Deobfuscation: Reverse Engineering Obfuscated Code
Deobfuscation: Reverse Engineering Obfuscated Code
论文来自 IEEE 12th Working Conference on Reverse Engineering (WCRE 2005)的《Deobfuscation: Reverse Engineering Obfuscated Code》。

摘要
近年来,代码混淆作为一种低成本的方法引起了人们的关注,通过使攻击者难以理解专有软件系统的内部工作原理来提高软件安全性。本文研究了模糊程序的自动去模糊技术,作为对此类程序进行逆向工程的一步。我们的结果表明,旨在增加静态分析难度的代码混淆的大部分影响可以通过简单的静态和动态分析的组合来克服。我们的研究结果在软件工程和软件安全方面都有应用。在软件工程的背景下,我们展示了如何使用动态分析来增强逆向工程,即使是那些设计得难以逆向工程的代码。对于软件安全,我们的结果可以作为代码混淆器的攻击模型,并有助于开发更具弹性的混淆技术。
1. Introduction
近年来,代码混淆作为一种提高软件安全性的低成本方法引起了人们的关注[4,7,8,21,22,29]。代码混淆的目的是使攻击者难以对程序进行逆向工程。这个想法是通过使混淆的程序“太难”理解来防止攻击者理解程序的内部工作原理,也就是说,通过使逆向工程程序的任务在所需的资源或时间方面“太昂贵”。混淆也被用来保护“软件水印”和指纹,这些水印和指纹旨在阻止软件盗版[1,7,8]。假设是,让攻击者难以理解程序的内部运作,可以防止他们发现代码中的漏洞,并有助于保护程序所有者的知识产权。
然而,值得注意的是,代码混淆只是一种技术。正如它可以用来保护软件免受攻击者的攻击一样,它也可以用来隐藏恶意内容。例如,某些类型的复杂计算机病毒,如多态病毒,已经采用模糊技术来防止病毒扫描程序的检测[27]。
这就提出了两个密切相关的问题。从软件工程的角度来看,第一个问题是:什么样的技术对理解混淆的代码有用?例如,假设我们从一个网站下载了一个声称是某个应用程序的安全补丁的文件。在应用补丁之前,我们可能需要验证该文件是否包含任何恶意负载。如果文件的内容被混淆了,我们如何验证这一点?从安全角度来看,第二个问题是:当前代码混淆技术的弱点是什么,我们如何解决这些弱点?如果我们的混淆方案在阻止攻击者对代码进行逆向工程方面无效,那么它们不仅无用,而且实际上比无用更糟糕:它们增加了程序的时间和空间要求,并可能导致错误的安全感,从而阻止其他安全措施的部署。因此,通过开发和测试攻击模型来识别当前混淆方案中的任何弱点,可以带来更好的混淆方案,并相应地提高软件安全性。
本文旨在解决上述问题,包括理解混淆代码的技术以及复杂混淆算法的优缺点。我们描述了一套代码转换和程序分析,可用于识别和删除混淆代码,从而帮助对混淆程序进行逆向工程。我们使用这些技术来检查控制流扁平化混淆技术的弹性,该技术在研究文献[2,29]中提出,并在Cloakware的商业代码混淆产品[5]中使用,以抵御基于静态和动态分析组合的攻击。我们的结果表明,从逆向工程的角度来看,简单的动态技术在处理代码混淆方面通常非常有用。从软件安全的角度来看,我们表明,使用简单而众所周知的静态和动态分析的组合,可以在很大程度上消除许多混淆技术。
int f(int i, int j)
{
int a = 1;
if (i < j) {
a = j;
}
else do {
a *= i--;
} while (i > 0);
return a;
}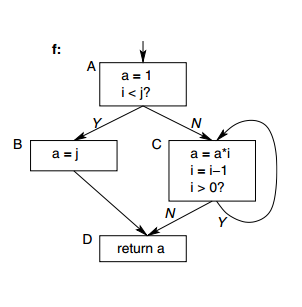
