存方案的正确性。我们对这 21 个伪安全案例中的部分 CVE 做了人工复核;例如在附录 A(Appendix A)中,我们给出了一个堆溢出(CVE-2018-21000)与一个 use-after-free(CVE-2021-45713)的代码示例。
7.3 检测能力:跨安全级别的对象访问(Detection capability: cross-safety object access)
本节评估 RustSan 的独有能力——§6.2 所述的对安全对象访问的检测。我们准备了两个合成示例,展示来自 unsafe 与 false-safe 位置对安全对象进行破坏的情形(见 Listing 3)。

之所以采用合成示例而不是真实漏洞,是因为真实案例往往难以定位与复现。许多真实世界的内存错误是通过 ASan 的对象间 redzone(inter-object redzones)首先被发现的。我们发现:如果一个错误发生在 unsafe 或 false-safe 访问点,并且不触碰任何对象间 redzone,而只是破坏了安全对象的内容(即对象内部破坏,intra-object corruption),则 ASan 往往不会报警,而且这样的真实案例过于特定、难以识别与复现。两个示例均受到真实 CVE(CVE-2017-1000430 与 CVE-2018-21000)的启发,并做了轻微改动,使攻击者可以对安全对象任意进行内存破坏。在 Listing 3a 与 Listing 3b 中,攻击者分别可以在 unsafe 与 false-safe 访问点处控制函数实参,使其指向安全对象。
这些案例不一定触碰 redzone,但能够只破坏安全对象的内容。这些示例说明了 RustSan 的跨安全级别内存访问检测:未改造的 ASan 无法检测到这类错误,而 RustSan 通过扩展 ASan,具备了检测Rust 特有新类别内存错误的能力。
笔者注:不越界,只是通过让伪安全/不安全的访问点指向安全对象,从而只破坏安全对象的内容
7.4 使用 RustSan 的编译时间(Compile time with RustSan)
我们接下来在较大的 Rust crates 上测量 RustSan 的编译时间,以评估其可扩展性。
可扩展性测试集收集。
我们基于 crate 的受欢迎程度(例如 Github ★≥1 万)以及代码规模选择了 9 个 crate。表3 展示了可扩展性集合中大型程序的 RustSan 编译时间。
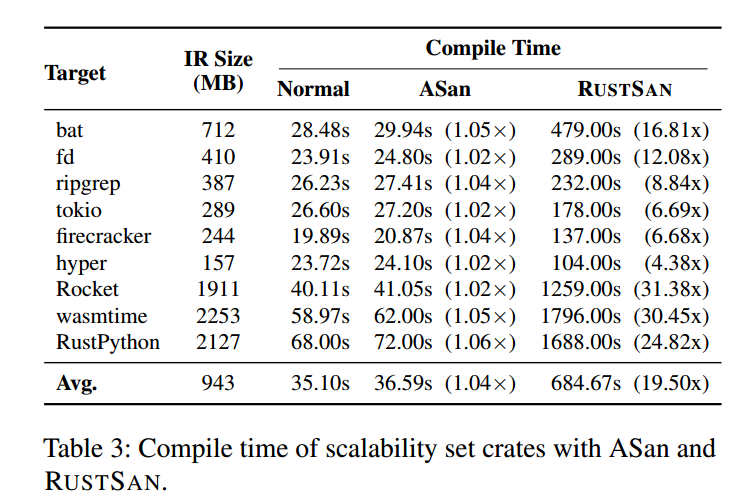
结果讨论。
整体而言,RustSan 将这些 crate 的编译时间提升为原来的 19.50×。其中 wasmtime(WebAssembly 解释器)产生的整程序 LLVM IR 最大,大小为 2253MB;使用 RustSan 的编译耗时 29 分 56 秒,比带插桩的常规构建慢 30.45×。第二大的是 RustPython,其 LLVM IR 为 2127MB、编译耗时 1688s(28 分 8 秒),相当于常规构建的 24.82×。
笔者注:虽然编译时间的增长非常恐怖,但编译完的程序在跑测试时往往以天为单位跑,用较长的编译时间换取编译后程序的性能提升有一定意义。
我们认为,即便对大程序,RustSan 的计算复杂度仍在可接受范围。一个促成因素是 HIR/MIR 层的精炼信息抽取:与既有工作 [38] 相比,我们把污点源数量(将 §4 中的 I2 从 §4b 的规模)在实验中降低了 12.86%(详见附录 B)。
考虑到 RustSan 面向的典型动态测试场景,在测试前对目标程序用 RustSan 进行一次构建的额外成本是可承受的。TRust [15] 提到其处理超大程序的策略是回退到精度较低的上下文敏感分析;该工作在评估中以 tokio 与 hyper 作为大型程序的示例(二者也包含在我们的 Table 3 中)。由于其实现撰写时尚未公开,难以进行直接对比。然而,我们展示了 RustSan 可以用可管理的编译时间构建更大规模的程序。
笔者注:意思是比TRust好点?怎么不跟baseline ASan比,何意味?
