EVOC2RUST: A Skeleton-guided Framework for Project-Level C-to-Rust Translation
EVOC2RUST: A Skeleton-guided Framework for Project-Level C-to-Rust Translation
论文来自 arXiv预印本
摘要
Rust 在编译期提供的安全性保证,使其非常适合用于安全关键系统,因此对将遗留的 C 代码库迁移到 Rust 的需求不断增长。尽管已有多种方法被提出来完成这一任务,但它们都存在固有权衡:基于规则(rule-based)的方法在满足代码安全性与 Rust 习惯用法方面面临挑战;而基于大语言模型(LLM)的方法由于整个代码库中模块之间存在大量依赖,常常无法生成语义等价的 Rust 代码。近期研究表明,这两类方案都主要局限于小规模程序。
本文提出 EVOC2RUST,一个用于将整套 C 项目自动转换为等价 Rust 项目的框架。EVOC2RUST 采用一种由骨架(skeleton)引导的项目级翻译策略。其流水线包含三个“进化式”的阶段:
- 首先将 C 项目分解为功能模块,使用特征映射(feature mapping)增强的 LLM 来转换定义与宏,并生成通过类型检查的函数桩(stub),从而形成可编译的 Rust 骨架;
- 随后增量式地翻译各个函数,用翻译结果替换相应的桩占位符;
- 最后通过结合 LLM 与静态分析来修复编译错误。
凭借这种进化式增强,EVOC2RUST 结合了基于规则方法与基于 LLM 方法的优势。我们在开源基准与六个工业级项目上的评估表明,EVOC2RUST 在项目级 C→Rust 翻译上具有更优性能:平均而言,相比基于 LLM 的方法,语法与语义准确率分别提升 17.24% 与 14.32%;相比基于规则的工具,代码安全率提高 96.79%。在模块级上,即使面对复杂代码库与长函数,EVOC2RUST 在工业项目上仍可达到 92.25% 的编译通过率与 89.53% 的测试通过率。
索引词
C-to-Rust Conversion, Project-level Code Translation, Skeleton Guided, Feature Mapping, Large Language Models
1. 引言
将遗留的 C 代码库迁移为同等功能的 Rust 项目,已在软件工程领域成为强烈的现实需求 [1][2]。在实际生产环境中的 C 系统里,内存安全相关的漏洞是最常见的一类严重安全缺陷;来自 Google 与 Microsoft 的行业报告显示,这类漏洞约占高危漏洞的 70% 左右 [3]。这一共识推动了工程实践的范式转变:转向通过安全的编程语言在编译期提供严格的安全保证 [4]。作为回应,现代系统编程语言 Rust 崭露头角,凭借在编译期强制执行严格的所有权/借用模型,提供内存安全保障,成为领先的替代方案 [5]。
近期工作提出了基于规则(rule-based)的工具 [6]–[8],主要在一种简洁的编译中间表示上施行以语法为主的转换,将 C 代码转为 Rust。此类翻译天然容易生成不符合 Rust 惯用风格的低层次结构代码,且可能包含语义不准确之处 [9]。另一类工作采用基于大语言模型(LLM)的方法 [10]–[12],利用代码 LLM 的理解能力完成翻译。但由于缺乏成对(平行)的 C↔Rust 训练数据,且两种语言在语义/风格上差异显著,这些方法常常无法生成语义等价的 Rust 代码 [13]。尽管自动化代码翻译已被广泛研究 [14]–[16],项目级的 C→Rust 翻译仍面临特殊挑战:
挑战一:为保证安全而产生的显著“语言鸿沟”
C 与 Rust 在安全模型上存在根本差异:C 允许宽松的类型检查、不受限的指针运算以及手动内存管理;而 Rust 则在编译期强制执行严格的类型安全、基于所有权的内存安全保证,并通过借用规则约束引用的使用。现有基于规则的转换器常为达成功能而牺牲安全性,依赖裸指针、unsafe 块或外部 C 函数 [9]。基于 LLM 的方法虽能在一定程度上改进安全性,但常缺乏充分的上下文理解(例如变量作用域、指针生命周期等),可能导致逻辑错误或内存安全违规,使得译出的 Rust 代码仍不可靠 [17]。因此,单独依赖基于规则或基于 LLM 的方法,往往难以稳定满足 Rust 严苛的安全要求。
挑战二:项目级的代码依赖与结构一致性
将整个 C 项目完成迁移,远比翻译孤立函数更具挑战:译出的 Rust 项目必须保留跨模块依赖并维持一致的项目结构层级 [18][19]。代码类 LLM 往往难以处理如此大尺度的上下文,从而引发引用断裂、API 不一致或模块边界错误 [9]。结果是,现有方法多仅在小规模程序(例如 行代码)上表现良好 [10][20],在真实项目场景中表现不足。
在本文中,我们提出 EVOC2RUST:一个用于将完整 C 项目自动翻译为等价 Rust 代码的框架。为弥合语言差异并确保安全(对应挑战一),EVOC2RUST 以安全保持(safety-preserving)映射增强 LLM,覆盖七类核心语言要素:类型(types)、宏(macros)、函数(functions)、运算符(operators)、语法结构(syntax structures)、全局量(globals)以及可变参数(variadic arguments)。为实现项目级翻译(对应挑战二),EVOC2RUST 引入 骨架引导(skeleton-guided) 的三阶段翻译策略:
- 分析与分解:解析输入的 C 项目,抽取高层元数据,并将项目分解为功能模块;随后生成一个可编译的 Rust 骨架,其中各函数以 占位桩(stub) 形式存在。
- 增量式翻译:利用结合了上述特征映射的 LLM,逐步将这些函数桩翻译为具体实现,并替换骨架中的占位符。
- 迭代式修复:将 LLM 与静态分析结合,迭代修复编译错误并细化输出结果。
这种进化式流程有效融合了基于规则与基于学习两类方法的优势,在自动化 C→Rust 迁移中,于正确性与安全性之间取得务实平衡。