Figure 1: An example program and its control flow graph
2. Obfuscating Transformations
从概念上讲,我们可以区分两大类混淆转换。第一种是表面混淆,侧重于混淆程序的具体语法。一个例子是更改变量名或将不同作用域中的不同变量重命名为相同的标识符,如用于混淆.NET的“Dotfuscator”工具[25]。第二种是深度混淆,试图混淆程序的实际结构,例如通过改变其控制流或数据引用行为[4,8]。虽然前者可能会使人类更难理解源代码,但它并不能掩盖程序的语义结构。因此,它对用于逆向工程的算法没有影响,例如程序切片,这些算法依赖于代码结构和语义,而不是具体的语法。例如,只需使用解析器使用语言的作用域规则解析变量引用并相应地重命名变量,就可以直接撤消Dotfuscator风格变量重命名的大部分效果。相比之下,深度混淆会改变程序的实际结构,从而影响程序分析和逆向工程语义工具的效率。
由于篇幅限制,不再对不同类型的深度混淆技术进行更详细的阐述,但感兴趣的读者可以参考Collberg等人[9]的讨论和更详细的分类。就本文而言,只需注意,解决深度混淆问题(需要对程序的语义方面进行推理)直观上比解决表面混淆问题更困难,表面混淆本质上是一个语法问题。本文主要关注试图掩盖程序控制流逻辑的深度混淆技术。
在之前的工作中,我们考虑了基于不透明谓词对经过多次控制流混淆的程序进行去模糊的问题;我们发现,对于所考虑的混淆(Collbergs的Java程序Sandmark混淆工具[6]中实现的一组控制流混淆),大多数混淆都可以通过结合相当简单的静态和动态分析来消除[3]。本文考虑了一种不同的控制流混淆的方法,该方法来自王晨曦的论文[29,30]。这一选择有三个因素。首先,根据我们的实验,它似乎比我们之前考虑的更难打破[3]。其次,其他研究人员也考虑过这种方法[2],因此研究界对其弹性很感兴趣。最后,它是Cloakware股份有限公司工业模糊处理工具的关键组成部分[5]。
本节介绍基本的控制流混淆技术,以及旨在使基本方法更难破解的两个增强功能。
2.1. Basic Control Flow Flattening
控制流扁平化旨在通过“扁平化”控制流图来模糊程序的控制流逻辑,使所有基本块看起来都有一组相同的前导和后继。执行过程中的实际控制流由调度器变量引导。在运行时,每个基本块都会给这个调度程序变量分配一个值,指示下一个基本块应该被执行。然后,开关块使用调度器变量通过跳转表间接跳转到预期的控制流后续器。
例如,考虑图1所示的程序。该程序的基本控制流扁平化导致如图2所示的控制流图,其中S是开关块,x是调度器变量。1块Init中调度器变量x的初始赋值旨在在控制首次进入函数时将控制路由到f()的原始入口块A;在此之后,控制流由各个基本块中x的分配来引导。
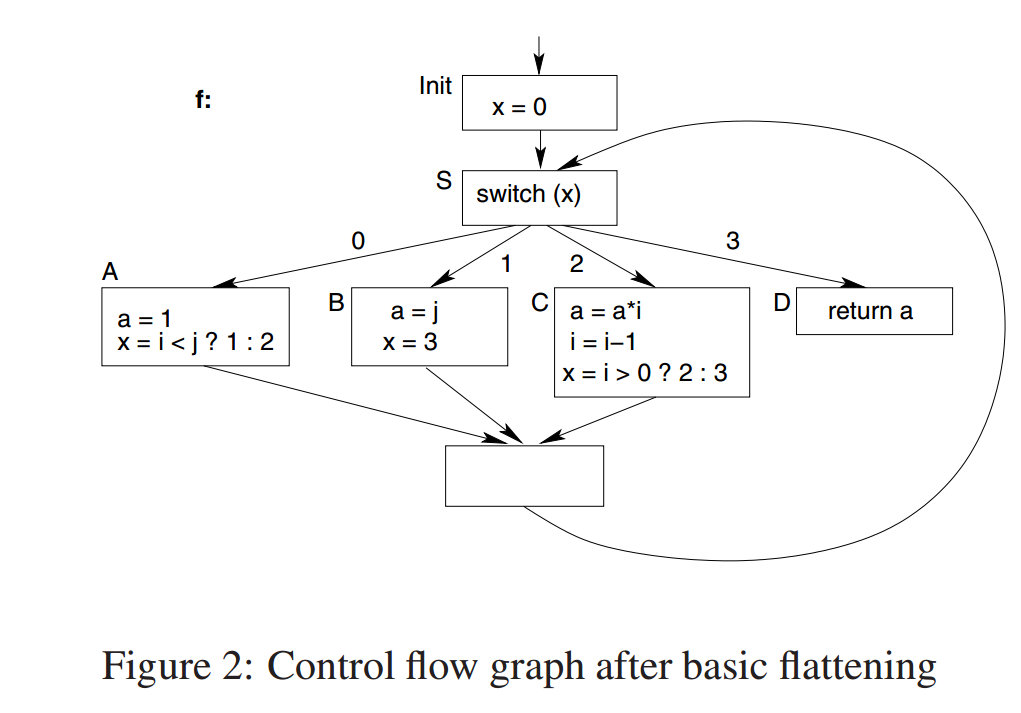
2.2 Enhancement I: 程序间数据流
在第2.1节讨论的基本控制流扁平化转换中,分配给调度变量的值在函数本身中可用。因此,虽然模糊代码的控制流行为不明显,但可以通过检查分配给调度变量的常量来重建它。反过来,这只需要程序内分析。
使用过程间信息传递可以提高混淆技术的弹性。其想法是使用全局数组传递调度变量值。在函数的每个调用点,这些值都会从数组中的某个随机偏移量开始写入全局数组(适当调整以避免缓冲区溢出)。如此选择的偏移量在函数的不同调用位置可能不同,并作为全局或参数传递给混淆的被调用者。然后,模糊代码从全局数组中为调度变量赋值。实际访问的位置和这些位置的内容都不是恒定值,通过检查被调用者的混淆代码也不明显。将这种混淆应用于图1中的程序所得到的代码如图3所示。