7.5 微基准(Microbenchmarks)
我们针对 RustSan 的“感知安全性的影子内存方案”和“改造后的堆分配器”做了微基准测试。对这两个组件开销的细化观察,有助于理解随后在本节后半部分给出的通用应用与模糊测试基准结果。
影子内存检查。
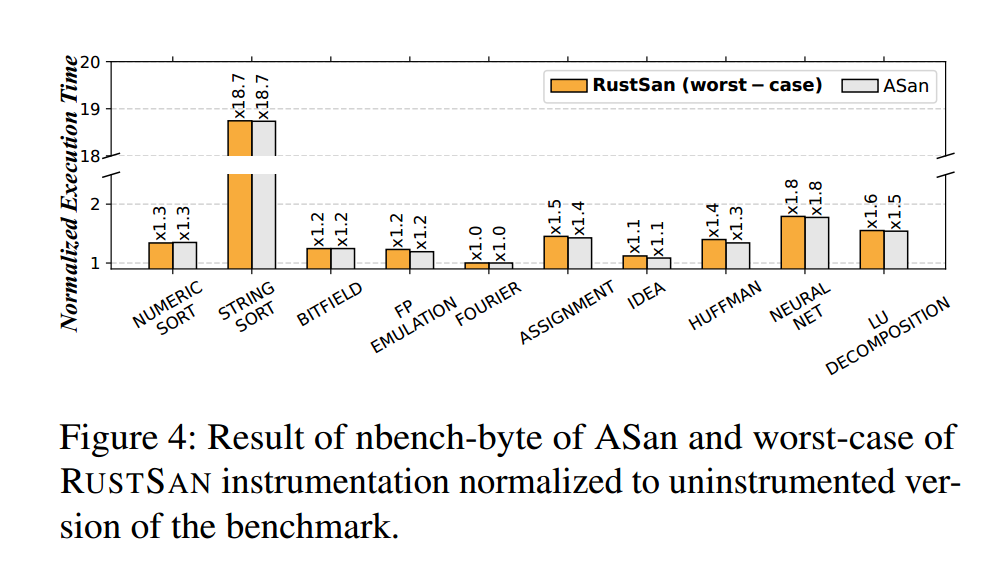
RustSan 的影子内存方案在伪安全访问点上引入了一步额外的影子字节掩码操作(见 Listing 2b)。因此,尽管 RustSan 通过消除检查显著提升了净化器(sanitizer)的运行性能,但其在伪安全访问点上的检查可能带来少量额外开销。为了测量此类“先掩码、再分支(mask-then-branch)”检查的独立开销,我们将 nbench [52] 编译为两个版本:一个使用未改造的 ASan,另一个使用理论上的最坏情形 RustSan。所谓最坏情形,是指 RustSan 在所有内存访问点都插入伪安全访问点那样的“mask-then-branch 检查”,并且不进行任何检查消除。图4 显示了最坏情形 RustSan 与未改造 ASan 的对比:平均而言,ASan 版本的运行时开销为 2.06×,而理论最坏情形的 RustSan 版本为 2.08×。实验表明,伪安全访问点检查带来的性能开销极小。
堆分配器。
我们的基准显示:RustSan 的堆分配器在 ASan 的基础上额外引入了 5.52% 的开销。鉴于其开销很小且实验方法直观,我们将详细讨论放在附录 C。
7.6 通用应用中的运行时开销(Runtime overhead in general applications)
我们用各个 crate 自带的基准集(即 cargo bench),对比测量 RustSan 相对 ASan 在通用 Rust 程序中的运行时开销。
通用应用基准集收集。
我们从 Crates.io [20] 收集了下载量最高的 Rust 程序,并参考了既有工作的被基准化程序 [15, 38]。我们对这些基准逐一进行人工验证,确保其能够正确运行并产生单一数值,便于直接比较 RustSan 与 ASan 的性能。
基准结果。
图5 比较了 ASan 与 RustSan 的运行时开销:将完成基准所用的平均执行时间归一化到未插桩版本。结果显示,ASan 的平均归一化执行时间为 2.40×(即 +140.3% 开销),而 RustSan 为 1.53×(即 +52.9% 开销),RustSan 平均将开销降低至 62.3%。为验证性能提升确由“消除检查”带来,我们提出了一个指标 sanitizer 检查命中减少率(Check Hit Decr. (%),见图 5):该指标表示 ASan 运行期的sanitizer 命中次数中,有多少被 RustSan 消除了。我们确认性能提升与该指标近似成正比。
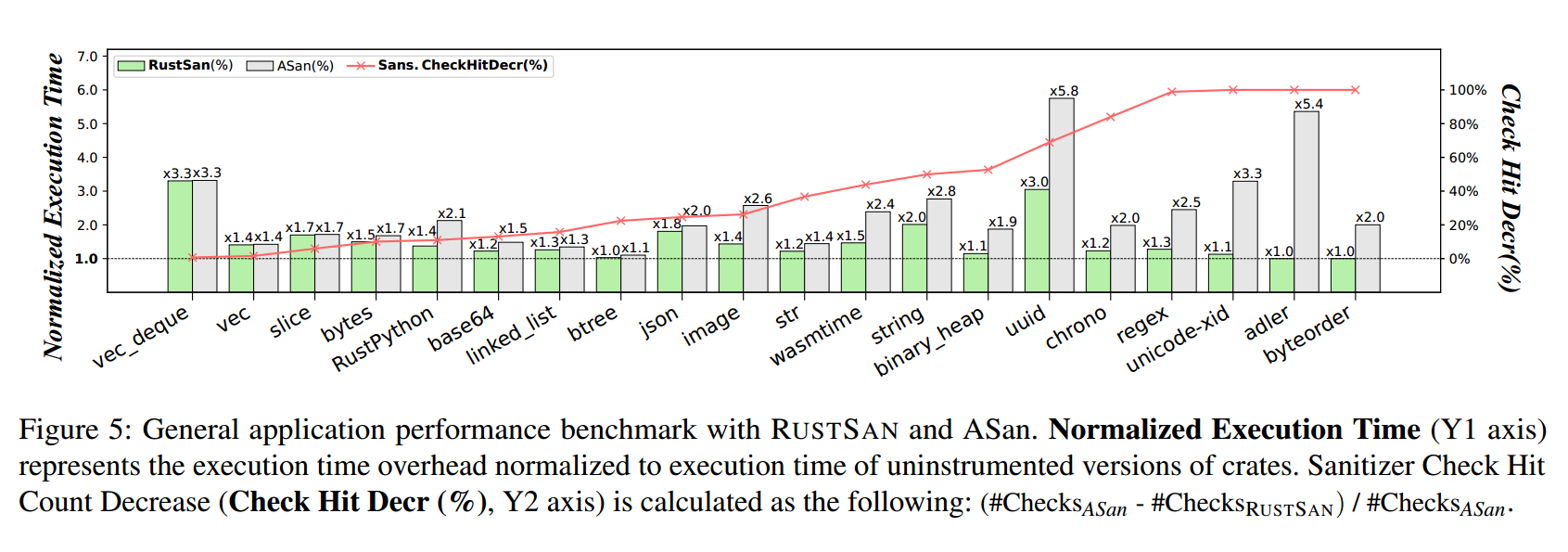