我们在一个名为 Vivo-Bench 的开源基准 [21],以及我们自建、包含 6 个工业级项目的数据集 C2R-Bench 上评估 EVOC2RUST。实验结果表明,EVOC2RUST 在项目级 C→Rust 翻译任务上显著优于各类基线方法。与基于 LLM的方法相比,EVOC2RUST 在编译通过率上平均提升 ,在行级接受率(line acceptance rate)上平均提升 ,同时代码安全性也略有优势。与基于规则的方法相比,EVOC2RUST 的代码安全率平均高出 ,而编译通过率与行级接受率仍保持在同一竞争水平。在模块级评测中,EVOC2RUST 在工业项目上的编译通过率达到 ,测试通过率达到 。我们的消融实验进一步验证了各组件在 EVOC2RUST 中的关键作用,其中安全保持映射(safety-preserving mapping)是该方法的基石。
主要贡献:
- 我们提出了一种面向项目级的 C→Rust 代码翻译新方法,兼顾语法正确性、语义等价性与内存安全性。
- 我们在 C 与 Rust 的核心语言要素之间定义了安全保持映射,以增强 LLM 的安全意识与约束遵循能力。
- 我们在开源场景与工业场景对 EVOC2RUST 进行了系统评测。结果显示,EVOC2RUST 整体优于现有基线,能够将 C 项目有效翻译为正确且安全的 Rust 代码。
2. 方法(APPROACH)
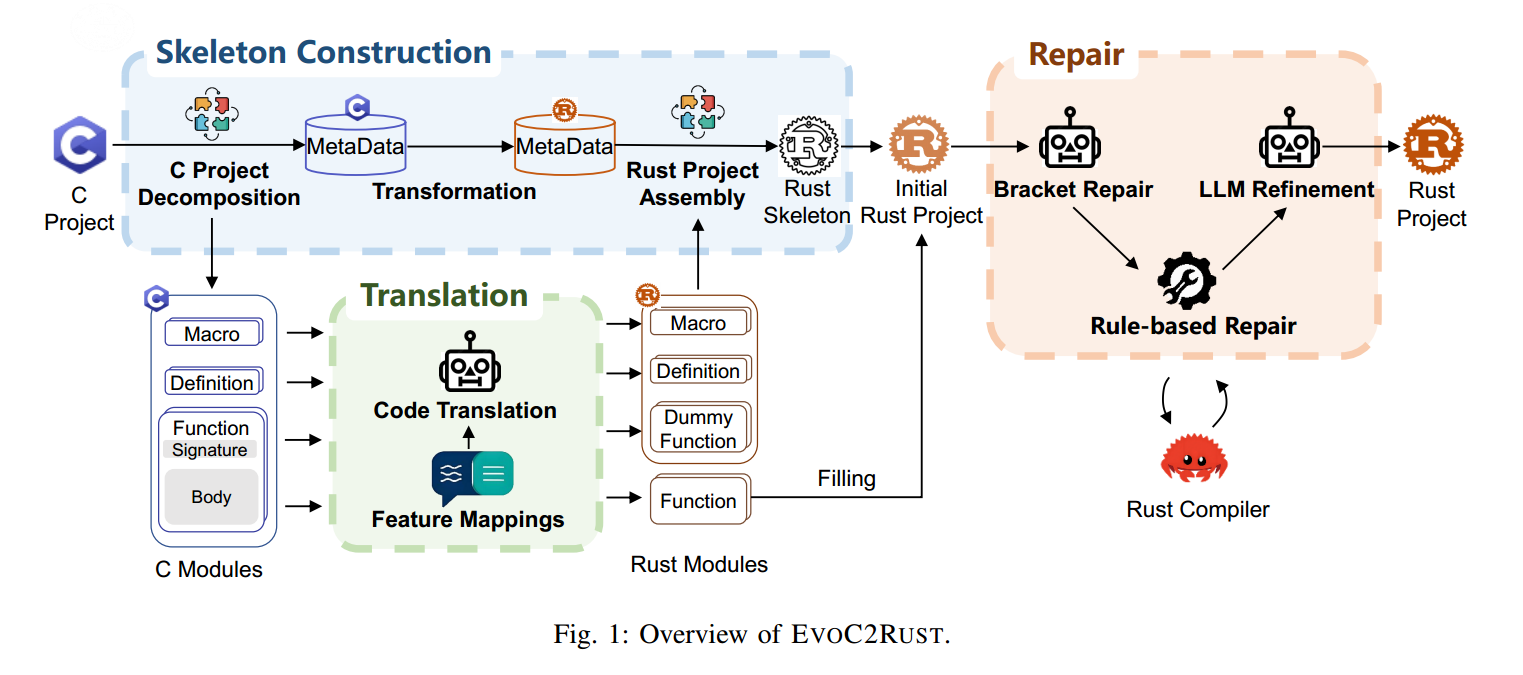
图 1 展示了 EVOC2RUST 的整体架构,包含三个关键步骤:(1)骨架构建(Skeleton construction):将 C 项目分解为模块,并构建一个用于组装 Rust 模块的 Rust 项目骨架(见 §II-A);(2)增量式翻译(Incremental translation):依据安全保持的语言映射翻译骨架中的各个模块(见 §II-B);(3)生成后修复(Post-generation repair):将基于 LLM 的细化与静态分析结合,用于代码优化(见 §II-C)。
A. 项目骨架构建(Project Skeleton Construction)
一种直接的项目级翻译思路是逐个函数翻译,再把它们汇总成项目。然而,天真地聚合已翻译的函数常会导致级联的相互依赖错误。为此,EVOC2RUST 采用骨架引导的策略:在项目元数据的指导下构建一个可编译的 Rust 项目骨架,并增量式地用已翻译的函数去填充它。
对给定的 C 项目,EVOC2RUST 使用 Tree-sitter [22] 解析函数签名、调用图、结构体与类型定义。这些元素被组织为项目元数据,包括:文件名、include 语句、宏定义、类型声明、全局标识符、函数签名,以及 “声明 ↔ 源文件” 的映射表。随后,这些元数据被系统化地通过基于规则的转换替换为 Rust 等价物。例如:C 的 include 依赖被转换为 Rust 的 use 导入;标识符声明被转换为 Rust 的 pub use 语句(如 pub use {Rust_filename}::{identifier_name}),其中文件名由声明到文件的映射表提供。
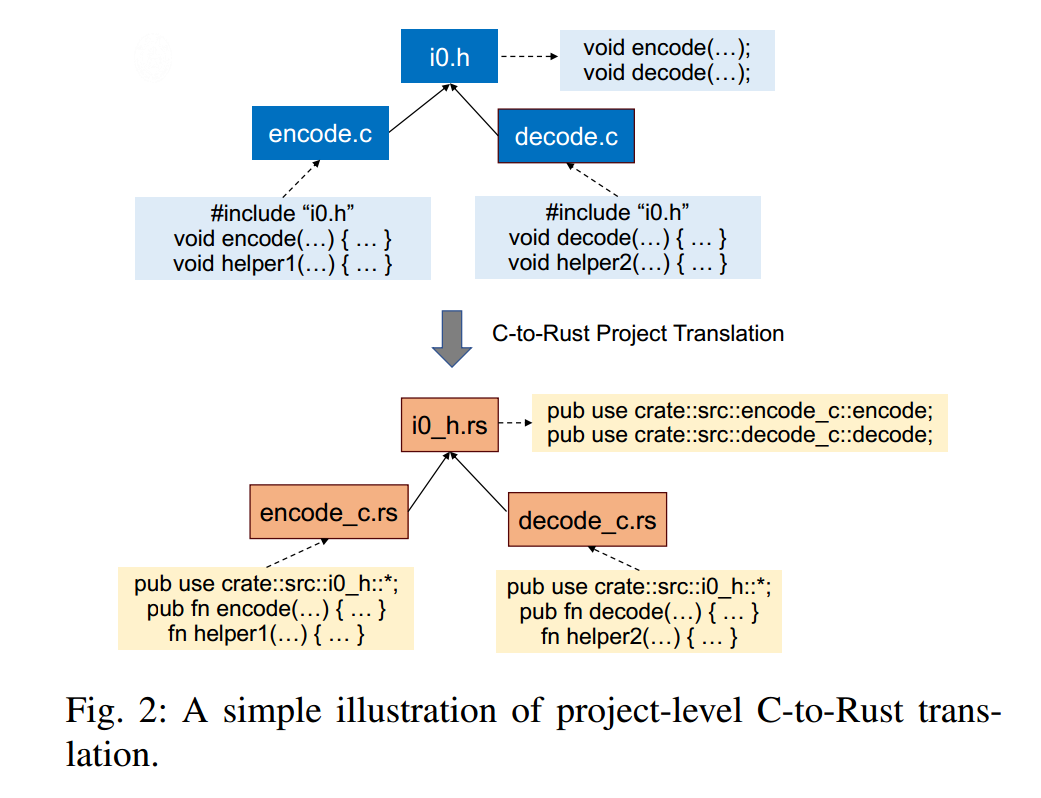
基于转换后的元数据,EVOC2RUST 构建了一个忠实保留原始 C 项目结构组织的 Rust 项目骨架(见图 2)。骨架由从 C 的定义、宏与函数签名自动翻译得到的 Rust 结构组成。每个 C 函数都会在 Rust 中分配一个通过类型检查的占位“哑函数”:其签名为翻译后的签名,函数体使用 unimplemented!() 宏占位。这样的占位符是安全的替身,即使函数体尚未翻译,项目也能先行通过编译。
这种骨架引导的做法,使得函数体可以被逐步翻译并插入,从而保证上下文正确性,并消除函数间依赖错误。因此,即便是具有复杂模块交互的大型项目,该流程也能平滑地支持翻译、编译与修复。
B. 基于安全保持映射的模块翻译(Module Translation with Safety-preserving Mapping)
EVOC2RUST 使用 LLM 将 C 模块自动翻译为 Rust 结构:先把定义、宏、函数签名转换出来以组装骨架,再把函数体翻译后填充骨架中的占位哑函数。为在翻译过程中保持安全与语义一致,EVOC2RUST 用一套全面的语言映射来增强 LLM,涵盖七大类:

类型映射(Type Mapping)。对每一种 C 类型,我们都建立了一个对应的 Rust 类型(见表I)。例如,我们引入
cstr!()宏来保证经由该宏得到的所有字符串都保持以空字节结尾(null-terminated)的性质,从而避免在加密/压缩算法中出现不一致。基于每种 C 类型可用的操作,我们在 Rust 中实现对应的操作。鉴于 C 的指针支持加减运算、取址和下标访问等,我们在 Rust 中实现了与之对应的 trait;对于 C 数组可衰变为指针的特性,我们允许数组通过cast()方法转换为指针类型。类型转换(Type Conversion)。我们实现了
CastIntoTypedtrait 来在 Rust 中执行类型转换,涵盖整数之间以及不同指针类型之间的转换;同时允许指针→整数(但禁止整数→指针)的转换。示例:a = (uint16_t)b可译为a = b.cast::<u16>();pi = (int*)pu可译为pi = pu.cast::<Ptr<i32>>()。由于 Rust 具备类型推断,我们也允许不带显式类型的cast()来模拟 C 的隐式转换。在修复阶段,当需要修正由隐式转换导致的类型错误时,无类型参数的cast()能显著提升 LLM 优化的成功率。宏/函数映射(Macro/Function Mapping)。对 C 的原生宏(如
NULL、__LINE__),我们提供 Rust 端的对等实现。对 C 的原生函数(如malloc、free、memcpy),我们实现等价功能的 Rust 函数,并优先采用安全方法,而非直接调用与之逐字对等但不安全的底层实现(例如用不安全的std::ptr::copy来实现memmove仅作为内部细节)。通过简明的提示,LLM 会遵循将原生 C 函数name()翻译为c_name!()宏的规则。
