Don’t Write, but Return: Replacing Output Parameters with Algebraic Data Types in C-to-Rust Translation
Don’t Write, but Return: Replacing Output Parameters with Algebraic Data Types in C-to-Rust Translation
论文来自 2024 Proceedings of the ACM on Programming Languages (PLDI 2024) 的《Don’t Write, but Return: Replacing Output Parameters with Algebraic Data Types in C-to-Rust Translation》。
摘要
将遗留系统程序从 C 迁移到 Rust 被认为是提升其可靠性的有前景途径。为减轻人工翻译的负担,自动化的 C→Rust 翻译是理想选择。然而,现有翻译器无法生成充分利用 Rust 语言特性的 Rust 代码,尤其是代数数据类型。在本文中,我们聚焦于元组(tuples)与 Option/Result 类型——它们是代数数据类型的重要子集,常作为函数返回类型,用以表达“返回多个值”的情形以及“可能失败”的情形。
由于 C 语言缺少这些类型,C 程序通常通过输出参数来实现此类函数,即使用指针类型的形参来承载输出值。由于输出参数会降低代码可读性并更易引入错误,Rust 中并不鼓励使用这种做法。针对这一问题,本文提出一种在 C→Rust 翻译过程中消除输出参数的技术。该技术包含三个步骤:(1)使用现有翻译器将 C 代码进行语法层面的 Rust 翻译;(2)分析得到的 Rust 代码,提取与输出参数相关的信息;(3)依据分析结果对 Rust 代码进行改写。
第二步面临若干挑战,包括如何识别与分类输出参数。为克服这些挑战,我们提出一种基于抽象解释的静态分析方法,并引入抽象读/写集合(abstract read/write sets)的概念,用以近似分析被读取/被写入的指针集合;同时结合两种灵敏度:写集合灵敏度(write set sensitivity)与空值性灵敏度(nullity sensitivity)。
我们的评估表明,该技术:(1)具有良好的可扩展性——在 213 秒内完成对 190k 行代码(LOC)的分析与改写;(2)切实有用——在 55 个真实世界的 C 程序中共检测出 1,670 个输出参数;(3)基本正确——在改写后有 26 个程序中的 25 个通过了其测试套件。
1. 引言
Rust 是一种现代编程语言,旨在在系统编程领域取代 C/C++【Matsakis and Klock 2014】。它在不牺牲性能的前提下提供内存安全,并具备系统程序所需的细粒度内存控制能力【Jung et al. 2017】。自诞生以来,Rust 已在系统程序员中得到广泛采用。许多复杂的系统程序(包括操作系统【Boos et al. 2020; Lankes et al. 2019, 2020; Levy et al. 2017; Narayanan et al. 2020】以及垃圾回收器【Lin et al. 2016】)已经用 Rust 从零实现。甚至一些重要的遗留软件(例如 Firefox【Anderson et al. 2016】与 Linux【De Simone 2022】)也已将 Rust 纳入其代码库,用以逐步以 Rust 替换 C/C++ 代码。
系统程序员对 Rust 的浓厚兴趣,催生了对自动化 C→Rust 翻译的需求。大量现存系统程序是在 Rust 问世之前用 C 语言开发的,目前并未享受到 Rust 的优势。将它们迁移到 Rust 被认为是提升可靠性的一条颇具前景的道路【Hutt 2021】。然而,若手工进行翻译,将需要程序员投入大量精力,因此自动化翻译更为理想。
要构建一个满足开发者需求的自动翻译器并不容易,因为这意味着需要同时实现多项目标:它不仅要生成语法上正确的 Rust 代码,还要与原始 C 代码在语义上等价。此外,生成的代码还应当符合 Rust 的编程习惯,能够有效发挥语言特性。Rust 吸收了许多既有语言的有用特性。例如,Rust 对代数数据类型与参数化多态的支持受函数式语言影响,其 trait 与 Haskell 的类型类相似【Klabnik and Nichols 2018】。这些特性能简洁清晰地表达意图,因此能否恰当地把它们融入生成代码,会显著影响翻译质量。