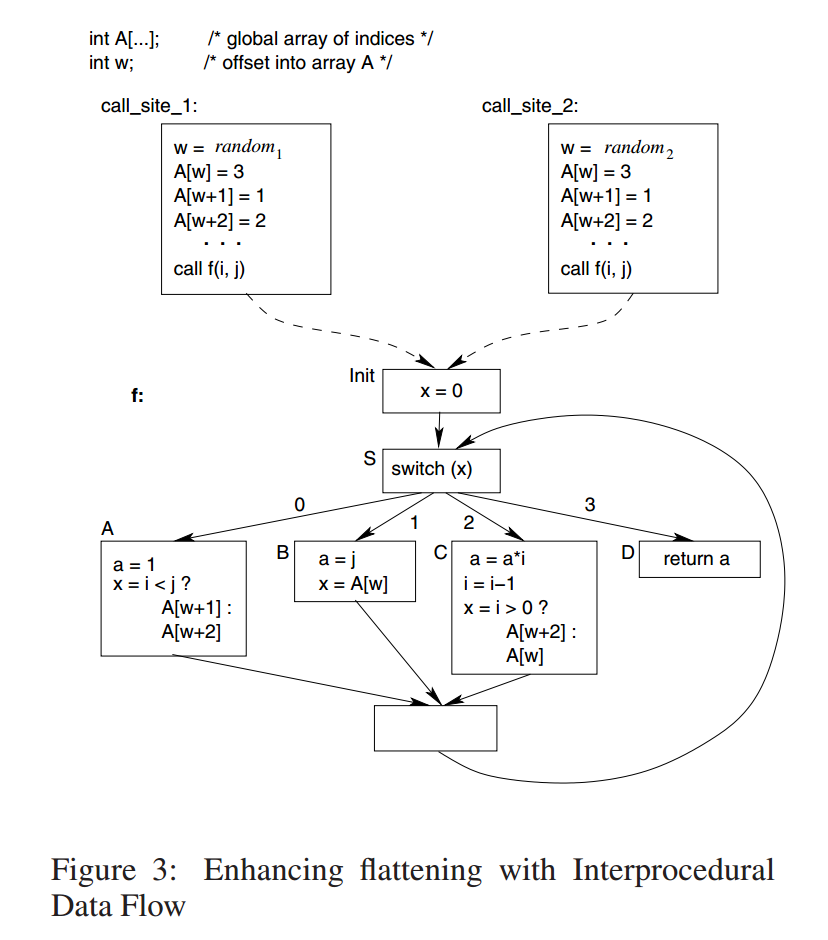
2.3 Enhancement II: Artificial Blocks and Pointers
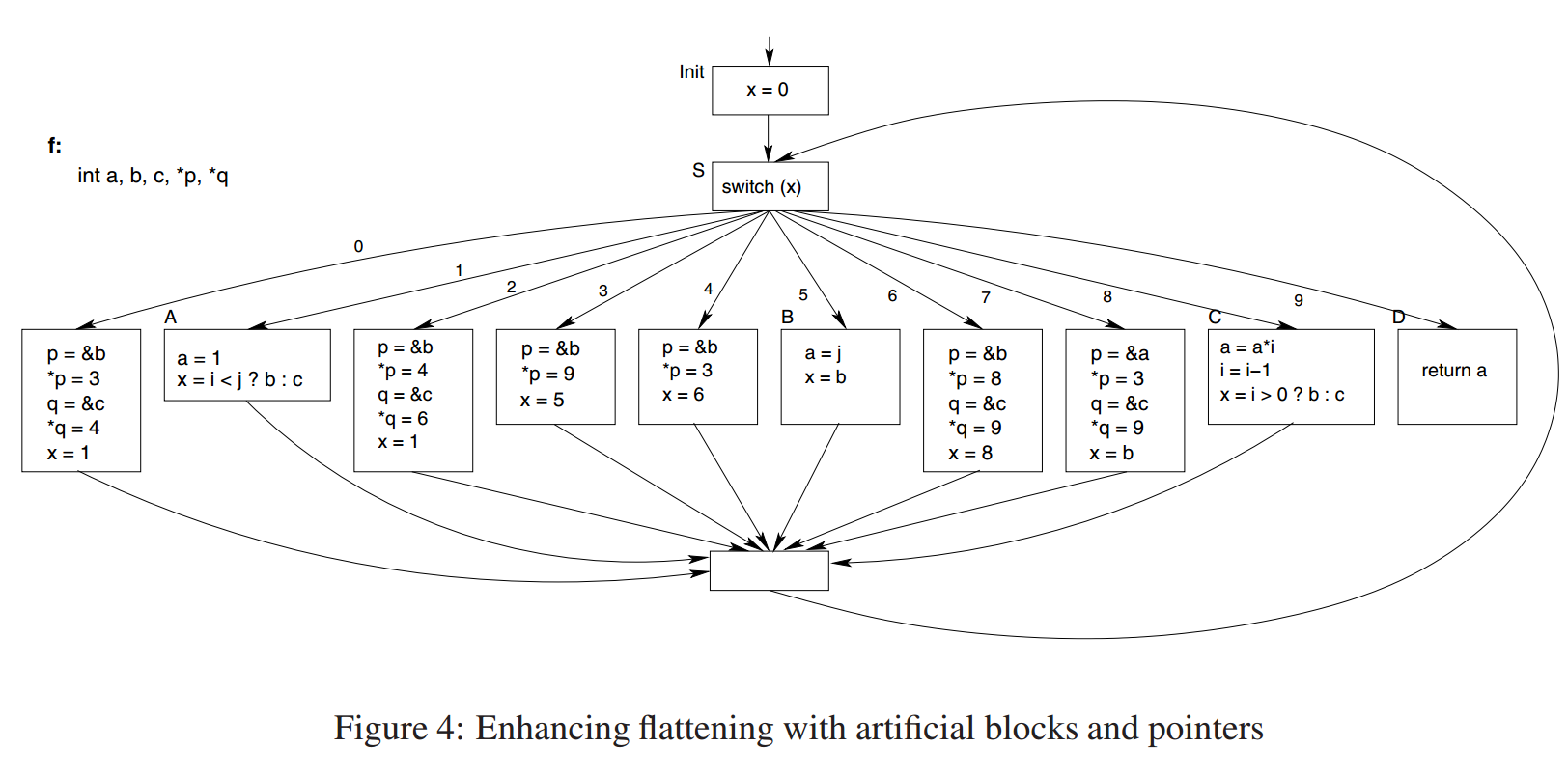
通过在控制流图中添加人工基本块,可以扩展上述模糊技术。其中一些人工块永远不会被执行,但由于混淆代码中动态计算的间接分支目标,很难通过程序的静态检查来确定。
然后,我们通过指针将间接加载和存储添加到这些不可访问的块中。这些会混淆关于调度变量可能取值的静态分析。图4显示了将此应用于图1的程序的结果。
在我们的实现中,我们对原始函数中的每个块相应地添加了2个人造基本块:其中一个块实际上是在运行时执行的,而另一个只是为了误导静态分析而添加的诱饵。给定原始程序中的块B,让执行的相应人造块由B'表示,诱饵人造块为B''。基于指针的间接赋值在被这两个人造块中均存在。然而,只有B'中的赋值将调度变量设置为合适的值,以便在执行过程中提供正确的控制流;而诱饵块B''将调度变量设置为其他值,从而对控制流产生误导。在原始块B中,加载的调度变量的值是之前在人工块B'中分配的值。隐藏开关变量的起始值会使静态分析器更难推断出执行了哪些块,从而找出开关变量的有效定义。
3. Deobfuscation
本节描述了一些我们发现对混淆代码的逆向工程有用的分析和程序转换。
3.1 Cloning
许多混淆技术依赖于在程序中引入虚假执行路径来阻止静态程序分析[4,8]。这些路径在运行时永远无法采用,但在程序分析过程中会导致虚假信息沿着它们传播,从而降低了所获得信息的精度,使理解程序逻辑变得更加困难。如图5(a)所示,信息沿着“实际”控制流路径1和伪控制流路径2在基本块a和B之间传播,后者是由混淆器引入的。然后,沿着2传播的虚假数据流信息会在执行路径汇集的点上导致程序分析结果的不精确性。在图5(a)中,正向数据流分析的结果(如达到定义)在B的入口处受到污染,而反向分析的结果,如活性分析,在a的出口处受到影响。
解决这个问题的一种方法是克隆程序的一部分,使伪执行路径不再与原始执行路径连接,并污染从分析中获得的信息。将克隆应用于图5(a)中的基本块B的结果如图5(b)所示。在这种情况下,这会导致B入口处可用的前向数据流信息得到改善。然而,在这个例子中,克隆并没有消除虚假的控制流边缘A→B',因此也没有改善A出口处可用的后向数据流的信息。
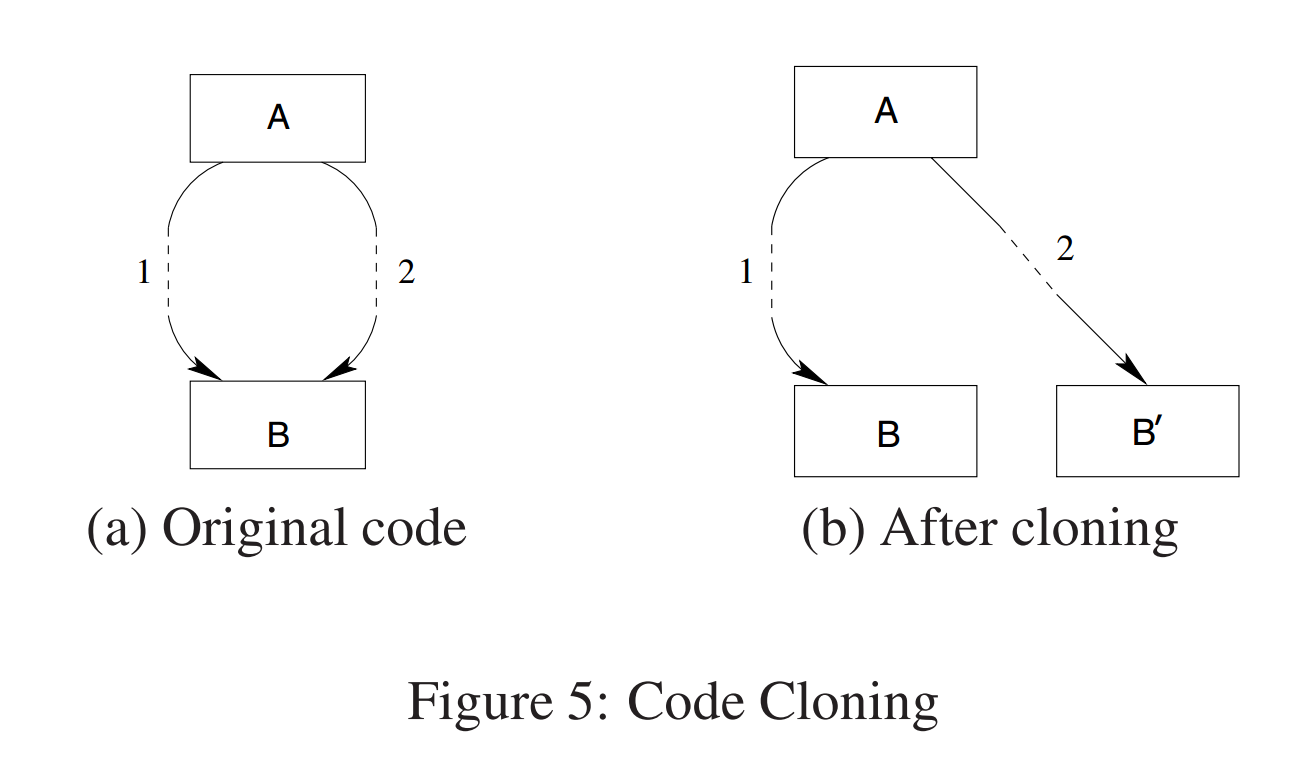
这种转换显然必须谨慎应用,否则会导致代码大小的大幅增加,并进一步加剧逆向工程问题。此外,由于去模糊的目标是尝试识别和删除混淆代码,这意味着一般来说,克隆必须在不提前知道哪些执行路径是虚假的,哪些不是的情况下应用。在这种情况下,一种可能的方法是在多个控制流路径连接的点上选择性地应用克隆,并且沿着某些路径传播的数据流信息的精度明显低于沿着其他路径传播的信息。或者,如果我们知道所应用的混淆类型,就有可能以利用这些信息的方式应用克隆。例如,由于其产生的独特控制流图,可以相对直接地推断出已经应用了控制流扁平化。
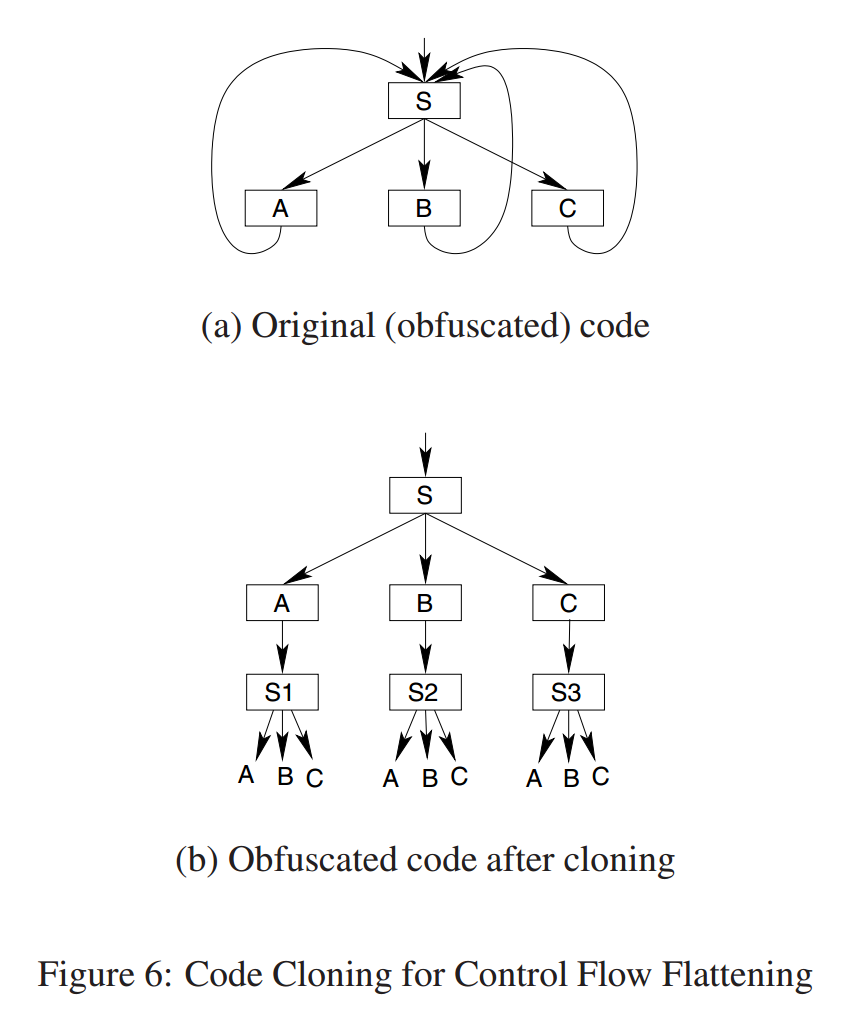
为了本文的目的,我们在我们的一个debuscator实现的上下文中使用克隆(见第4.1节),如图6所示。考虑图6(a)中所示的模糊程序片段,其中基本块a、B和C都将控制权转移到交换块S。克隆创建了交换块S的三个副本S1、S2和S3,分别对应于后续的a、B、C。这些副本中的每一个的控制流继承者都是原始交换块的一组控制流继承人,即每个副本S1、S2和S3都有一条到块A、B和C的边。在图6(B)所示的最终程序中,进入交换块S1的数据流信息不会与从B进入交换块S2的数据流或从C进入交换块S3的数据流混合。