在各个 crate 中,开销下降幅度最大的是 adler:ASan 插桩版本的运行速度下降 5.4×,而 RustSan 移除了 100% 的检查,几乎达到了接近原生的速度。另一方面,部分 crate 的 ASan 开销几乎没有下降,例如 vec_deque 与 vec。我们推测这些程序在运行时极少遇到不安全或伪安全访问点,因此难以从 RustSan 的“检查移除”中获益。
在被评测的 crates 中,wasmtime 与 RustPython 属于 Rust 生态中最复杂且规模较大的项目(两者也包含在我们的可扩展性集合里)。实验因此也表明:RustSan 在大型 Rust 程序上是可行的,更不用说其显著的性能改进(相对 ASan 分别提升 64% 与 63%)。
除了性能之外,这些 crates 在基准执行期间没有出现因 RustSan 导致的误报而引发的程序崩溃。
7.7 模糊测试(Fuzzing)
我们进一步在模糊测试场景下考察 RustSan 相对 ASan 的性能收益。
模糊测试集收集。
我们从 Rust 的 trophy-case [13] 中挑选目标程序,选取已报告缺陷数最多且自带 fuzzing harness 的前六个 crate。
性能度量。
与通用应用基准相同,我们分别用 RustSan 与 ASan 编译这些 crate。随后,使用 AFL++ [23] 4.05c 版本对每个 crate 的两个版本分别进行 24 小时的 fuzz。我们使用各 crate 自带的 harness 与种子集。我们以每秒执行次数(run executions per second)这一模糊测试性能评估中被广泛接受的统计量来展示 RustSan 的性能增益 [23, 60]。得益于 RustSan 的运行时开销降低,在固定持续时间(24 小时)下,fuzzer 能在 RustSan 版本上执行更多轮次。
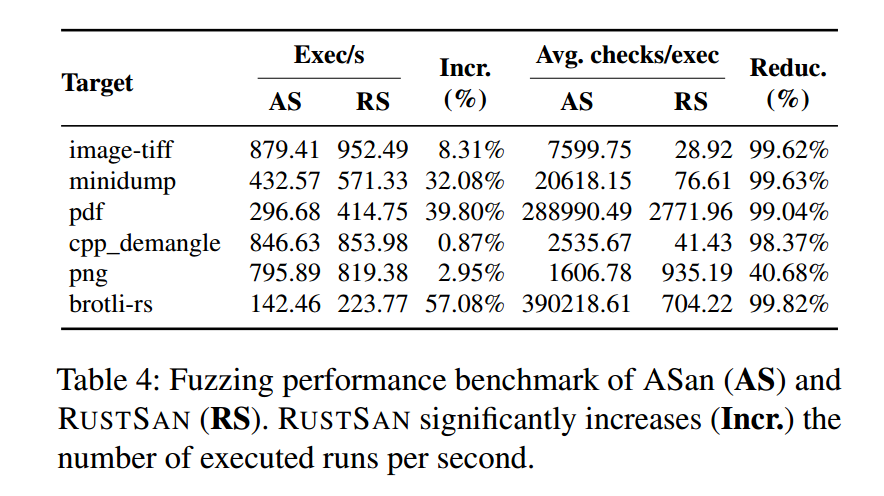
表4 对比了 RustSan 与 ASan。首先从每秒执行次数看,RustSan 相比 ASan 的平均性能提升为 23.52%(记作 Incr(%))。为更好地说明性能提升的来源,我们还测量了每次执行的平均检查数(average checks per execution)。由于 RustSan 的总执行次数通常多于 ASan,我们使用平均值而非总检查次数。各目标中,brotli-rs 的改善最显著(57%):在运行期间,RustSan 每次执行大约移除了 39 万次 sanitizer 检查,这能直接解释其性能提升。相对地,cpp_demangle 的整体开销下降很小(0.87%),尽管检查减少率很高(98.37%)。原因在于该目标的内存访问出现次数本就有限(2535.67 次检查/秒),总体开销被其它因素主导(如种子变异、进程重启等)。
结果讨论。