笔者注:简单地基于提示词实现?
语法结构映射(Syntax Structure Mapping)。Rust 的
for循环与 C 的for在行为上并不相同,直接逐字翻译可能带来语义错误;此外,C 的do while在 Rust 中没有直接等价物,而switch与 Rust 的match也存在差异,容易诱发逻辑错误。为此,我们实现了c_for!、c_do!、c_switch!等宏,以复现 C 的语法与逻辑;并通过提示引导 LLM 将原始语法翻译为这些宏。运算符映射(Operator Mapping)。我们为 C 特有的运算符在 Rust 中提供对应实现,包括
++、--、&与sizeof()。其中,sizeof()被映射为两个宏:c_sizeof!()与c_sizeofval!()。自增/自减被实现为四个函数(涵盖前缀与后缀),适用于所有整数与指针类型。我们还要求模型不要把&翻译为 Rust 的借用运算符&/&mut,而是翻译为获取当前值指针的c_ref!()宏。全局变量映射(Global Variable Mapping)。在 Rust 中使用可变的全局变量(
static mut)是不安全的,因此我们定义Global<T>类型来安全地管理全局量;其实现内部使用Mutex来保证线程安全,从而消除不安全代码的需求。我们还提供global!()宏以支持惰性初始化。
笔者注:能否明确地分析出线程安全无同步的情况(例如ThreadLocal)?
- 可变参数映射(Variadic Argument Mapping)。可变参数主要用于日志和字符串格式化。因此我们定义
VaList类型(本质为一个Slice,内部包含对多个实现了Displaytrait 的值的引用),并提供va_format!()宏用于字符串格式化。我们还利用可变参数来实现 C 函数(如snprintf)在 Rust 端的等价物。
上述特征映射均被表述为转换样式(pattern),每个样式明确给出其动机、影响、解决方案及对应代码示例(见表II)。通过凝练高级工程师的实践经验,这些样式把隐性专业知识固化为可复用的 C→Rust 迁移规则。

为引导 LLM 进行准确且合乎惯用法的翻译,我们会基于输入的 C 代码检索最相关的样式:具体而言,同时对输入片段与样例样式编码为稠密向量,计算余弦相似度,选出 Top-K 个最接近的样式。随后将这些样式注入到 LLM 提示词中,以如下结构化模板来约束其输出。
(提示模板)将 C 模块翻译为 Rust
将 C 的[macro/definition/function]翻译为 Rust。
Patterns(样式):{retrieved transformation patterns}
Demonstrations(示例):{paired C-to-Rust examples}
C Source Code(C 源码):{input source code}C. 生成后修复(Post-Generation Repair)
最终,EVOC2RUST 在编译驱动下对已翻译的 Rust 代码进行级联式修复:把基于 LLM的修补与语法规则相结合。对每段代码片段,它会依据编译器反馈生成多个修复候选,只保留那些能够减少错误计数的结果,并迭代直到无法进一步改进为止。
虽然基于规则的方法擅长处理琐碎且定义清晰的错误,而 LLM 更善于应对复杂问题,但我们观察到:一些持续存在的低层语法错误(例如括号/括弧不匹配)会严重削弱两种修复技术的效果,尤其会让确定性的规则修正束手无策。为此,EVOC2RUST 设计了三步修复链:
括号修复(Bracket Repair)
使用 LLM 分析编译输出与报错信息,以修正不匹配的括号及类似的语法问题。提示词包含:修复指南、错误/正确示例对、当前错误的 Rust 片段以及对应的编译错误。(提示模板)括号修复
请依据下述编译错误信息,修复下面这段 Rust 代码中的编译问题(可能由括号/圆括号不匹配引起)。 只修复“括号不匹配”的行,不要修改任何其它代码。 Demonstrations(示例对):{example pairs of incorrect/correct Rust code} Rust Source Code(Rust 源码):{input source code} Compilation Error Messages(编译错误信息):{input error messages}规则修复(Rule-Based Repair)
我们将常见的语法层问题抽象为一组基于正则的转换样式(修复规则),例如:derive宏的调整、去除冗余的cast()操作、以及修复像s[s.i]这类数组访问模式(它会同时触发可变/不可变借用冲突)等。LLM 细化(LLM Refinement)
最后一步继续借助 LLM 处理遗留的语义差异与更复杂的编译级问题,例如类型不一致、不符合惯用法的用法或结构性不一致。提示词包含:细化指南、示例修复对、错误的 Rust 翻译及其编译信息。(提示模板)LLM 细化
请依据以下编译信息,修复下面这段 Rust 代码中的编译问题: Instruction(细化指南):{refinement guidelines} Demonstrations(示例对):{example pairs of incorrect/correct Rust code} Rust Source Code(Rust 源码):{input source code} Compilation Information(编译信息):{input compilation information}
3. 实验设置(EXPERIMENTAL SETUP)
我们开展实验以评估 EVOC2RUST 的有效性,旨在回答以下研究问题:
- RQ1: EVOC2RUST 将完整 C 项目翻译为等价且安全的 Rust 项目有多有效?
- RQ2: EVOC2RUST 在模块级能够达到怎样的转换准确度?
- RQ3: EVOC2RUST 的关键组成模块对其整体性能的贡献程度如何?