3.2 Static Path Feasibility Analysis(静态路径可行性分析)
我们使用术语静态路径可行性分析来指代基于约束的静态分析,以确定(非循环)执行路径是否可行。给定一个非循环执行路径π,其中变量集位于π的入口处,我们的想法是构造一个约束满足逻辑公式(∃)只有在程序的所有可能执行中π都从未执行的情况下才不满足。因此,是对沿π执行指令的影响的保守近似。如果(∃)Cπ可以被证明是不可满足的,我们可以得出结论,π是不可行的。
原则上,我们可以想象许多不同的方法来构造与路径π对应的约束。就本文而言,我们的目标是考虑算术运算对变量值的影响,有效地获得类似于常数传播的分析,但沿着单个执行路径而不是沿着所有执行路径传播信息。为此,我们使用线性算术约束来推理变量值。下面的讨论假设了一种低级程序表示,例如三地址码、RTL甚至机器指令。
假设程序中的每条指令都有唯一的名称 。变量 在路径 起始处的值记为 ,而在路径中间的某个点,紧接着执行指令 之后的变量 的值记为 。未知的值用符号 表示。约束 被构造为路径 上每条指令 所对应的约束 的合取形式:
赋值语句(Assignment):若 ,则
其中 表示路径 中在 之前最近一次定义 的指令(若在 之前没有定义过 ,则 )。
算术语句(Arithmetic):若 ,其中 表示某种操作, 和 分别表示路径中最近一次定义 和 的指令(如果路径上还未定义 或 ,则 或 ),那么:
其中 表示操作 的语义函数。如果分析器无法识别 的语义,或者 或 ,则有:
间接引用(Indirection):指针可以在不同精度级别上建模,不同的精度带来了分析速度上的权衡 [14]。关于指针分析的完整讨论超出了本文的范围;我们仅要求对指针的处理具有保守性,即:在分析过程中指针的可能目标集合应该包含程序任意一次执行中指针的实际目标集合。
分支(Branches):若 ,其中 是一个布尔表达式,在这种情况下:
无条件分支可以被视为 的特殊情况;而多路分支(如
switch语句)可以被建模为一系列语义等价的条件分支。其他情况:如果分析器无法建模某条指令 的效果,则分析将在该处中止,并且系统保守地假设路径 是一个可行路径。
一旦约束 以这种方式构造完成,就会使用一个约束求解器来判定其是否可满足。所生成的这些约束可以通过路径切片技术(path slicing techniques)[15] 进行简化,以降低可满足性测试的开销;我们当前的实现使用 Omega calculator [23] 进行可满足性测试,但目前尚未采用这种简化技术。
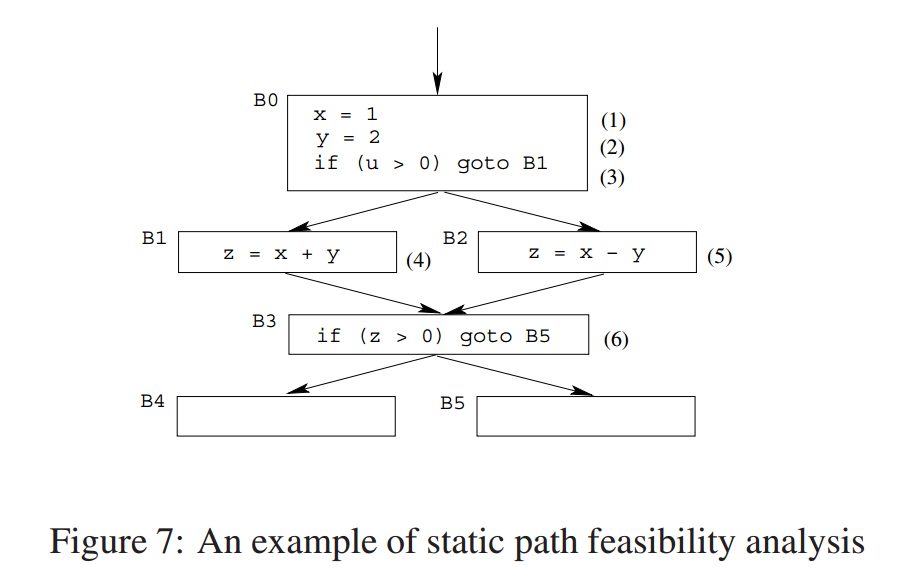
图 7 展示了如何在静态路径可行性分析中使用约束。每个基本块右上角的括号数字用于标识不同的指令。考虑路径 。在此路径的入口处,唯一相关的活动变量是 。该路径对应的约束 为:
很容易看出,该约束是不可满足的,因此路径 是不可行的。需要注意的是,传统的常量传播(constant propagation)会在进入 B3 基本块时得到 ,从而得出路径 是可行的结论。
还需要注意,这个例子也可以通过克隆基本块 B3 来处理,这样可以防止因控制流在边 和 合并时丢失信息。在克隆之后,常量传播将会得到预期的结果。因此,路径可行性分析与基本块克隆可以被视为互补的技术。
3.3 静态分析 + 动态分析