在多个 crate 的模糊测试中(如 brotli-rs),RustSan 展现出可观的性能收益。然而,模糊测试的整体性能受多种因素影响。例如,目标程序中load/store 指令占比可能较低;又如,某些程序中纯目标代码的执行时间较短,导致 fuzzer 自身操作(进程重启、种子变异等)主导了总执行时间。在这些情况下,RustSan 只能在尽量减少影子内存检查(即 表4 中的 Reduc.%)上做出贡献。本实验的重点是在真实场景下展示 RustSan 的独立性能增益。我们预计 RustSan 还可以与其它 ASan 优化结合以缓解上述因素。例如 FuZZan [27] 优化了影子内存初始化,能直接降低 fuzzer 的进程重启时间。
检测到的错误。
无论是 ASan 还是 RustSan,都未发现由内存错误检测导致的崩溃。结合这些 crate 的 harness 与文档,我们推测原因是它们此前已被 fuzz 到一定程度(例如已超过 24 小时),因此容易触达的缺陷大概率已被修复。即便如此,该结果至少说明 RustSan 没有出现误报导致的崩溃。
8. 安全性与稳健性讨论
Sanitizer(净化器)始终是一种“尽力而为(best-effort)”的解决方案:为了实用性,它们必须在检测覆盖率、可移植性与性能之间权衡。就此而言,我们认为 RustSan 通过大量实证测试,已经展示出其作为一种实用方案的价值。下面我们从稳健性视角重新审视前文的评估,并定性讨论 RustSan 中潜在的不正确性来源。
8.1 实证验证(Empirical validation)
我们的评估不仅确认了 RustSan 的性能优势,在测试样本数量很大的前提下也对其效果给出了经验性验证。正如在 CVE 复现实验(§7.2)中所述,我们确认 RustSan 能成功检出全部 CVE 案例。
在所有基准测试中,RustSan 未出现任何误报(即不会因为检测而导致程序崩溃)。这些 crate 自带的基准并非用于“触发缺陷”,因此它们也可以被视作对 RustSan 的一次独立稳健性测试。回溯来看,RustSan 在 18 个 Rust crate 上共检查了约 15 亿次内存访问点;若其中任意一个真正的安全访问点被错误地标记为 unsafe 或 false-safe,就会导致程序崩溃式的误报,因为这类访问点随后将无法访问安全对象。
在模糊测试实验中,RustSan 在 6 个 crate 上、24 小时内共检查了890 亿次内存访问点,同样未出现误报。与 CVE 实验一样,模糊测试实验也可被视作漏报的间接验证。不过,正如我们提到的,基线 ASan 在该时段也未发现此前未知的内存错误。要在本文范围内进一步验证,还需针对相对未被充分测试的 Rust crate进行理解与选择,并手工构造 fuzzing harness,这是一项相当艰巨的工作,因而未纳入本研究。
8.2 定性分析(Qualitative analysis)