A. 比较方法(Comparison Methods)
我们将 EVOC2RUST 与三类 C→Rust 翻译方法进行对比:基于规则(C2Rust)、基于 LLM(Self-Repair 与 Tymcrat)、以及混合技术(C2SaferRust)。此外,我们还引入不带仓库上下文的直接 LLM 生成作为基线。
具体而言,我们与以下基线进行对比评估:
- C2Rust [6]:一种基于规则的 C→Rust 翻译器,依赖 AST 分析与手工定义的转换规则完成迁移。
- C2SaferRust [23]:一种混合式方法,在 C2Rust 框架之上融合 LLM 驱动的后处理,并采用测试驱动的优化来提升生成 Rust 代码的惯用性与安全性。我们采用原工作默认配置,进行 5 轮优化迭代。
- Self-Repair [24]:一种多智能体自修复框架,面向项目规模的 C→Rust 翻译;在文件级翻译中引入迭代式编译-测试反馈以自动修错。我们使用默认设置:每个任务进行 3 轮自修复(含编译驱动与测试驱动两类修复)。
- Tymcrat [25]:一种项目级翻译方法,通过类型迁移、为每个函数生成多个候选 Rust 签名,并结合编译器反馈迭代解决类型错误,从而提高翻译质量。我们采用默认配置:每个函数输出 4 个候选签名。
- LLM-direct:一种零样本提示的直接 C→Rust 翻译基线。为缓解其在项目一致性与依赖解析方面的先天不足,我们将该方案嵌入到我们的项目骨架构建框架之中实现。
所有基线均基于其官方发布代码实现。为确保公平比较,我们将其原始主干模型统一替换为 DeepSeek-V3 [26]。
B. 评估策略与指标(Evaluation Strategy and Metrics)
我们在项目级与模块级两种粒度评估 C→Rust 翻译性能。
项目级评估(Project-level Evaluation)
我们在项目级翻译上与各基线进行对比。为模拟真实场景中缺少标准实现的情况,我们从基准中移除所有参考实现。评测遵循一种增量式的编译验证策略:先构建包含占位 Rust 模块的项目骨架,随后逐步以翻译代码替换这些占位模块,并在每次替换后进行编译验证;任一失败的模块会回退为原占位实现。
项目级性能通过三项指标衡量:
- Incremental Compilation Pass Rate(ICompRate):当模块被增量集成进项目骨架时,成功通过编译的模块比例,用以度量语法正确性(定义见 [18])。
- Line Acceptance Rate(AccRate) [27]:考虑到整个项目的编译难度,我们评估翻译代码与人工校正版本的一致性。Precision 统计初次翻译中未被修改的行,Recall 统计这些行在最终验证解中的保留情况。
- Code Safe Rate(SafeRate) [28]:生成 Rust 代码中内存安全语句所占的比例。
模块级评估(Module-level Evaluation)
我们进一步通过一种填空式验证策略评估模块级的转换准确度:对测试集中的每个 C 模块(如 Func_C),若存在已知的 Rust 等价实现(如 Func_R),则从 Rust 参考实现中移除 Func_R,使用翻译方法由 Func_C 生成 Func_R',将其集成到部分 Rust 项目中,并通过编译与测试用例验证其正确性。
模块级的语法与语义正确性通过两项指标衡量:
- Fill-in Compilation Pass Rate(FCompRate):当把生成模块替换至 Rust 参考实现中对应位置时,能够成功编译的模块比例。
- Test Pass Rate(TestRate) [24]:在上述替换条件下,能够通过全部对应测试用例的模块比例。
C. 数据集(Datasets)
我们在 Vivo-Bench [21] 开源数据集与自建的 C2R-Bench(包含 6 个工业级项目)上评估 EVOC2RUST。