遗憾的是,现有 C→Rust 翻译器距离上述高标准仍有差距。最广泛使用的翻译器是 C2Rust【Winterger 2022】;它可以将大量真实世界的 C 代码翻译成在语法和语义上都正确的 Rust 代码。但其产出的代码仅包含与 C 等价的特性,这大幅限制了 C2Rust 的实际可用性。研究者已提出将 C2Rust 生成代码中的“C 等价特性”替换为 Rust 提供的更佳替代方案的技术,例如:用安全引用替换不安全的原始指针【Emre et al. 2023, 2021; Zhang et al. 2023】,以及用 Rust 的锁 API 替换 C 的锁 API【Hong and Ryu 2023】;但仍有许多特性尚未触及。
在本文中,我们聚焦 Rust 中的元组与 Option/Result 类型【Rust 2023d,e,f】,它们是代数数据类型的重要子集,尤其适合作为函数的返回类型。元组天然地用于表达“返回多个但数量固定的值”的函数。Option 与 Result 类型用于实现偏函数(partial functions),即可能失败的函数:Option 要么是 Some(v),要么是 None;Result(类似其他语言中的 Either)要么是 Ok(v),要么是 Err(e),其中 表示与失败相关的信息。这些类型在编程实践中用途广泛,哪怕是非常基础的任务也是如此。下面展示两个除法函数:一个同时返回商与余数,另一个只返回商,但当除数为零时以失败告终。
fn div(n: i32, d: i32) -> (i32, i32) { (n / d, n % d) }
fn div(n: i32, d: i32) -> Option<i32> {
if d == 0 { None } else { Some(n / d) }
}由于 C 不提供与元组以及 Option/Result 等价的类型,C 程序员通常使用输出参数来实现此类函数。输出参数是指针类型的形参,函数用它们来产生值而不是获取输入【Martin 2008; Roth 2021】。例如,不再返回一个由两个值组成的元组,函数只返回其中一个值,并把另一个值写入其输出参数;又如,不再返回 Option/Result,而是在成功时才把结果写入输出参数,并用返回值来传达成功或失败的信息。下面是用 C 改写后的前述两个除法函数:
int div(int n, int d, int *r) { *r = n % d; return n / d; }
int div(int n, int d, int *q) {
if (d == 0) { return 1; } // 1 表示失败
*q = n / d; return 0; // 0 表示成功
}在第二个函数中,返回值为 表示失败, 表示成功。
为弥合 C 与 Rust 之间的差异,我们希望在 C→Rust 翻译过程中,用元组与 Option/Result 来替换输出参数。通常并不鼓励使用输出参数,因为它们常使代码可读性变差、并更易出错【Martin 2008; Roth 2021】。形参本质上用于输入;将其用于输出会混淆代码理解。此外,当用输出参数来实现偏函数时,它们无法通过类型表达“可能失败”这一事实——程序员可能会在函数已失败后,仍然尝试读取传入该函数的指针。因此,在 Rust 中,推荐用元组与 Option/Result 取代输出参数:直接返回结果能提升代码清晰度;而 Option/Result 在类型层面表达了失败的可能性,从而迫使调用方显式处理失败。

本文提出了一种在 C→Rust 翻译过程中消除输出参数的技术。图1展示了该方法的整体流程。与以往 C→Rust 翻译研究相似【Emre et al. 2023, 2021; Hong and Ryu 2023; Zhang et al. 2023】,我们首先使用 C2Rust 将 C 代码初步翻译成 Rust,随后在此基础上对生成的 Rust 代码进行增强,重点在于移除输出参数。为实现这一变换,我们通过静态分析提取与输出参数相关的信息,但这带来了若干挑战。
第一个挑战是识别每个函数的输出参数。为此,我们提出一种基于抽象解释框架【Cousot and Cousot 1977】的静态分析。我们引入抽象读/写集合(abstract read/write sets),用以近似运行时被读取/写入的指针类型形参的集合。抽象状态不仅包含抽象内存位置的抽象值,也包含抽象的读/写集合。某个函数的输出参数由其返回点处的抽象写集合决定。