尽管 RustSan 在程序分析技术上有意识地保持保守,但对于复杂程序分析而言,要完全保证完备性与健全性(soundness)仍具挑战。我们借助 表5,系统性地讨论 RustSan 验证模型可能面临的问题。
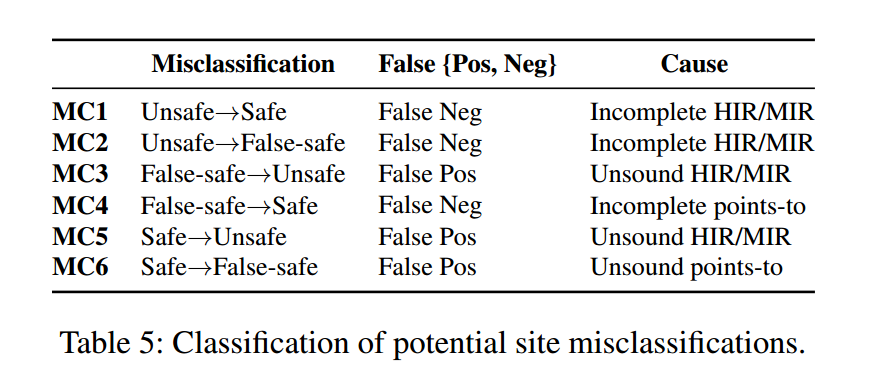
(1)HIR/MIR 分析不完整。
情形 MC1 与 MC2 可能源自HIR/MIR 分析不完整。回忆定义:unsafe 访问点是位于 unsafe 代码块内部的内存访问点,应由 MIR 层来识别。若被误分,后果是:一个 unsafe 访问点可以悄然破坏安全对象(对应 MC1),或破坏重叠对象(对应 MC2)。这二者均会削弱 RustSan 的内存验证模型,属于漏报。
(2)HIR/MIR 分析不健全。
相反地,不健全的 HIR/MIR 分析可能把位于 unsafe 之外的安全/伪安全访问点误判为unsafe(情形 MC3、MC5)。其中 MC5 会在本应合法访问安全对象的地方触发误报;此外,它还会降低性能优势,因为系统被迫加入不必要的检查。MC3 同样是误报:在 RustSan 的验证模型下,伪安全访问点应当可以访问安全对象;一旦被误判,它为了访问沿着安全数据流在运行期送达的安全对象而触发告警。
(3)RustSan 的 HIR/MIR 分析的稳健性。
我们的 MIR 分析是针对 unsafe 代码块的定向分析,而这些代码块仅占 Rust 程序的极小部分。因此,MIR 分析是可以做到完整且健全的。进一步地,RustSan 在 MIR 分析中引入了递归的作用域安全性识别,修复了既有工作 [38] 中的一类漏报来源。据此,我们认为 HIR/MIR 分析是稳健的,相关误判应当极为罕见;此外,我们的实证评估也从侧面证明了没有误报。
(4)points-to(指向关系)分析不完整。
不完整的数据流/points-to 分析可能导致 MC4:分析器遗漏了“访问点 ↔ 不安全对象”之间的指向关系。结果是:某个必须只能访问重叠/不安全对象的伪安全访问点被错误地“证明”为安全,绕过了检查。此时 RustSan 将无法感知该访问点对安全对象的破坏——这是漏报。
(5)points-to 分析不健全。
不健全的 points-to 分析可能导致 MC6:把真实的安全访问点误分为伪安全访问点。与 MC5 类似,这会引发误报并因不必要的检查而降低性能。
(6)points-to 分析的稳健性。
RustSan 采用了先进的程序分析工具 [50],该工具已在软件安全领域被广泛使用 [15, 18, 28–30, 38, 44]。我们的评估显示,MC6-型误报应当罕见。不过,MC4 的风险仍然存在,因为 points-to 工具是一个外部依赖;尽管如此,基于其在该领域的广泛实践,我们仍认为该工具总体可靠。
9. 相关工作(Related Work)
9.1 面向内存缺陷检测的 Sanitizer