传统的静态分析,如第3.2节的分析,本质上是保守的,因此纯静态去模糊技术产生的边集通常是实际边集的超集。相反,动态分析(如程序追踪或边分析)不能考虑程序的所有可能输入值,因此只能观察到其所有可能执行路径的一个子集。
这两种程序分析方法的互补特性提示我们可以尝试将它们结合起来。这可以通过两种方式实现:一种方法是以动态分析获得的控制流边的一个 下近似(underapproximation) 为起点,再通过静态分析补回可能会被执行的控制流边;另一种方法是从静态分析获得的控制流边的一个 上近似(overapproximation) 出发,再通过动态分析剔除那些实际上不会被执行的边或路径。
但要注意,合并静态分析和动态分析后的结果可能包含比原始程序更多或更少的边,即在精确性和正确性之间无法保证。然而,从逆向工程和程序理解的角度看,这种混合分析对于克服纯静态或纯动态分析的局限性是非常有价值的。
本文所描述的工作采用静态分析来改善动态分析的结果,方法是在动态分析结果上添加回一些可能会被执行的控制流边。我们方法背后的核心思想源自一个思想实验(gedankenexperiment):假设我们以某种方式知道了哪些控制流边在实际执行中会被走到,那么我们就可以只标记这些边,并且仅在这些已知会被走到的边上传播数据流信息。这样,就避免了将信息传播到那些运行时永远不会执行的边上,从而获得更精确的分析结果。
传统的静态分析可以被看作是一种“所有边都被标记”的退化情况(degenerate case)。我们可以通过使用动态分析来识别在执行过程中实际占用的边,并仅标记这些边,然后沿着这些标记的边传播数据流信息,从而改善这种情况,如下所示:
初始时,仅标记那些被动态分析识别为“在执行中被实际走到”的控制流边。
在程序上执行常量传播(constant propagation),仅沿着被标记的边传播信息。
如果遇到一个条件分支,在执行过程中仅有一个出口控制流边被实际执行,但从常量传播的角度无法唯一确定该分支的结果,那么就应当将未被执行的那个分支边也加入控制流边集合中,并将其标记为“可能可达”。
在我们的实现中,这种方法的效果是修剪传播到开关块中的数据流信息。例如,考虑以下控制流片段,其中实线箭头表示在执行过程中获取的控制流边,而虚线箭头对应于从未获取的边:
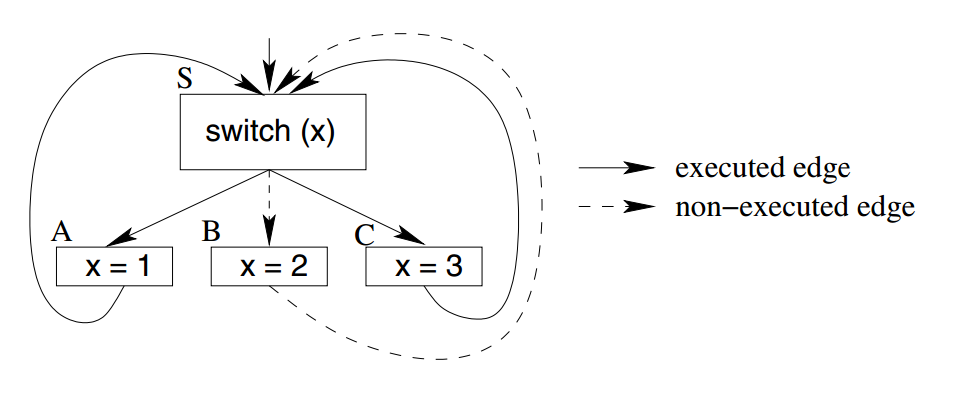
在这个例子中,基本块B永远不会执行,因此控制流边S→B和B→S没有标记,也没有沿着它们传播的信息。因此,在静态分析中不考虑块B中的赋值“x=2”;这导致值2不被认为是开关处变量x的可能值。
4. 实验评估
我们使用两种不同的二进制重写系统对 Intel x86 平台上的想法进行了评估:PLTO [24] 和 DIABLO [10]。我们在这两个工具中实现了 Wang 博士论文中所描述的三种控制流扁平化(control flow flattening)混淆技术(第2节中已有讨论),并使用这些技术对 SPECint-2000 benchmark suite中的十个程序进行了混淆处理。尽管这些程序是用 C 语言编写的,我们的实验是在程序的二进制文件上进行的。
我们对每个基准程序都使用 gcc 版本 3.2.2 进行编译,优化级别为 -O3,并使用了其他命令行参数以生成静态链接的可重定位二进制文件,然后再使用上述混淆器对这些二进制文件进行处理。包含 switch 语句的函数(间接跳转产生的跳转)未被混淆,因为我们当前的混淆器尚无法处理这些控制流。
标准库函数也被排除在外,因为在大多数情况下,这些函数包含非标准控制流,例如控制从一个函数跳转到另一个函数但未使用正常的调用/返回机制(call/return)来进行跨过程控制流传递。
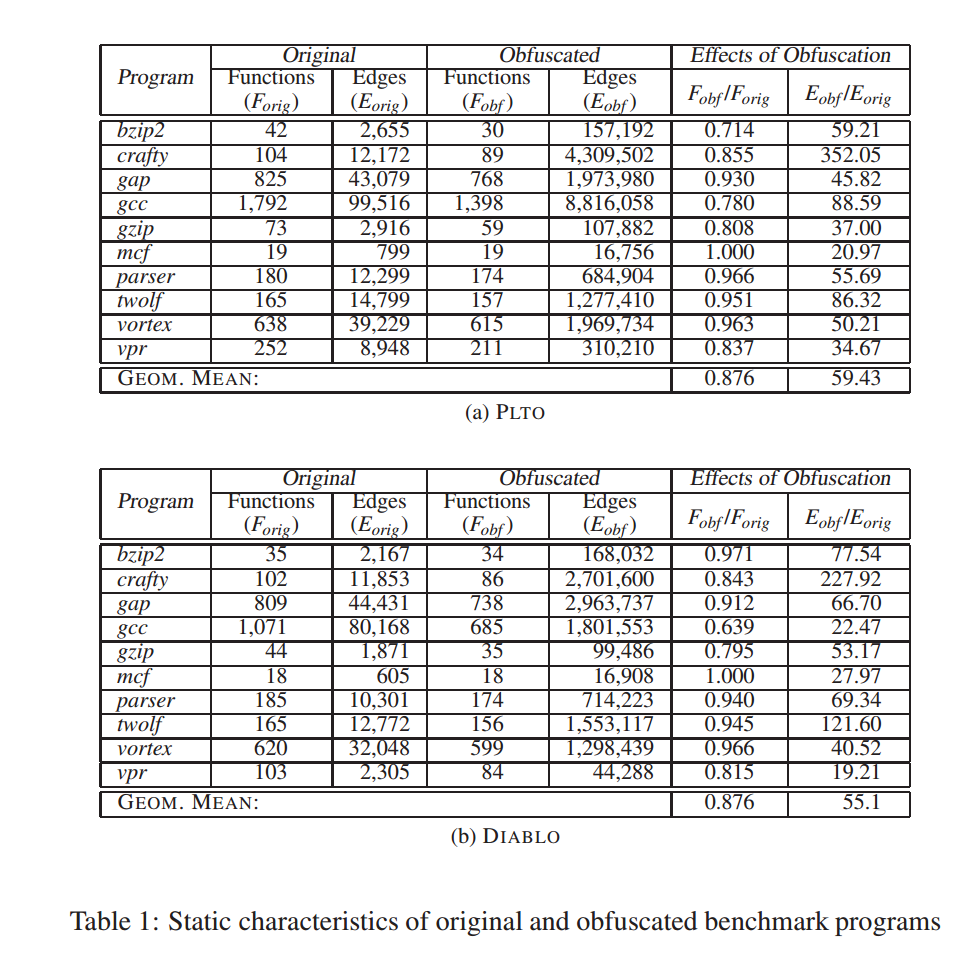