第二个挑战是判定每个输出参数是否总被写入。若某参数确实总被写入,那么形如 *mut T 的参数(即指向 的原始可变指针)即可通过直接返回 来移除;否则该函数是偏函数,此时应改为返回 Option<T> 或 Result<T, E> 来移除该参数。此外,在后一种情形中,我们还必须识别哪个返回值表示成功/失败。这一信息对后续在调用点用模式匹配 Option/Result 的返回值至关重要。为达成这一点,我们提出写集合灵敏度(write set sensitivity),用于区分不同的“被写入指针集合”。通过检查这些被区分开的写集合,我们可以判断每个参数是否总被写入;再结合与不同写集合相关联的返回值,我们就能确定“在写入某个指针”和“未写入该指针”两种情况下分别会返回什么。
第三个挑战是区分当空指针被传入与未被传入时,函数的不同行为。在 C 中,调用者在不需要结果时,往往会给输出参数传入空指针,被调用者只在该指针非空时才写结果。由于未向空指针写入不能被视为“函数是偏的”的证据,我们在判断“某指针是否总被写入”时,必须排除“该指针为 NULL”的情形。为此,我们提出空值性灵敏度(nullity sensitivity),用于区分指针的“空/非空”状态。
综上,本文的贡献如下:
- 定义并分类输出参数(§2)。
- 提出一种高效的自底向上的静态分析方法,基于抽象解释,并辅以抽象读/写集合、写集合灵敏度与空值性灵敏度(§3)。
- 给出利用分析结果移除输出参数的代码变换(§4)。
- 将上述方法实现为名为 Nopcrat 的工具(no-output-parameter C-to-Rust automatic translator),并在 55 个真实世界的 C 程序上进行评估。结果表明:该方法(1)具有良好可扩展性:在 213 秒内分析并改写 190k 行代码;(2)实用:在 55 个程序中共检测到 1,670 个输出参数;(3)大体正确:在改写后,26 个程序中的 25 个通过了其测试套件(§5)。
随后我们讨论相关工作(§6),并在(§7)给出结论。
2. 输出参数的定义
本节我们给出输出参数的定义,并配以示例代码以便说明。判定某个形参是否为输出参数,取决于引入该参数的函数在一次调用到返回之间的行为;因此,本节的定义仅考虑从函数被调用到其返回这段时间内发生的事件(例如,“一次执行”指所讨论的这个函数体的一次执行,而非整个程序的执行)。鉴于我们的目标是在 C2Rust 生成的 Rust 代码上移除输出参数,以下示例均以 Rust 给出,而非 C。
我们首先定义路径(path),它表示由某个指针类型形参所指向的内存位置。一个形参可以指向某个结构体的值(struct value),而结构体的每个字段对应一个独立的内存位置。因此,路径定义如下:
定义 2.1(路径 Path)
一条路径 是“指针类型形参 ”后跟零个或多个字段投影 :
并非每条路径都表示有效的内存位置,因为它可能包含并不存在的字段。为过滤掉此类无效路径,我们定义良类型路径:
定义 2.2(良类型路径 Well-typed path)
若形参 的类型是 ,则 的路径类型(path-type)是 。若路径 的路径类型为 ,且结构体 拥有一个类型为 的字段 ,则 的路径类型为 。若一条路径具有某个路径类型,则称其为良类型(well-typed)。
为便于说明,假设下述结构体定义(本节贯穿使用):
struct S { a: i32, b: i32 }若 的类型为 ,则 与 都是良类型路径,但 与 不是。需注意:良类型路径可能指向相互重叠的内存区域。例如, 与 重叠,因为 指的是整个结构体,而 指的是它的第一个字段。为只考虑不重叠的路径,我们定义极大路径与 -路径集:
定义 2.3(极大路径与 -路径集)
若 是良类型路径,且对任意字段 , 都不是良类型,则称路径 是极大(maximal)的。-路径集是所有以 为起点的极大路径的集合。
例如:若 的类型是 ,则 -路径集为 ;若 的类型是 ,则 -路径集为 。最后,我们对极大路径上的读取与写入作如下定义:
定义 2.4(读与写 Read and write)
对极大路径 的读取,是获取由 所指向的内存位置上的值;对极大路径 的写入,是修改由 所指向的内存位置上的值。