Sanitizer 长期以来被用于检测以不安全内存语言编写的程序中的缺陷,用以发现各种内存错误 [12, 34, 40, 42, 47-49, 53, 58]。其中既包括空间类内存错误的净化(sanitization)[12, 19, 40, 42, 47, 54],也包括时间类内存错误的净化 [34, 47, 53, 58];在程序动态测试领域已有多种成熟的替代方案。
在众多设计中,ASan [24, 47] 是最为广泛使用并集成进主流编译器的 sanitizer,得益于其轻量的影子内存检查机制与高度兼容性 [48]。RustSan 的目标,是在保留 ASan 的可移植性与兼容性的前提下,为 Rust “改造”ASan,通过消除冗余检查来提升性能。
9.2 面向性能的 Sanitizer 优化
Sanitizer 往往带来很高的运行时开销,因此已有大量工作尝试对其进行优化。
消除 sanitizer 检查。
识别并删除冗余检查是一条降低开销的重要路径 [16, 25, 32, 43, 51, 60]。不少研究通过精确的静态分析定位并移除不必要的检查,同时不牺牲检测覆盖率。例如 SANRAZOR [59] 结合动态代码覆盖率与静态数据依赖来发现冗余检查;ASan-- [60] 则采用轻量静态分析来检测/移除重复性检查,并优化 sanitizer 检查。这些工作大多面向 ASan 的典型目标(如 C/C++ 程序)进行优化。与之相对,RustSan 指出了 ASan 在部分不安全(partially-unsafe)的 Rust 程序上的低效,并给出了解决方案。
做性能—检测权衡。
也有工作提出在既定的性能预算下,对“检测能力与性能”进行权衡。例如 ASAP [47] 对目标程序做 profile,找出移除检查后收益最大的热区;SANRAZOR [59] 提供可配置的多档位权衡。与这些工作不同,RustSan 保留了 ASan 的检测能力,同时新增了Rust 特定的安全对象保护。
优化 sanitizer 运行期。
另一些工作直接优化 sanitizer 的运行时机制,使其更适配特定负载(如 fuzzing)。Fuzzan [27] 为 redzone 管理设计了高效元数据,加速了“ASan+fuzzing”;PartiSan [35] 将应用划分为带净化与不带净化的切片,使后者不承受额外开销;Bunshin [57] 则在并行运行的程序间分摊sanitizer 检查。我们预计 RustSan 可以与这些技术组合,进一步优化其性能。
9.3 Rust 程序加固
用于加固 Rust 的静态分析。
已有静态分析器被用于检测 unsafe Rust 中的缺陷。例如 Rudra [14] 在 Rust 的 MIR/HIR 上引入了可扩展静态分析来寻找特定模式的漏洞;MirChecker [37] 结合数值分析与 MIR 符号执行以检测运行期 panic与内存错误;Rupair [26] 可在 unsafe 代码中自动检测越界并用 MIR 上的轻量数据流分析修复。RustSan 同样利用 HIR/MIR 分析,但进一步做了更细粒度的信息提取(面向 unsafe 代码块的语句级分析)。静态/动态测试各有优劣,具体适用取决于场景;与这些工作不同,RustSan 是运行期的 sanitizer(例如可在 fuzzing 期间发现内存错误)。