这些基准程序的静态特征在表1中进行了展示,该表比较了原始程序与应用基本控制流扁平化之后程序的差异。总体而言,表1 显示我们的工具能够混淆程序中大多数用户函数(平均约为 88%)。
正如预期的那样,混淆会导致控制流边的数量显著增加,尽管我们事先预估过,但实际增加的规模——大约为 55 到 60 倍——仍超出了我们的预期。
控制流反混淆(Control flow deobfuscation)涉及到删除由混淆器添加的伪造控制流边。为了评估不同反混淆技术的有效性,我们将反混淆后的程序 与原始程序 进行比较,以识别反混淆器在删除控制流边过程中可能出现的错误。
原则上,可能出现两种类型的错误:
- 第一种: 包含某些边,而这些边在 中并不存在;
- 第二种: 不包含某些原本存在于 中的边。
我们将第一类错误称为过度估计错误(overestimation errors),记作 ;将第二类错误称为低估错误(underestimation errors),记作 。
公式如下:
由于反混淆器的输入是混淆后的程序,我们将过度估计和低估的错误数按混淆程序中边的总数量进行归一化表达。
4.1 Basic Flattening
我们首先考虑使用第2.1节中描述的基本控制流扁平化技术混淆的程序。事实证明,使用纯静态技术进行去模糊处理很简单。我们考虑了两种不同的方法:DIABLO实现使用克隆和传统的常量传播来消除控制流的歧义;PLTO的实现使用了基于约束的路径可行性分析。
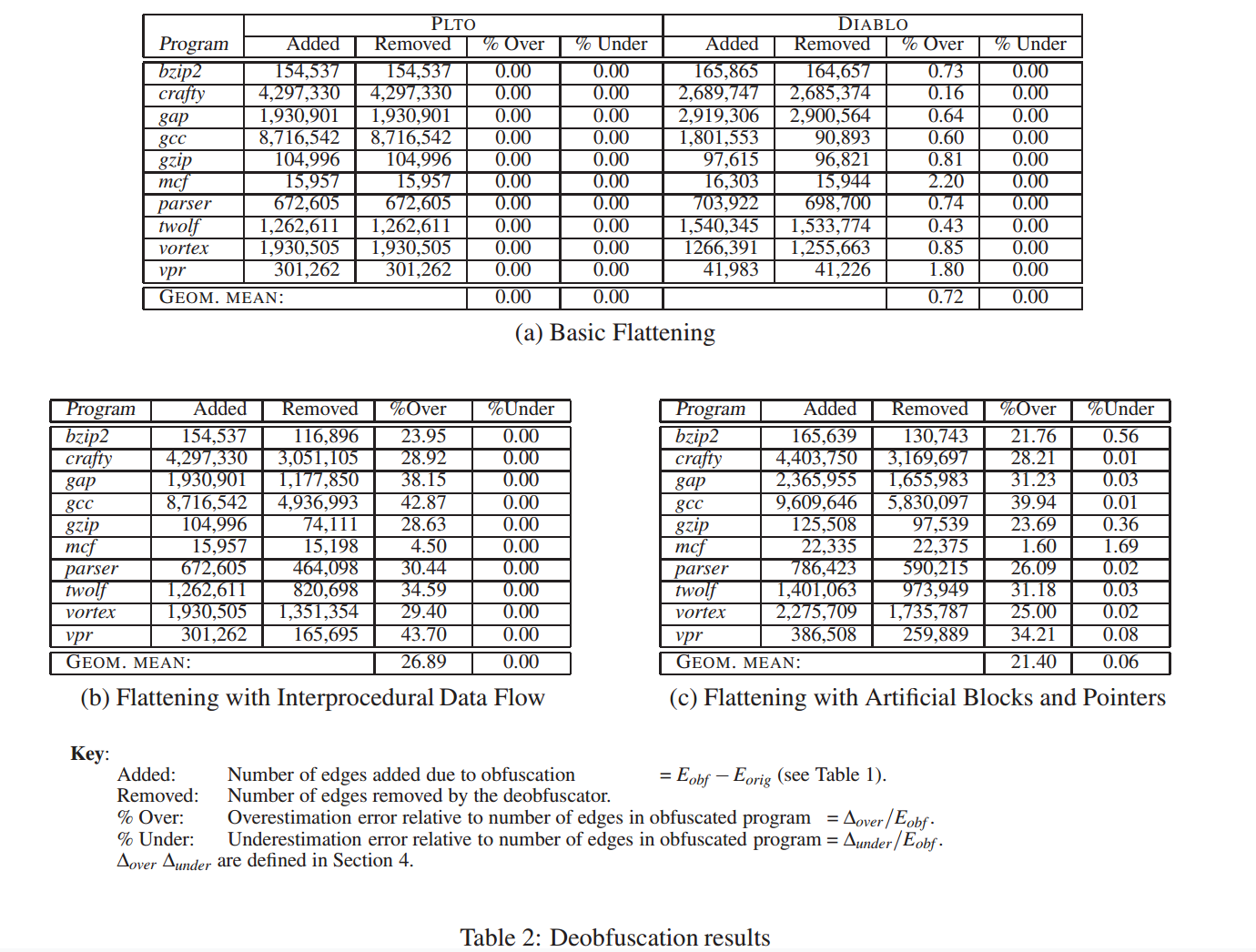
反混淆结果如表2(a)所示。
对于我们的每个实现,我们考虑两个指标:反混淆的程度,即我们能够通过反混淆过程去除的混淆边的数量;以及精度,如上所述,它给出了高估和低估的边的数量。可以看出,使用基于约束的路径可行性分析的PLTO实现能够完全恢复原始程序,没有任何错误。DIABLO实现使用代码克隆和恒定传播,能够删除99%以上的混淆边,但仍然存在少量的高估误差(平均0.72%)。这在很大程度上是所使用的程序转换的产物:克隆过程在程序中引入了许多额外的控制流边,而这些边并没有被不断的传播完全消除。
事实证明,通过活性分析和跳跃链折叠的额外阶段(即,跳跃到最终目标的单个跳跃取代了连续跳跃),可以很容易地消除其中的大多数。然而,我们这样做并不是为了本文的目的。
4.2 Flattening with Interprocedural Data Flow
为了使用过程间数据流进行扁平化,我们只使用了PLTO实现,单独使用静态路径可行性分析,并结合动态执行跟踪。
在这种情况下,由于我们的路径可行性分析本质上纯粹是程序内的,因此无法实现任何反混淆。
当静态分析与动态追踪(dynamic tracing)结合使用时,效果会更好。表 2(b) 中展示了相关结果。
反混淆后的程序仍然存在一定的过度估计错误,从 mcf 基准程序的 4.5% 到 vpr 的 43.7%,整体平均为 26.9%。在所有基准测试中都没有出现低估错误(underestimation error)。
值得注意的是,尽管底层的静态分析仅为过程内分析(intra-procedural),本身并不具有反混淆效果,但将其与动态分析结合后,可以消除 的混淆边,说明其具有显著作用。
需要强调的是,静态与动态分析的结合仅对“实际在测试输入中被执行”的函数有意义。对于那些在测试输入中未被执行的函数,我们不会删除其任何边,其所有混淆边都将被计入表 2(b) 中的过度估计误差。
4.3 Flattening with Artificial Blocks and Pointers
为了使用人造块和指针进行扁平化,我们再次仅使用PLTO实现,使用静态路径可行性分析本身以及与动态执行跟踪相结合。