一次读取意味着对指针进行解引用;一次写入意味着对该指针进行间接赋值。形式化地:
- 表达式 对 执行一次读;
- 赋值 对 执行一次写。
此外,经由别名指针或函数调用也可能发生读/写。例如,下面两段代码中,函数 f 都会写到 x:
fn f(x: *mut i32) { let y = x; *y = 1; }
fn f(x: *mut i32) { g(x); }
fn g(y: *mut i32) { *y = 1; }在处理结构体时,一个表达式可能会同时读/写多个极大路径。例如,下述代码中,f 同时写入 x.a 与 x.b:
fn f(x: *mut S) { *x = S { a: 1, b: 2 }; }借助“路径”的概念,我们进一步给出对不同参数种类的定义。下面的例子表明:一次读取并不必然阻止某个形参成为输出参数;一次写入也不必然使其成为输出参数:
fn f(x: *mut i32) { *x = 1; let v = *x; g(v); }
fn f(x: *mut i32) { let v = *x; g(v); *x = 1; }在第一段代码中,f 在写过 x 之后又读了它。由于函数从未使用“最初由 x 所引用的值”,我们仍可把 x 视为输出参数。相对地,在第二段代码中,f 先读了 x,随后才写它——这说明函数依赖于 x 原先指向的值,因此不能把 x 视作输出参数。基于这一观察,我们定义有效读/写:
定义 2.5(有效读与有效写 Effective read/write)
对路径 的一次有效读取,是指在该读取之前没有对 的任何写入;
对路径 的一次有效写入,是指在该写入之前没有对 的任何读取。
在上例中,第一段代码对 x 执行了有效写;第二段代码对 x 执行了有效读。按定义,在一次执行中,对同一条路径只能有效读或有效写其一,不能二者兼得。然而,在同一个函数内,不同的执行可能表现不同:某次执行对某路径是有效读,而另一次执行对该路径是有效写。比如,下例中,当 c 为真时,f 对 x 有效写;否则对 x 有效读:
fn f(x: *mut i32, c: bool) { if c { *x = 1; } let v = *x; g(v); }若一个函数在某次执行中对某条路径发生有效读,则函数确实需要该指针所指向的值,说明该参数承担了输入用途。因此我们定义输入参数:
定义 2.6(输入参数 Input parameter)
若存在某次执行,在该执行中 -路径集中的至少一条路径被有效读取,则形参 是一个输入参数。
另外,处理结构体时,“没有有效读”并不必然意味着该参数是输出参数。请看下面的两个例子:
fn f(x: *mut S) { (*x).a = 1; (*x).b = 2; }
fn f(x: *mut S) { (*x).a = 1; }在第一个例子中,f 有效地写入了 x.a 与 x.b(等价于把 S { a: 1, b: 2 } 赋给 *x),因此我们可以把 x 视作输出参数。相反,在第二个例子里,f 仅对 x.a 写入而未对 x.b 写入——它的目的更像是“更新所指结构体的部分状态”,而非“产生一个新的结构体值”。因此,不能将 x 归类为输出参数。为区分“结构体的所有字段是否都被写入”,我们引入全部/部分/无 写入:
定义 2.7(全部/部分/无 写入)
在某次执行中,若 -路径集中的每一条路径都被有效写入,则称 被全部写入(fully written);
若在某次执行中,-路径集中的部分路径被有效写入而部分未被写入,则称 被部分写入(partially written);
若在某次执行中,-路径集中的无一路径被有效写入,则称 在该执行中未被写入(not written)。
据此我们定义变异参数:
定义 2.8(变异参数 Mutation parameter)
若存在某次执行,使得 在该执行中被部分写入,则称形参 是一个变异参数。
注意:如果 的类型是 且 为诸如 i32 之类的原始类型,那么 -路径集是单元素集合,不可能发生“部分写入”,因此 不可能成为变异参数。
最后,我们给出输出参数的定义:
定义 2.9(输出参数 Output parameter)
若形参 既不是输入参数、也不是变异参数,且存在某次执行使得 被全部写入,则称 为输出参数。
我们将输出参数分为两类:must 与 may,因为它们对应不同的变换策略。must-输出参数在每次函数执行中都被全部写入;若其类型为 ,应将其替换为返回类型 。例如:
fn f(x: *mut i32) { *x = 1; }该函数总是向 x 写入,于是可变换为:
fn f() -> i32 { 1 }相反,may-输出参数仅在偏函数的情形下出现:它可能不被写入。移除此类参数需要令函数返回 Option<T>/Result<T,E>。例如:
fn f(x: *mut i32, c: bool) { if c { *x = 1; } }只有当 c 为真时函数才写入 x,因此可变换为:
fn f(c: bool) -> Option<i32> { if c { return Some(1); } None }还有一种更微妙的情形:函数检查传入指针是否为 null:
fn f(x: *mut i32) { if !x.is_null() { *x = 1; } }函数仅在 x 非空时写入;调用者可通过传入空指针来“忽略结果”。若将其改为返回 Option,我们需要确定正确的条件来替代 !x.is_null()(而此时已没有形参 x 可供检查):
fn f() -> Option<i32> { if ??? { return Some(1); } return None; }在这里,更合适的变换是直接返回 i32:
fn f() -> i32 { 1 }该变换更契合原函数的意图:原函数之所以没有写入 x,是因为调用者不需要结果,而非函数失败。因此我们并不把 f 归类为偏函数,且应把 x 视为 must-输出参数。据此,我们正式定义 must-/may- 输出参数:
定义 2.10(must-/may- 输出参数)
若在每一次 x 非空的执行中, 都被全部写入,则输出参数 是 must-输出参数;
若存在某次执行,x 非空但未被全部写入,则输出参数 是 may-输出参数。
很遗憾,我们无法移除所有输出参数。下面给出四类会导致输出参数无法移除的原因。需说明的是,我们并不声称这四类原因是穷尽的。它们来自我们对真实世界 C 代码的分析:我们先识别输出参数,再考察在不改变程序行为的前提下是否可以移除这些参数。我们的观察覆盖了用于第§5节评估的 55 个 C 程序;我们认为这四类原因涵盖了大多数“无法移除输出参数”的场景,尽管仍可能存在其他情形(例如见 §5.5)。
数组指针(Array Pointers).
当输出参数指向数组时,我们无法将其移除。例如,下面的代码中 x 指向一个整型数组:
fn f(x: *mut i32, len: usize) { for i in 0..len { *x.offset(i) = i; } }第二个形参 len 表示数组长度,函数把从 到 的整数依次写入数组。若要移除 x,变换后的函数就必须“返回一个长度为 len 的数组”。而 Rust 不允许这样做,因为返回值的大小必须在编译期已知。一种选择是返回 Vec(在 Rust 中指向堆分配数组的类型),但这超出了本文的范围。在 C→Rust 翻译中,用 Vec 替换动态大小数组本身就是一个重要目标,即便这些代码并没有输出参数。要做到这一点,需要把各种“数组操作”改写为相应的 Vec 操作,颇具挑战。因此,本工作将数组指针留待未来研究,在本文中将其视为不可移除。
void 指针(Void Pointers).
当输出参数的类型为 *mut c_void(等价于 C 的 void *)时,我们也无法移除。C 程序员常用 void * 来按上下文产生不同类型的值。例如,下面的函数按条件返回 32 位或 64 位整数:
fn f(x: *mut c_void, c: bool) {
if c { *(x as *mut i32) = i32::MAX; } else { *(x as *mut i64) = i64::MAX; }
}若要变换该函数,就需要令其返回 i32 或 i64,而 Rust 不允许这种“返回类型在运行期分支”的写法。
仅在空指针时的特定行为(Null-Specific Behavior).
当函数仅在输出参数为 null 时表现出某种特定行为时,我们无法移除该参数。举例来说,下面的函数仅当 x 为 null 时打印 "null!":
fn f(x: *mut i32) { if !x.is_null() { *x = 1; } else { println!("null!"); } }如果移除了 x,函数将无法判断何时打印 "null!"。
被保存的指针(Stored Pointers).