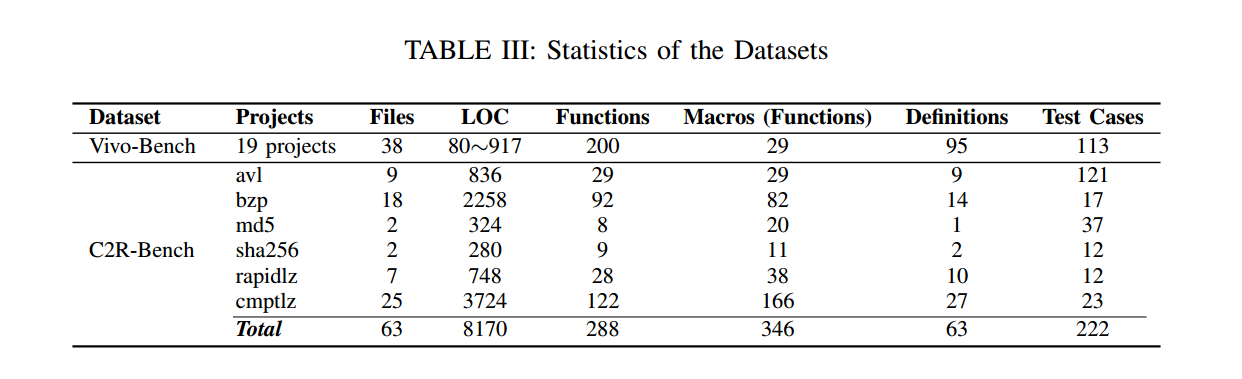
Vivo-Bench 来自 2025 Vivo C-to-Rust 创新竞赛,包含 19 个算法型 C 项目,覆盖 200 个函数、95 个定义与 29 个“非函数”宏。这些项目由 1–3 个文件组成,单文件代码行数(LOC)从 33 到 630 不等。两位 Rust 开发者在 LLM 的辅助下通过修错与补测,产出经验证的译文,确保函数级完整覆盖,共得到 113 个顶层测试用例。
为了评估工业场景,我们构建了 C2R-Bench:来自华为软件生态的 6 个生产级 C 项目的基准。所选项目均为单线程的用户态应用,仅依赖标准 C 库。这些项目具有多文件架构与显著的跨文件依赖,源码规模从 280 到 3,724 LOC 不等。三位高级开发者采用LLM 辅助翻译产出参考实现,随后通过执行 222 个顶层测试用例来验证 Rust 输出。
Vivo-Bench [21] 与 C2R-Bench 中的每个项目均包含 4 个关键组成:C 源码、C 测例、Rust 翻译结果以及对应的 Rust 测试用例。详尽统计见表III。
D. 实现细节(Implementation Details)
我们以 DeepSeek-V3 [26] 作为基础模型实现 EVOC2RUST,利用其在多种编程语言(含 C 与 Rust)上的大规模预训练,以加强跨语言理解。
用于代码翻译时,我们配置模型为贪心解码(greedy decoding),并设置 $ \text{max_tokens} = 4096 $。
用于代码分析时,我们采用 Tree-sitter v0.22.3 [22] 解析 C 项目,并使用 rustc [29] 作为 Rust 编译器。
我们使用 BGE-M3 [30] 生成代码向量表征,通过余弦相似度检索最相近的 Top-10 个转换样式(patterns)。在效率与效果之间做权衡,我们将修复迭代上限设为:括号修复 5 轮,LLM 细化 3 轮。
为测量行级接受率(AccRate),我们为所有评测方法人工建立并验证参考实现。遵循严格的验证流程:由 3 位作者分别使用目标方法对每个项目的源码与测试套件完成完整翻译;生成的 Rust 代码先进行编译与测试,随后在 Claude Sonnet 4 [31] 的交互式辅助下手动迭代修正,直到全部测试通过。最后,另外 3 位工程师对这些参考实现进行代码评审,以再次确认其语义正确性。
所有实验均在 Linux 服务器上进行:Ubuntu 23.10,两块 NVIDIA GeForce RTX 4090 GPU,CUDA 12.4。
4. 结果与分析(RESULTS AND ANALYSIS)
A. 主要结果(RQ1)
EVOC2RUST 的主要实验结果见表IV。它在两个数据集上全面优于所有基线方法,在三项综合指标上均取得最高分。
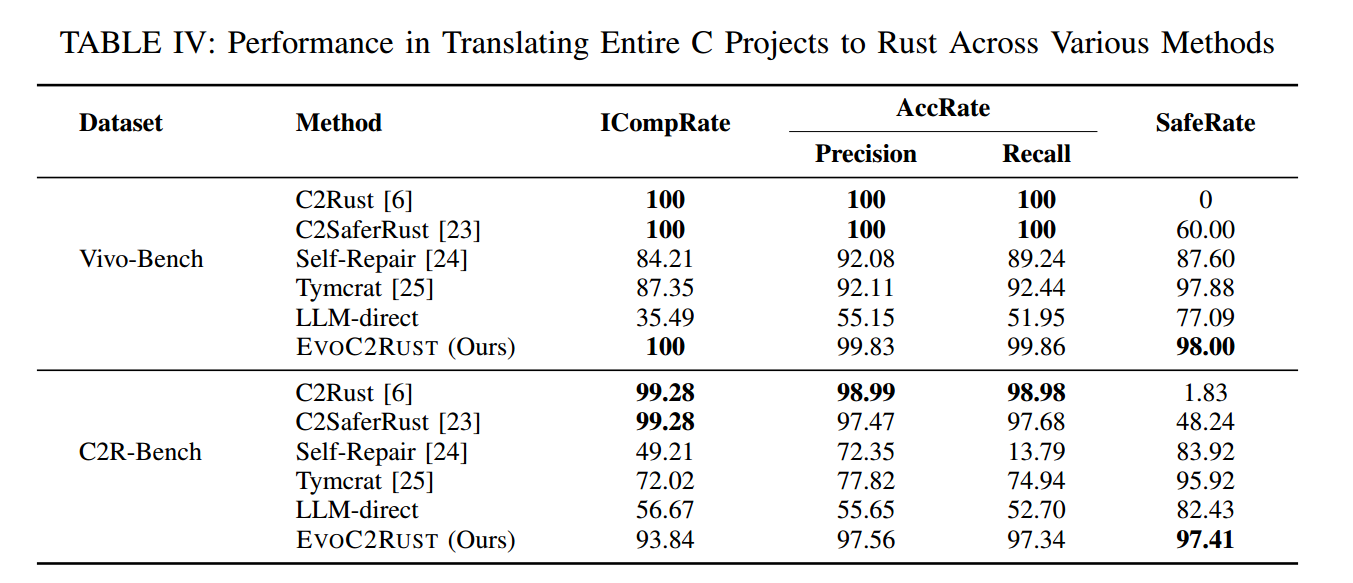
与基于规则与混合式基线相比,EVOC2RUST 在生成安全的 Rust 代码方面展现出显著优势。尽管 C2Rust 与 C2SaferRust 在编译通过率上接近完美(例如在 Vivo-Bench 上为 100%),它们容易生成不安全代码:在两个数据集上的代码安全率,C2Rust 仅为 0% 与 1.83%;C2SaferRust 即便结合了 LLM 的优化,也仅达到 60% 与 48.24%。这说明:单纯的语法级翻译,即使叠加 LLM 的后处理,也无法稳定满足 Rust 的安全要求。我们的方法通过由“安全保证”的特征映射增强的 LLM 翻译,主动抑制不安全代码的产生。