静态路径可行性分析无法消除这种情况,因为它目前不处理通过指针的间接内存访问。
当将静态分析与动态分析结合使用时,反混淆效果进一步提升。相关结果如表 2(c) 所示。
在该表中,列标题为 “Added” 的数值与表 2(b) 中的对应值不同,这是因为在该实验设置中引入了人工基本块,从而增加了部分额外的控制流边。
与使用跨过程数据流(interprocedural data flow)进行扁平化时的情况类似,所有在测试输入中未被执行的函数的混淆边仍被计入过度估计误差中。
过度估计误差范围从 mcf 的 1.6% 到 gcc 的接近 40%,整体平均为 21.4%。
在本次设置中,还存在少量的低估误差,范围从 crafty 和 gcc 的 0.01% 到 mcf 的 1.7%,整体平均为 0.06%。
换言之,反混淆器在此实验中总共消除了: 的混淆控制流边。
4.4 Deobfuscation Time
基于 PLTO 的反混淆器在处理基本控制流扁平化(basic control flow flattening)时所耗费的总时间,从 mcf 的约 7 秒(约束生成耗时:2.5 秒;约束求解耗时:4.5 秒)到 gcc 的约 21 分钟(约束生成耗时:631.5 秒;约束求解耗时:640.1 秒)不等。
对于两种增强版本的混淆方案,其耗时也类似:
- **跨过程数据流(interprocedural data flow)**的处理时间范围为 7 秒到 22 分钟;
- **人工基本块与间接引用(artificial blocks and indirection)**的处理时间范围为 8.5 秒到 24 分钟。
5. Related Work
在逆向工程混淆代码方面,似乎没有大量的前期工作。Kapoor[16]和Kruegel等人[18]讨论了反汇编混淆二进制文件的算法。Lakhotia和Kumar讨论了处理二进制文件中模糊过程调用的技术[19,20]。这些作品的重点以及使用的技术与这里描述的非常不同。
许多研究人员考虑过将动态分析单独或与静态分析结合用于逆向工程[17,26,28];Stroulia和Syst¨a给出了概述[26]。这项工作的大部分重点是处理遗留软件,例如,用于确定模块化和语义聚类或理解高级设计模式,以及用于可视化动态系统行为。所有这些都与本文所述的工作有着根本的不同,本文的双重目的是识别有助于对混淆代码进行逆向工程的技术,以及评估代码混淆技术的优缺点。特别是,我们的工作重点是使用简单的静态和动态分析来逆向工程程序,这些程序是专门为使逆向工程变得困难而设计的。
Ernst[11]讨论了静态和动态分析相结合的想法。
6. Conclusions
许多研究人员提出了代码混淆作为一种使软件逆向工程变得困难的手段。混淆转换通常依赖于对某些类型的程序属性进行静态推理的理论难度。然而,本文表明,通过静态和动态分析的结合,可以绕过一些混淆的大部分影响。特别是,我们研究了消除控制流扁平化影响的问题,这是一种在研究文献中提出并用于商业代码混淆工具的控制混淆技术。我们的结果表明,使用纯静态技术可以以相对简单的方式消除基本的控制流扁平化,而使用静态和动态技术的组合可以在很大程度上消除对基本技术的增强。
References
[1] G. Arboit. A method for watermarking java programs via opaque predicates. In Proc. 5th. International Conference on Electronic Commerce Research (ICECR-5), 2002.