Rust 程序的运行期隔离。
有大量工作提出了运行时隔离机制,以约束(contain)由 unsafe 代码块与不安全外部库触发的内存错误带来的影响。XRust [38] 与 TRust [15] 引入了分离的内存分配器方案:将被 unsafe 触及的对象放入不安全堆;同时,它们还提供定制插桩框架,用以隔离会受不安全对象影响的安全内存指令(即本论文 §3.1 所述的 false-safe)。此外,也有研究探索基于 MPK(Memory Protection Key) 的隔离,用于限制 C 库的内存访问 [15, 31, 45];例如 PKRUSafe [31] 通过动态剖析自动识别在 Rust 与 C 间共享的对象,并用 MPK 隔离对这些对象的访问。
这些用于识别 Rust 程序指令与对象安全性的静态分析方法 [15, 38] 启发了 RustSan;而 RustSan 则在 MIR 中把它们细化到语句级。另一方面,RustSan 作为一个 sanitizer,需要在错误发生时检测出来。它有意识地继承了 ASan 的兼容性与可移植性:一个明确的设计选择是避免依赖体系结构特定的特性(如 MPK)。此外,它也避免了如 上下文敏感 points-to 分析 [15] 这类计算开销巨大的技术,以保证可扩展性。
10 结论(Conclusion)
本文提出了 RustSan:一种为 Rust 程序 “改造” AddressSanitizer(ASan) 的设计。RustSan 通过对内存访问点的选择性插桩,显著提升了 ASan 在 Rust 程序上的性能。核心洞见在于:大量访问点在含有 unsafe 的程序中依然保持 Rust 的安全性保证,因此可以被识别并免除sanitizer 检查。我们的评估通过CVE 复现实证证明了 RustSan 的检测能力;在通用应用基准上,RustSan 相比 ASan 展现出 62.3% 的性能提升;在模糊测试实验中,平均提升为 23.52%。
附录
A. CVE case study
我们在此给出若干案例研究,分析 Rust 中内存错误的根因以及 RustSan 对它们的检测。

案例 1:CVE-2018-21000
该 CVE 属于 Rust 对 transmute 的实现中的堆溢出。问题的根源在 Listing 4a 的第 5 行:Vec::from_raw_parts 是 Rust 标准库函数,用于从原始指针构造新的向量对象,函数参数依次为向量长度与容量。这里的错误是第二、第三个参数的顺序被颠倒。在 Rust 术语中,容量(capacity)表示为未来插入元素所预留的最大空间,而长度(length)表示当前向量中实际元素个数。因此,被错误构造的向量极易在后续使用中导致对象边界之外的内存访问。在我们的复现中,RustSan 报告了在一个伪安全站点(false-safe site)上,对一个不安全对象触及了对象末端 redzone 的访问。