当输出参数被存入某个在函数返回后仍可访问的内存位置时,我们也无法移除。此类位置包括:作为实参传入的指针、作为返回值返回的指针、以及全局变量。考虑下面这个把 x 存入另一个形参 y 的例子:
fn f(x: *mut i32, y: *mut *mut i32) { *x = 1; *y = x; }若移除了 x,函数将无法正确更新 y。
为排除上述情形,我们给出“不可移除/可移除参数”的形式化定义:
定义 2.11(不可移除 / 可移除 参数)
若满足下列任一条件,则形参 为不可移除(unremovable):
- 指向一个数组;
- 的类型是
*mut c_void; - 仅当 为
null时,某个程序点才可达(即存在仅在 为null时发生的特定行为); - 被存入某个在函数返回后仍可访问的内存位置。
若 不满足以上任一条件,则称 为可移除(removable)。
3. 静态分析:识别输出参数
本节基于抽象解释框架【Cousot and Cousot 1977】提出一种用于识别输出参数的静态分析。分析目标是在每个函数中找出可移除的输出参数,并将其归类为 must 或 may。对于每个 may-输出参数,分析会计算两类信息:(1)当该参数被写入 / 未被写入时可能的返回值;(2)程序中该参数被完全写入的程序点。后续的代码变换阶段会使用这些信息。
我们的设计优先考虑可扩展性,基于两项关键决策:其一,采用自底向上(bottom-up)的方法,除递归函数外,每个函数只分析一次;其二,有意牺牲完备性(soundness),以避免维持完备所需的高昂开销。可能的“不完备来源”将在本节中讨论。
同时,我们也追求高精度:尽量最小化假阳性——即把“并非输出参数”的参数误判为输出参数。由于不完备,假阳性与假阴性都可能出现:当具体执行中存在一次读取而分析未覆盖时,会产生假阳性;当一次写入未被分析覆盖时,会产生假阴性。相比之下,假阳性更令人担忧,因为它可能让随后的变换改变目标程序的语义;而假阴性仅意味着我们移除的输出参数更少。为提升精度,分析通常对可能的具体行为做过近似(over-approximation),但在判定“哪些指针被写入”时例外。由于把“未被写入的指针”也纳入考虑会带来假阳性,我们对“写集合”做欠近似(under-approximation)。
下面给出本分析的细节。我们先介绍带有抽象读/写/排除集合的自底向上静态分析(§3.1)。其中,读/写集合用于识别 must-输出;排除集合用于识别不可移除的参数(尤其与数组指针、被保存指针相关)。随后,我们引入写集合灵敏度(§3.2),以识别 may-输出参数并计算其可能返回值。最后,我们加入空值性灵敏度(§3.3),以避免在存在“空指针检查”时把 must-输出误判为 may-输出,并识别因“仅在空指针时具有特定行为”而不可移除的参数。需要说明的是,针对 void * 的不可移除性,我们可以仅凭语法就识别出来,无需依赖本分析。
3.1 抽象读/写/排除集合(Abstract Read/Write/Exclude Sets)
我们首先为整个程序构造调用图(call graph)。这样可以先分析图的叶子结点,再利用其分析结果去分析调用者。由于构造调用图并非本文重点,我们以语法层面构建调用图,忽略函数指针。已有的控制流分析技术【Midtgaard 2012; Shivers 1988】可用于构造完备的调用图并进一步提升分析精度。

为聚焦核心概念,我们在一个简化语言上说明分析过程:值仅限于整数与指针。结构体的处理稍后在本节后半部分简述。图2给出了分析所用的抽象域。记:
- :标号(程序点)的集合;
- :变量名集合,含形参;
- :抽象指针集合,每个元素要么是变量地址、要么是作为实参传入的指针。记 表示分配给形参 的符号指针;
- :抽象地址集合,每个元素是抽象指针的集合;
- :抽象整数集合,每个元素是少于 个整数的集合,或其顶元素 。令 有限可保证格只有有限链。在实现中取 ;我们还使用widening 加速收敛,确保即使 也能终止;
- :抽象值集合,每个元素是 的有序对。我们用成对而非不相交并集,以便精确处理 C 中“指针↔整数”的强制转换;
- :抽象内存集合,遵循常规定义;
- :分别表示抽象读/写/排除集合的集合;每个读/写/排除集合本身是变量集合。
- 对读/排除集合我们做过近似:其底元素为空集,join(并)为并集;
- 对写集合我们做欠近似:其顶元素为空集,join 为交集。
- 最后, 为抽象状态集合;每个状态把一个标号映射到 的直积。
笔者注:抽象值集合就是把“值”概括成“可能的地址 + 可能的整数”的组合,以便精确处理 C 里指针与整数混用/强转的情况