在基于 LLM的方法中,EVOC2RUST 在所有评测指标上也保持稳定领先。在 Vivo-Bench 上,它的编译成功率比所有基线高出 12.65%~64.51%,行级接受率高出 7.57%~46.30%,同时仍保持 98% 的高代码安全率。在更具挑战的 C2R-Bench 上,它实现 93.84% 的编译成功(比各基线高 21.82%~44.63%),且行级接受率超过 97%。这些优势源自我们骨架引导、特征映射增强的翻译路径。
更具体地,与 Self-Repair 相比,EVOC2RUST 在 C2R-Bench 上的编译成功率提升 44.63%,行级接受率提升 54.38%。Self-Repair 的文件级处理经常超过 DeepSeek-V3 的 4096 token 输出上限,导致代码截断与程序不完整这一关键限制。与 Tymcrat 相比,EVOC2RUST 在更具挑战的 C2R-Bench 上编译成功率也高出 21.82%。Tymcrat 通过多样化签名生成与上下文增强降低初始错误,但因为缺少专家提炼的结构化翻译指导,在复杂场景中效果受到限制。LLM-direct 表现最差:平均编译成功率仅 46.08%;行级接受指标也偏低(Precision 55.40%、Recall 52.33%),其原因在于 C↔Rust 语言差异与Transformer 上下文窗口的先天约束。
笔者注:这里的数据有点乱啊,和表格里的很多都对不上,比如55.40%从未在表格里出现
RQ1 的回答。 在将完整 C 项目翻译为 Rust 的任务上,EVOC2RUST 在两个数据集上相较所有基线方法始终占优,并在编译成功、行级接受与代码安全三项指标的综合得分中居首。
B. 模块级翻译(RQ2)
我们进一步针对 EVOC2RUST 的模块级代码翻译准确度进行专门评估——这是该方法的核心技术组件之一。评估在 Vivo-Bench 与 C2R-Bench 上进行,并采用两种基础模型:DeepSeek-V3 与 Qwen3-32B [32],以覆盖不同的模型规模与架构范式。
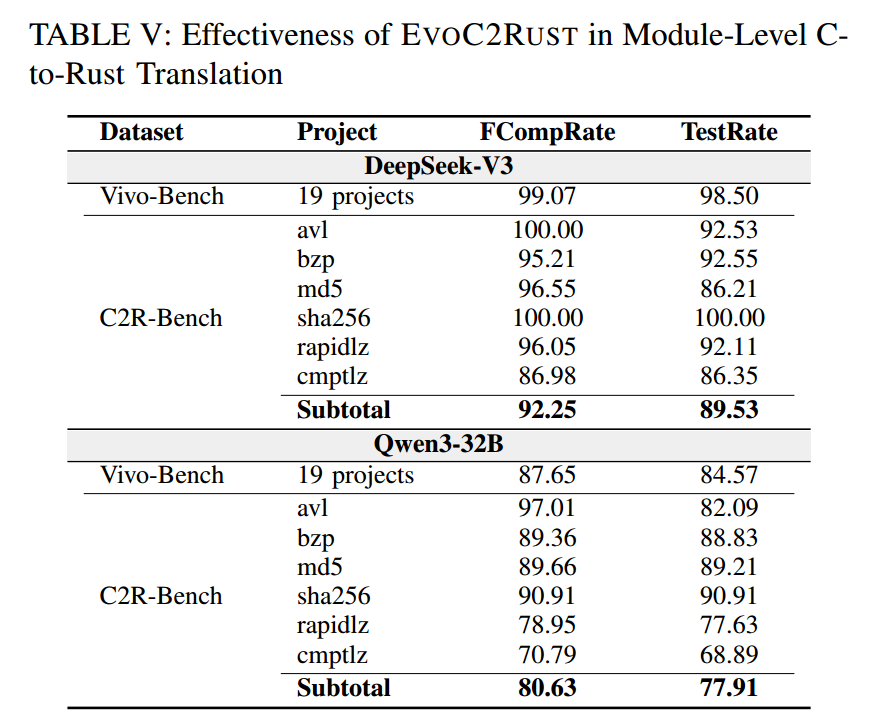
如表V所示,EVOC2RUST 在模块粒度上表现突出:
在 DeepSeek-V3 下,它在 Vivo-Bench 上达到 100% 编译通过与 99.07% 测试通过;在 C2R-Bench 上也保持稳健(92.25% 编译通过,89.53% 测试通过)。即便在参数量小 20× 的 Qwen3-32B 上,EVOC2RUST 仍取得可接受结果(80.63% 编译通过,77.91% 测试通过),显示出对模型规模的鲁棒性。
值得注意的是,测试通过率与编译成功率之间呈现高度一致:能正确编译的 Rust 模块通常也能通过测试。这一一致性来自我们方法的双重机制:特征映射抑制语义错误,编译器引导的修复维持逻辑正确的纠错过程。
我们的评估还揭示了影响翻译质量的两个关键因素:项目复杂度与函数长度。复杂项目(控制流与数据依赖精细、宏与依赖繁多)会持续挑战 LLM 的理解能力——这在我们对 C2R-Bench 中 6 个工业项目的分析中得到体现。例如,cmpt1z 项目(复杂宏与依赖)在不同模型下的测试通过率为 86.35% 与 70.79%;而更“简单”的 sha256 则稳定达到 100%。此外,函数长度与翻译成功显著负相关(见图 3):
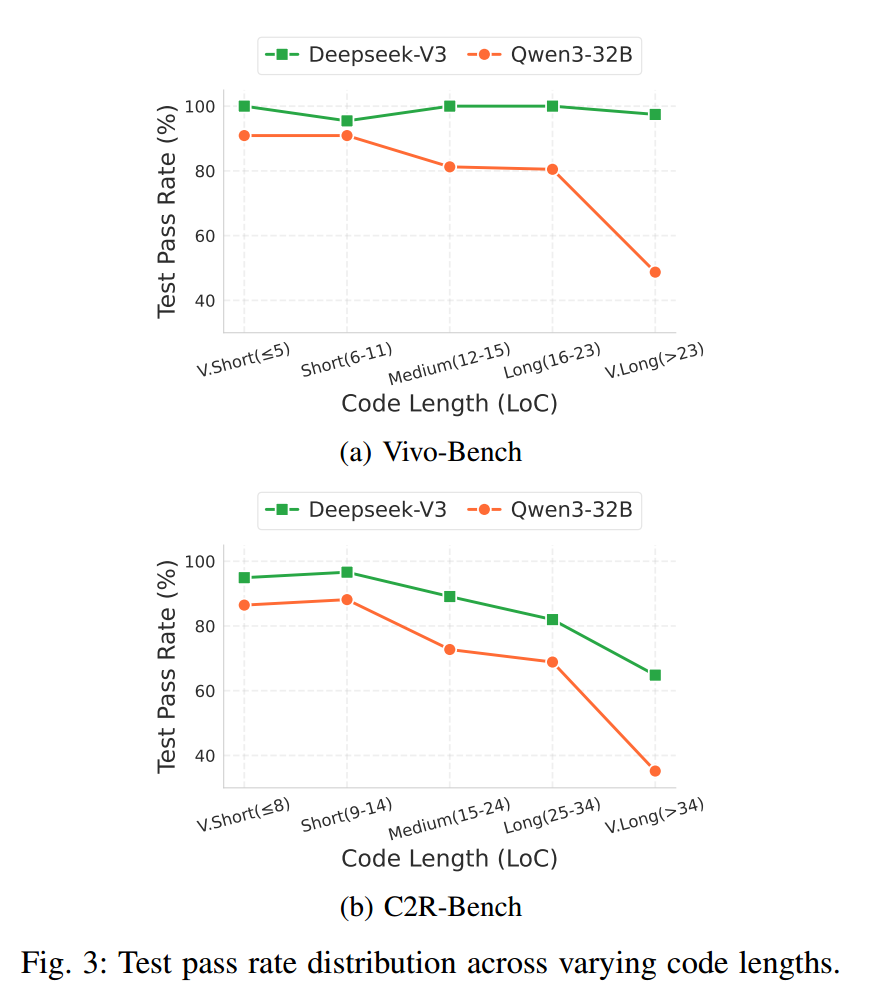
对 DeepSeek-V3,随着函数变长,测试通过率从 97.46% 降至 81.13%;
对 Qwen3-32B,下降更加明显——从 88.68% 至 41.96%。
尽管存在这种随长度下降的趋势,EVOC2RUST 在 DeepSeek-V3 下的平均通过率仍达 94.02%,表明即便面对长函数也具备良好鲁棒性。
RQ2 的回答。 我们的方法在模块级翻译上表现稳健:在不同模型规模下的编译成功率为 92.25%~100%、测试通过率为 77.91%~99.07%,证明其在应对代码复杂度与函数长度挑战时同样有效。