案例 2:CVE-2021-45713
该 CVE 发生在 rusqlite 中,是一起释放后使用(use-after-free),由 unsafe Rust 中违背 Rust 对象生命周期保证引起。在 Listing 4b 的第 16 行,update_hook API 将闭包强制转换为函数指针,并把它注册到 unsafe 代码块中的外部(C/C++)库。unsafe Rust 与这些外部库都不遵守 Rust 的生命周期保证。其结果是:当该闭包被回调且相关对象被销毁时,产生了释放后使用。在本 CVE 的复现中,RustSan 在一个伪安全站点上报告了对已隔离(quarantined)的安全对象的访问。
B. Taint source reduction with HIR/MIR analysis
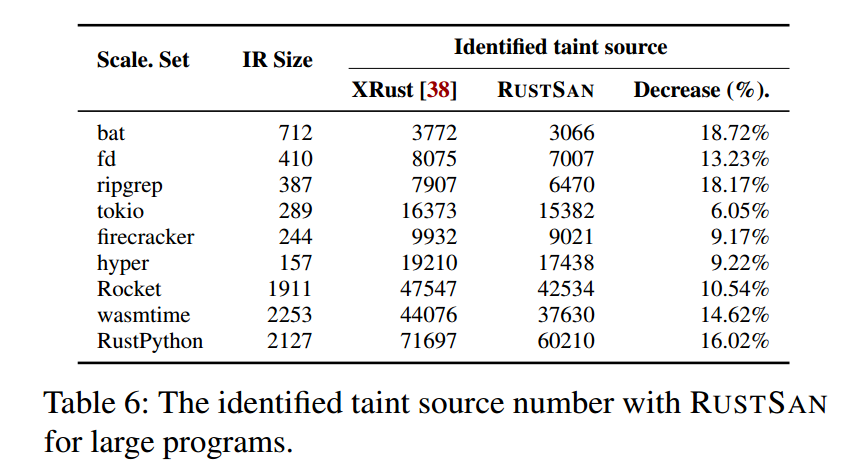
我们还评估了 RustSan 与 XRust [38] 在 HIR/MIR 分析中用于污点源(taint source)识别的方法(即§4中所述的 与 )。需要注意的是,XRust 将 (即 所有位于 unsafe 代码块中的语句)直接视为污点源;而 RustSan 使用的是 ,它是 的精炼子集,只包含写语句。此外,RustSan 能够识别内联函数中的语句,而 XRust 会遗漏这类语句。因而,采用 会减少污点源的数量;但与此同时,把内联函数中的语句也纳入考虑,又会使 RustSan 的污点源集合相较 XRust 增加。即便如此,实验显示 RustSan 的污点源集合规模平均减少了 12.86%。这意味着 RustSan 在 HIR/MIR 阶段输出了更为精细的分析结果,传递到 LLVM 阶段后,缓解了 LLVM IR 分析的复杂度。
C. Heap allocator microbenchmark
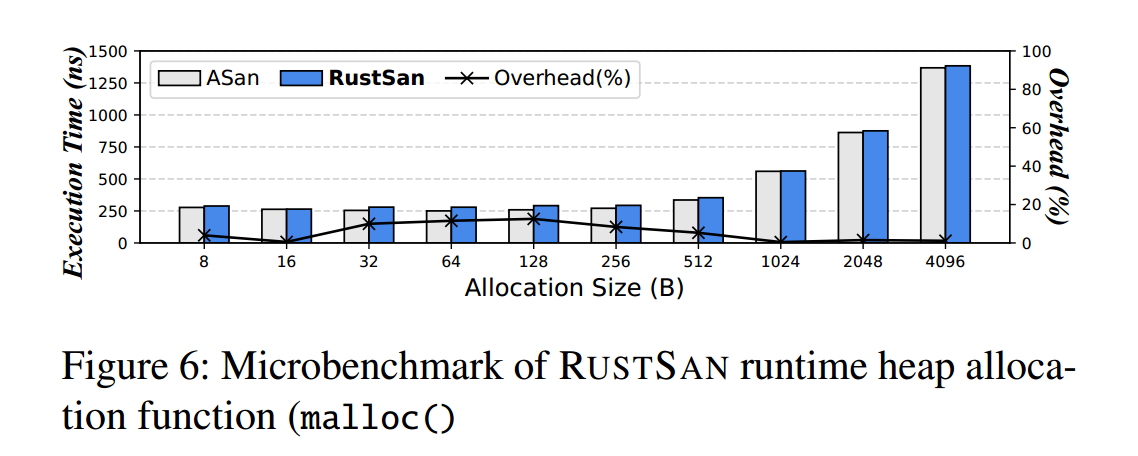
RustSan 修改了 ASan 的堆分配器,使其按照 RustSan 的影子内存(shadow memory)方案为新分配的内存“着色”。
为衡量运行期影子内存管理所带来的开销,我们比较了在 RustSan 与 ASan 下,对于不同分配尺寸时 malloc() 的平均执行时间。对每一种内存大小,我们将分配操作(malloc())重复执行 1000 万次。
图6 展示了实验结果:相对于 ASan 的分配器,RustSan 的分配器平均额外开销为 5.52%。基于该微基准结果,我们认为:在通用应用与模糊测试(fuzzing)基准中,由堆分配器改动引入的影响可以忽略不计。