为简化记号,记 分别为在标号 处计算得到的抽象内存/读/写/排除集合。抽象状态中的这些集合可作如下解释:
- 若 ,表示到达程序点 之前, 可能被有效读取;
- 若 ,表示到达 之前, 必定被有效写入;
- 若 ,表示 可能是不可移除的(例如数组指针、被保存指针)。
我们用具体示例展示在分析过程中抽象状态如何演化。先关注读/写集合(§3.1.1),然后是排除集合(§3.1.2),接着讨论函数调用(§3.1.3),最后扩展到结构体(§3.1.4)。示例中,标号形如 与 ,分别表示第 行语句之前与之后的程序点。
3.1.1 读/写集合
考虑下例,其中 f 对 x 发生有效写:
fn f(x: *mut i32, y: i32) {
*x = y;
let v = *x;
}第1行. 初始时读/写集合均为空。由于采用自底向上策略,我们对被分析函数的实参除了类型外一无所知。因此,把每个整数形参的抽象整数初始化为顶,把每个指针形参 初始化为 (即其符号指针,映射到顶)。于是初始抽象状态为:
在分析中,我们假设 与 不别名( 为不同变量)。该假设在具体执行中可能不完备,但它能避免“一处写入被解释为写到所有参数”,从而获得有意义的结果。
第2行. 对语句 *E1 = E2,我们计算 的抽象值(一个“抽象地址, 抽象整数”的对),并取其抽象地址分量。若该抽象地址为 ,则当且仅当 时,把 加入写集合;若抽象地址里含有多个指针,我们不更新写集合——因为无法断言写入必发生在其中任一指针上。本例只有一个指针对应该地址,且读集为空,因此更新为:
第3行. 对语句 let v = *E,我们计算 的抽象地址,并把所有满足“ 出现在该地址中”的 加入读集合,但仅当 (即尚未被有效写)时才加入。本例中 已在写集中,因此读集保持不变:
至此函数分析结束。由于在函数返回点处 ,我们得出结论: 是一个输出参数(且为 must-输出)。
3.1.2 排除集合(Exclude Sets)
请看下面这个示例,其中 y 与 z 是不可移除的参数:
fn f(x: *mut *mut i32, y: *mut i32, z: *mut i32) {
*x = y;
*z.offset(1) = 0;
// ...
}第1行. 开始时,排除集合为空:
第2行. 在分析表达式 时,设 与 分别为 与 的抽象地址。若 中包含某个形参 的符号指针 ,则把所有满足“其符号指针 属于 ”的 加入排除集合。原因是:被存入函数返回后仍可访问位置的指针不可移除。在当前代码中,x 与 y 的抽象地址分别是 与 ,因此把 y 加入排除集合:
第3行. 若一条语句包含形如 E1.offset(E2) 的表达式,就把所有满足“其符号指针 出现在 的抽象地址中”的 加入排除集合。因为 C2Rust 会把 C 的数组下标运算翻译为 Rust 的 offset 方法调用——这表明 x 是数组指针,因此不可移除。在当前示例中,z 的抽象地址是 ,于是将 z 加入排除集合:
由于 y 与 z 属于排除集合,它们被视为不可移除参数;即便它们出现在写集合中,后续的变换也不会移除它们。
3.1.3 函数调用(Function Calls)
由于我们先分析被调函数再分析调用者,因此在分析调用者时会复用被调函数的分析结果。考虑下面的例子,其中 f 调用 g:
fn f(x: *mut i32, y: *mut i32, z: *mut i32) {
g(x, y, z);
}
fn g(a: *mut i32, b: *mut i32, c: *mut i32) { /* ... */ }假设对 g 在其返回点处的分析结果为:
含义是:实参1可能被有效读,实参2必定被有效写,而实参3可能不可移除。f 传入 x,y,z,其抽象地址分别为 、、。因此,对 g 的调用将调用者的抽象状态更新为:
当某个实参的抽象地址中包含多个指针时,为保持写集合的欠近似,我们不更新写集合;而读/排除集合由于是过近似,仍按常规更新。
递归函数会带来额外挑战:在分析函数本身时,其被调函数(也就是它自己)的分析结果尚不可用。我们采用迭代式分析解决该问题。初始迭代中,假设该函数永不返回来进行分析;随后的迭代使用前一次得到的结果继续分析,如此往复直到收敛。考虑如下递归函数:
fn f(x: *mut i32, y: u32) {
if y == 0 {
*x = 1;
} else {
f(x, y - 1);
}
}- 第一次迭代:因为假设
f不返回,第5行(函数末尾)只能从第3行到达,于是有 - 第二次迭代:由上一次结果可知第4行处函数会返回,因此