[2] L. Badger, L. D’Anna, D. Kilpatrick, B. Matt, A. Reisse, and T. Van Vleck. Self-protecting mobile agents obfuscation techniques evaluation report. Technical Report Report No. #01-036, NAI Labs, March 2002.
[3] S. Chandrasekharan. An evaluation of the resilience of control flow obfuscations. Undergraduate Honors Thesis, Dept. of Computer Science, The University of Arizona, Dec. 2003.
[4] W. Cho, I. Lee, and S. Park. Against intelligent tampering: Software tamper resistance by extended control flow obfuscation. In Proc. World Multiconference on Systems, Cybernetics, and Informatics, 2001.
[5] S. Chow, Y. Gu, H. Johnson, and V. A. Zakharov. An approach to the obfuscation of control-flow of sequential computer programs. In Proc. 4th. Information Security Conference (ISC 2001), Springer LNCS vol. 2000, pages 144–155, 2001.
[6] C. Collberg, G. Myles, and A. Huntwork. Sandmark – a tool for software protection research. IEEE Security and Privacy, 1(4):40–49, July/August 2003.
[7] C. Collberg and C. Thomborson. Software watermarking: Models and dynamic embeddings. In Proc. 26th. ACM Symposium on Principles of Programming Languages, pages 311–324, January 1999.
[8] C. Collberg and C. Thomborson. Watermarking, tamper-proofing, and obfuscation – tools for software protection. IEEE Transactions on Software Engineering, 28(8), August 2002.
[9] C. Collberg, C. Thomborson, and D. Low. A taxonomy of obfuscating transformations. Technical Report 148, Department of Computer Sciences, The University of Auckland, July 1997.
[10] B. De Bus, B. De Sutter, L. Van Put, D. Chanet, and K. De Bosschere. Link-time optimization of arm binaries. In Proc. 2004 ACM Conf. on Languages, Compilers, and Tools for Embedded Systems (LCTES’04), pages 211–220, 7 2004.
[11] Michael D. Ernst. Static and dynamic analysis: Synergy and duality. In WODA 2003: ICSE Workshop on Dynamic Analysis, Portland, OR, pages 24–27, May 2003. [12] D. Evans and D. Larochelle. Improving security using extensible lightweight static analysis. IEEE Software, 19(1):42–51, January/February 2002.
[13] S. Guyer and K. McKinley. Finding your cronies: Static analysis for dynamic object colocation. In Proc. OOPSLA’04, pages 237–250, October 2004.
[14] M. Hind and A. Pioli. Which pointer analysis should I use? In Proc. 2000 ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 113–123, 2000.
[15] R. Jhala and R. Majumdar. Path slicing. In Proc. ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pages 38–47, June 2005.
[16] A. Kapoor. An approach towards disassembly of malicious binaries. Master’s thesis, University of Louisiana at Lafayette, 2004.
[17] R. Kazman and S. J. Carri`ere. Playing detective: Reconstructing software architecture from available evidence. Automated Software Engineering: An International Journal, 6(2):107–138, April 1999.
[18] C. Kruegel, W. Robertson, F. Valeur, and G. Vigna. Static disassembly of obfuscated binaries. In Proc. 13th USENIX Security Symposium, August 2004.
[19] E. U. Kumar, A. Kapoor, and A. Lakhotia. DOC – answering the hidden ‘call’ of a virus. Virus Bulletin, April 2005.
[20] A. Lakhotia and E. U. Kumar. Abstract stack graph to detect obfuscated calls in binaries. In Proc. 4th. IEEE International Workshop on Source Code Analysis and Manipulation, pages 17–26, September 2004.
[21] C. Linn and S.K. Debray. Obfuscation of executable code to improve resistance to static disassembly. In Proc. 10th. ACM Conference on Computer and Communications Security (CCS 2003), pages 290–299, October 2003.
[22] T. Ogiso, Y. Sakabe, M. Soshi, and A. Miyaji. Software obfuscation on a theoretical basis and its implementation. IEEE Trans. Fundamentals, E86- A(1), January 2003.
[23] W. Pugh. The Omega test: a fast and practical integer programming algorithm for dependence analysis. Comm. ACM, 35:102–114, August 1992.
[24] B. Schwarz, S. K. Debray, and G. R. Andrews. Plto: A link-time optimizer for the Intel IA-32 architecture. In Proc. 2001 Workshop on Binary Translation (WBT-2001), 2001.
[25] Preemptive Solutions. Dotfuscator. www.preemptive.com/products/dotfuscator.
[26] E. Stroulia and T. Syst¨a. Dynamic analysis for reverse engineering and program understanding. ACM SIGAPP Applied Computing Review, 10(1):8–17, 2002.
[27] Symantec Corp. Understanding and managing polymorphic viruses. Technical report, 1996.
[28] T. Syst¨a. Static and Dynamic Reverse Engineering Techniques for Java Software Systems. PhD thesis, Dept. of Computer and Information Sciences, University of Tampere, Finland, 2000.
[29] C. Wang, J. Davidson, J. Hill, and J. Knight. Protection of software-based survivability mechanisms. In Proc. International Conference of Dependable Systems and Networks, July 2001.
[30] Chenxi Wang. A Security Architecture for Survivability Mechanisms. PhD thesis, Department of Computer Science, University of Virginia, October 2000.