C. 消融实验(RQ3)
为评估 EVOC2RUST 各组件的贡献并验证我们的设计选择,我们进行消融实验:逐步移除方法中的关键组件——括号修复、规则修复、LLM 细化与特征映射。我们基于 DeepSeek-V3 作为基础模型,在 C2R-Bench 数据集上评估各变体。
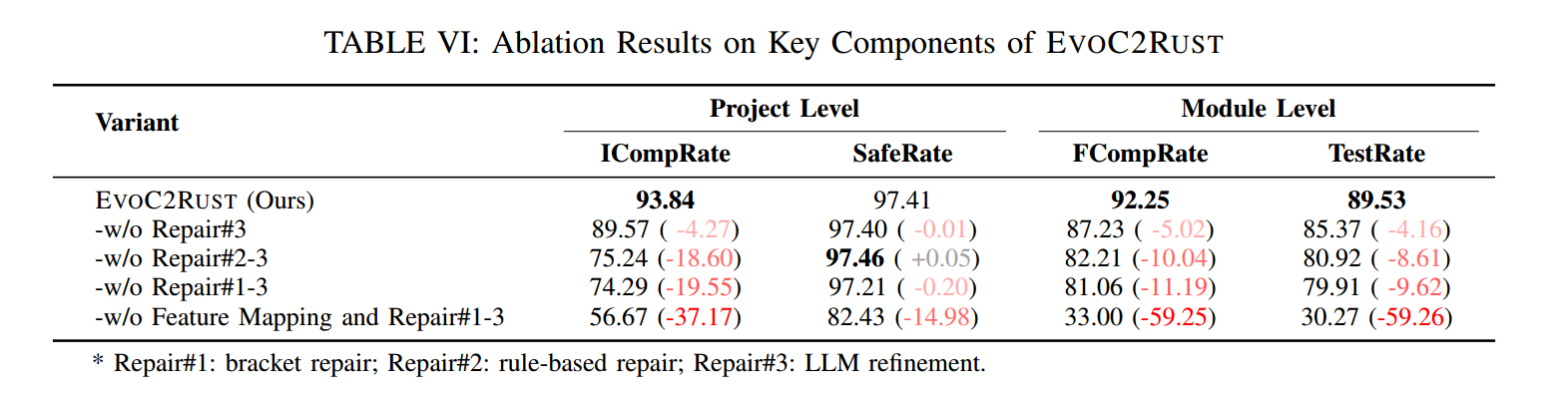
如表VI 所示,EVOC2RUST 的每个组件都对整体效果至关重要。其中,特征映射机制影响最大:一旦移除,该机制,ICompRate 与 FCompRate 将分别从 74.29% 降至 56.67% 与从 81.06% 降至 33%;对语义正确性的影响同样显著,TestRate 从 79.91% 降至 30.27%。这强调了特征映射在桥接 C 与 Rust 结构差异方面的重要性:通过预定义转换样式将 C 的惯用法映射到安全的 Rust 等价实现,尤其在缺少一一对应构造时更为关键。
级联修复链也显著促进了 C→Rust 的翻译质量。若同时移除三种修复(-w/o repair#1-3),性能将明显下降:ICompRate 降低 19.55%、FCompRate 降低 11.19%、TestRate 降低 9.62%。在这条链路中,规则修复(repair#2)贡献最大:平均提升编译通过率 9.68%、测试通过率 4.45%。LLM 细化(repair#3)在此基础上进一步带来 4.27% 的语法收益与 8.98% 的语义收益,且不会牺牲代码安全。
值得注意的是,在大多数消融变体中,代码安全基本稳定在 ≈97%,这归功于特征映射机制:它将低层操作封装进经验证的安全构造中,从而保证不安全代码比例稳定(安全分仅有 ≤1% 的轻微波动)。然而,无引导的直接生成(同时缺失映射与修复)会使安全性骤降到 82.43%,从反面证明了我们机制的必要性。
RQ3 的回答。 EVOC2RUST 的每个组件都对总体性能有显著贡献。其中,特征映射为弥合 C↔Rust 语义鸿沟提供了安全且可靠的底座;而级联修复链进一步清除残余错误,最大化语法与语义正确性。
D. 案例研究(Case Study)
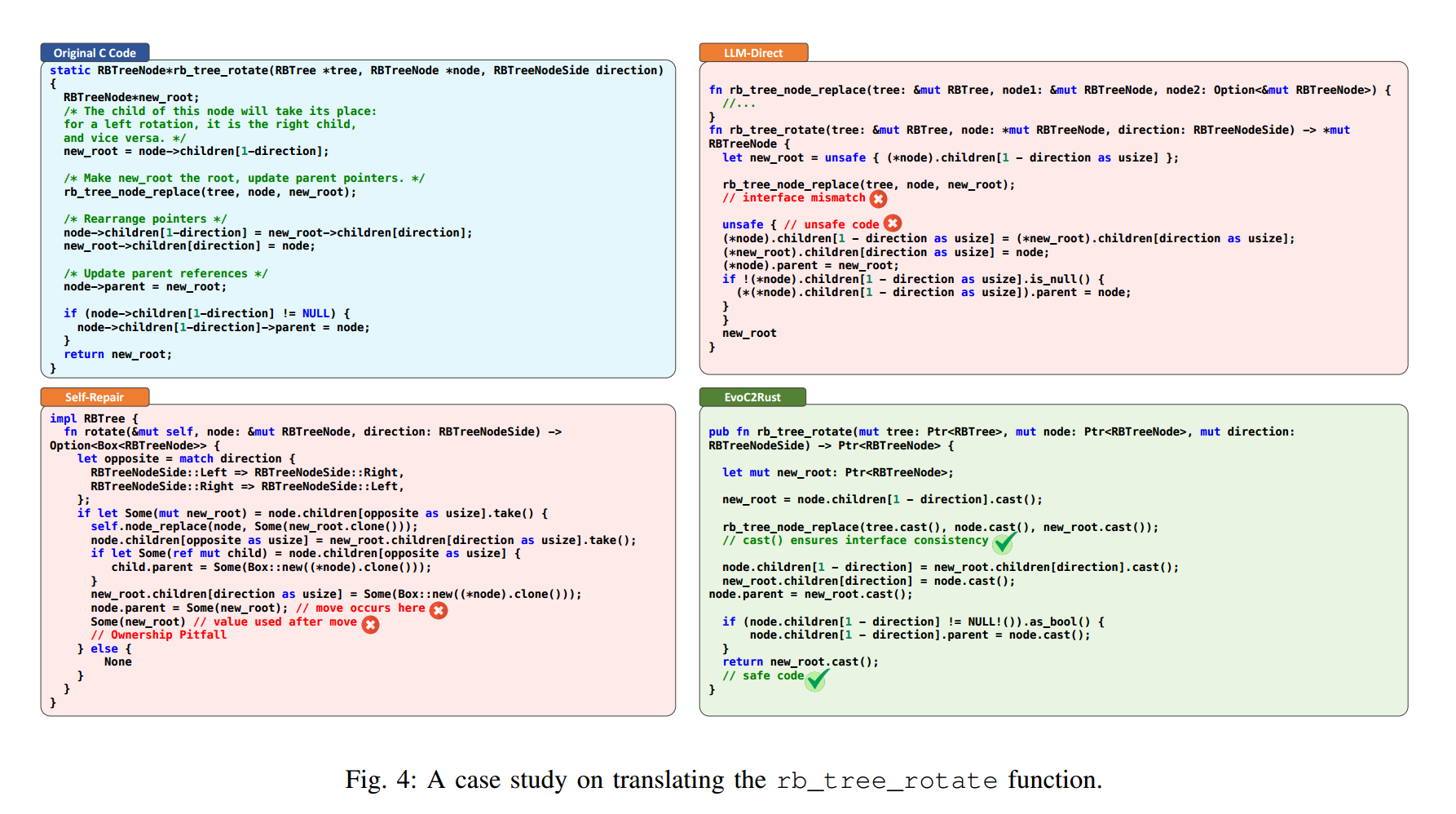
我们选取红黑树的核心函数 rb_tree_rotate 作为案例(见图4),展示 EVOC2RUST 的有效性。该函数涉及的复杂指针操作代表了低层 C 代码中最难以安全、正确翻译的一类场景,也揭示了其他方法常见的失效模式。
如图 4 所示,基线方法在此场景中表现不佳:
LLM-direct 因项目级接口不匹配而失败——在需要可变引用(&mut)的地方传入了裸指针(*mut)。这暴露出其缺乏项目级上下文感知;且依赖裸指针会不可避免地引入 unsafe 块,从根本上削弱内存安全目标。Self-Repair 虽尝试以 Box<T> 进行更符合 Rust 惯用法且更安全的翻译,但在函数层面引入了所有权错误(例如 use of moved value),说明在缺乏系统化框架的情况下,手工将 C 风格内存管理重构为安全的 Rust 惯用法非常困难。
相较之下,EVOC2RUST 生成了正确且稳健的译文。其成功源于我们的特征映射:使用统一的 Ptr<T> 智能指针在项目范围内保持C 式指针语义与类型一致性;再结合灵活的.cast() 类型转换方法,同时解决了接口不匹配与所有权两类导致其他方法失败的问题。通过将低层 C 操作系统化地映射到安全的抽象层,EVOC2RUST 在其他方法难以奏效的地方,依然能够产出正确且完全安全的翻译。
笔者注:体现了引入对等抽象层的重要性(
Ptr<T>对应c语言的指针,.cast()对应c语言的任意类型转换)
5. 讨论(DISCUSSION)
A. 为什么 EvoC2RUST 有效?
EvoC2RUST 将 LLM 的能力、多智能体协作、知识增强技术、静态程序分析与基于规则的转换综合进一个统一框架,用于自动化的项目级 C→Rust 翻译。其有效性主要来源于以下三点:
骨架引导的翻译(Skeleton-guided Translation)。
EvoC2RUST 利用程序分析将大型 C 项目分解为可复用的模块组件,为模块装配生成一个可编译的 Rust 骨架,并通过将已转换的 Rust 代码插入骨架结构来执行增量式的函数级翻译。这种骨架引导策略使得翻译、编译与修复都与原始项目结构保持一致,并且在 LLM 的上下文窗口限制内完成,同时允许并行的模块翻译而不被跨模块依赖牵制。特征映射(Feature Mapping)。
EvoC2RUST 通过带有安全保证的特征映射,引导 LLM 弥合 C→Rust 的语义鸿沟,覆盖 types、macros、functions、operators、syntax structures、globals、variadic arguments 等要素。按需动态检索的映射使 LLM 能对齐到精确的一一对应,从而有效抑制幻觉。级联的生成后修复(Cascading Post-Generation Repairs)。
在 LLM 完成初译之后,EvoC2RUST 采用以编译为驱动的级联修复机制:(1)在编译检查的保障下迭代细化 Rust 代码;(2)将 LLM 的语义理解 与 基于规则的语法修正 协同起来;(3)提供可扩展的体系结构,以便在未来集成新的修复技术。
B. 局限性与效度威胁(Limitations and Threats to Validity)
我们识别出以下对本方法效度的限制与潜在威胁:
内部效度(Internal Validity)。
主要威胁来自正确性验证目前依赖预定义的测试用例。若采用更健壮的验证技术,如 fuzzing [33] 与 self-debugging [34][35],可提升测试覆盖率并发现细微的语义错误。在行级接受率的度量上,我们使用由 Claude 生成、并经人工专家复核的结果作为真实标注。此类人工验证确保了超越自动化测试的正确性,但在更大规模数据集上可能难以扩展。未来工作应探索半自动化验证,在准确性与效率间取得平衡。
外部效度(External Validity)。
外部效度主要受两方面威胁:
- 可泛化性(Generalizability)。 虽然我们的翻译流水线被设计为可支持多语言对,但当前实现专注于 C→Rust,以便推动项目级迁移研究。受资源限制,当前评测仅涉及 DeepSeek-V3 与 Qwen3-32B 两个基础模型。这一选择并不影响对框架本身的评估有效性——本文的重点在于方法架构而非模型对比。我们明确指出,引入更多模型进行扩展评测是重要的后续方向。
- 数据集特性(Dataset characteristics)。 我们的评估使用了开源 Vivo-Bench 与工业级 C2R-Bench;然而,这两类数据集目前限定为单线程、用户态 C 项目,并依赖 ISO C 标准库。未来工作应进一步覆盖更复杂的场景,例如多线程、第三方库以及内核态代码。
6. 相关工作(RELATED WORK)
A. C→Rust 翻译
现有的自动 C→Rust 翻译方法大致分为三类:基于规则、基于 LLM 与混合式技术。
基于规则的翻译。
此类方法通过分析程序语法并手工设计转换规则来完成程序变换,常见如基于 AST 的转换。开源转译器 C2Rust [6] 即是代表:借助 Clang 的 AST 生成语义等价的 Rust 代码。然而,它往往产生非惯用的 Rust 代码,并且在几乎所有函数签名上都需要 unsafe。鉴于这些局限,后续研究提出了有针对性的改进:Emre 等 [20][36] 将 rustc 的编译反馈引入以提升指针安全;Zhang 等 [7] 对指针操作进行静态所有权分析;Ling 等 [28] 以模式匹配做源码到源码的 API 安全转换;Hong 等 [8][37]–[39] 则通过自定义分析处理一系列特定构造,如锁 API、输出参数、联合体与 I/O API。此外,Han 等 [40] 用 C 风格语法糖在 Rust 中模拟控制流差异;Fromherz 等 [41] 给出将 C 的一个子集形式化翻译到安全的 Rust。然则,这些方法通常需要专家投入大量时间手工编写规则;而最终生成的目标程序常常在可读性与安全性上仍显不足。
基于 LLM 的翻译。
近年,大语言模型因无需手工规则即可生成更合乎惯用法的代码,而在代码翻译上展现潜力。Eniser 等 [10] 提出 FLOURINE,利用 fuzz 测试在无需现有测试用例的情况下验证译后 Rust 与原始 C 代码的语义等价;Yang 等 [11] 使用 MSWasm 的测试框架,将其适配到多语言(含 C)→Rust 的翻译;Nitin 等 [12] 将静态规格、I/O 测试与自然语言描述结合以增强 LLM 翻译;Farrukh 等 [42] 构建了一个多智能体框架,进行迭代式纠错。不过,相较基于规则的方法,当前基于 LLM 的方法在翻译准确率上仍偏低,主要原因在于缺乏大规模 C↔Rust 平行语料,难以弥合两种语言的根本语义差异 [13]。
混合式技术。
近期研究显示,将基于规则与基于 LLM的方法结合,能在 C→Rust 翻译中发挥互补优势。例如 C2SaferRust [23] 采用 LLM 后处理对 C2Rust 的输出进行迭代细化,在自动化验证测试的帮助下同时提升安全性保证与代码惯用性,并保持功能等价。在此基础上,EvoC2RUST 提出一种新的混合框架:在两阶段中协同整合基于规则与基于 LLM的方法。翻译阶段用语言特征映射(即转换规则)引导 LLM 解决 C→Rust 的语义差异;修复阶段采用以编译为驱动的级联修复机制,将 LLM 的语义理解与基于规则的语法修正结合,优化生成 Rust 代码的整体质量。我们的方法在翻译准确性与安全保证之间取得了务实的平衡,以支持自动化的 C→Rust 迁移。
B. 以 LLM 实现的项目级代码翻译
尽管多数现有方法聚焦于小规模的 C 代码翻译,近来的工作开始探索项目级 LLM 翻译。其做法通常是:先通过程序分析将 C 项目分解为基于依赖的翻译单元,再进行翻译并重新装配为可运行的 Rust 项目。
Shiraishi 等 [18] 率先开展了项目级翻译,利用项目元数据维持跨单元的一致性;但其主要关注编译成功,并未确保功能等价。Syzygy [19] 与 RustMap [43] 同时翻译 C 函数及其关联测试,并利用编译/测试反馈修复生成的 Rust 代码;但它们需要关于目标函数的完整依赖上下文,这并非总能自动抽取,有时还需要人工补充(例如 RustMap 的 “ASK Me” 机制)。此外,其测试与分析框架在工业场景下面对复杂特性与数据结构(如复杂对象结构与循环引用)时,可扩展性受限。
Khatry 等 [24] 与 Ou 等 [13] 构建了仓库级的 C/C++→Rust 评测基准,并配套了诸如 Self-Repair 等技术。然而,它们的方法依赖带标注的 Rust 函数接口,而这在工业场景中很少可用。为缓解该限制,Hong 等 [25] 提出 Tymcrat,一种基于类型推断的自动函数签名翻译方法。
不同于按依赖顺序串行翻译模块、且需要完整项目上下文的做法,EvoC2RUST 引入了骨架引导策略:首先构建一个可编译的 Rust 骨架,然后执行增量的函数级翻译。该策略不仅支持并行翻译,还通过将 LLM 与跨模块依赖解耦来降低翻译复杂度,从而提升翻译正确性。
7. 结论(CONCLUSION)
我们提出 EvoC2RUST,一个由 LLM 驱动的整项目 C→Rust 自动翻译新框架。EvoC2RUST 采用特征映射增强的 LLM 实施骨架引导的代码翻译,并在此基础上结合 LLM 能力与静态分析进行混合式错误修复。在开源与工业两类基准上,EvoC2RUST 在语法准确性、语义等价性与内存安全性方面均表现出持续领先的性能。
尽管近年已有进展,C→Rust 翻译仍是一个开放挑战,尤其在涉及多线程、第三方库以及内核态代码等跨领域复杂场景时更为困难。为推动该领域发展,我们提出两条关键的研究方向:
(1) 开发新的细化技术,充分利用持续演进的 LLM 能力(例如 fuzzing [33] 与自调试 [34][35] 等);
(2) 探索将语言模型作为自主智能体 [44] 的路径,使其具备多步推理与反思能力,以更好地处理复杂的翻译任务。
这些方向为后续研究提供了有前景的路线。
Reference
Translating C to safer Rust
PACMPL – OOPSLA 2021(OOPSLA 专刊)、CCF A
Aliasing Limits on Translating C to Safe Rust
PACMPL – OOPSLA 2023(OOPSLA 专刊)、CCF A
Forcrat: Automatic I/O API Translation from C to Rust via Origin and Capability Analysis
To Tag, or Not to Tag: Translating C's Unions to Rust's Tagged Unions
ASE 2024(IEEE/ACM International Conference on Automated Software Engineering)、CCF A