现在第5行可以从第3行和第4行到达,需要对两处写集合做 join(这里写集合的 join 是交集):
再进行一次迭代就足以收敛。于是我们可以判定:x 为输出参数。处理相互递归时,我们初始同样假设循环中的所有函数均不返回,再迭代分析直至全部函数的结果收敛。
3.1.4 结构体(Structs)
将分析扩展到结构体是直接的:需要把“抽象读/写/排除集合”的元素从变量提升为极大路径(见§2)。若 出现在表达式 的抽象地址中,则表达式 (*E).l1.···.lm 会把所有前缀为 的极大路径加入读集合(已在写集合中的除外)。类似地,若 (*E1).l1.···.lm = E2,且 的抽象地址为 ,则把所有起始于 的极大路径加入写集合(已在读集合中的除外)。
3.2 写集合灵敏度(Write Set Sensitivity)
§3.1 的分析能够识别 must-输出参数,但不能识别 may-输出参数。看下面这个示例,其中 x 就是一个 may-输出参数:
fn f(x: *mut i32, c: bool) -> i32 {
let mut v = 0;
if c {
*x = 1;
} else { v = 1; }
v
}当 c 为真时,f 会写入 x 并返回 ;否则它不会写入 x 并返回 。然而,仅用前述分析无法判断 x 是输出参数,因为写集合是欠近似的。由于第 4 行向 x 写入,我们得到:
另一方面,第 5 行没有写入 x,得到:
由于写集合的 join 为交集,在第 6 行我们得到:
于是 x 不属于第 6 行的写集合,进而不会被判定为输出参数。
为克服该局限,我们引入写集合灵敏度:对不同的写集合进行区分。具体地,把“抽象状态”的定义从“以程序点为键”改为“以 (程序点, 抽象写集合) 为键”的到积:
第 4、5 行的分析与之前相同,只是现在它们分别与不同的写集合绑定:
但在第 6 行,由于写集合不同,我们不对它们做 join:
由此我们得出:x 在某些执行中被有效写入,而在另一些执行中不被写入,因此它是一个 may-输出参数。进一步地,我们自然得到两种情形下的可能返回值:当写入 x 时为 ,否则为 。我们还需要找出 x 被完全写入的程序点:检查所有“向 x 写入”的语句,若其之前的写集合不含 x、而之后的写集合包含 x,则在该语句处把 x 判为“完全写入”。依此标准,本例中第 4 行满足条件。
然而,写集合灵敏度在遇到结构体与循环时可能代价极高。看下面的代码(C2Rust 会把 C 的 switch-case 翻译成 Rust 的 match):
struct S { a0: i32, /* ... */, a9: i32 }
fn f(x: *mut S) {
...
while c {
match v { 0 => { (*x).a0 = 0; } /* ... */ 9 => { (*x).a9 = 0; } _ => {} }
...
}
}结构体 S 有 10 个字段,从 a0 到 a9。f 在每次迭代中只写其中一个字段(取决于 v 的值)。若对该循环采用写集合灵敏度,则会出现 种不同的写集合(因为不同执行会写入 10 个字段的不同组合)。这意味着循环中的每个程序点都要在 1024 个不同上下文下分析,耗时巨大。对写集合使用 widening 也无济于事,因为敏感的前提下这些写集合不会被 join。
一个折中方案是对循环不敏感分析:在循环内的每个程序点上把写集合合并。但这样会漏检那些“在循环内仍可负担地敏感分析”的输出参数。例子如下:
fn f(x: *mut i32) { /* ... */ while c { if d { *x = 0; } /* ... */ } }若敏感分析,x 被判为 may-输出参数,且由于仅出现两种写集合,能在合理时间内结束;若不敏感分析,则 x 不会被判为输出参数。
因此,更可取的方案是:仅对代价不高的循环做敏感分析,对其余循环做不敏感分析。问题在于:在分析前我们无法预知某个循环是否昂贵。为此,我们采用尝试-重启策略:从用户处接收一个超参数 max sensitivity ,初始时把所有循环按敏感方式分析;若某个循环内的某程序点出现超过 种不同写集合,则以不敏感方式重新开始对该循环的分析。 时等价于“所有循环不敏感”; 时等价于“所有循环敏感”。
事实上,当前的写集合灵敏度用法在理论上是不完备(unsound)的:不同的写集合不代表互不相交的具体状态集合。由于写集合是欠近似的,出现 只能说明“ 可能被有效写入,也可能未被有效写入”,并不能保证“ 一定未被有效写入”。因此,两个不同的写集合可以覆盖同一个具体状态;例如 与 都可以近似“x 与 y 均被有效写入”的状态。
要使写集合灵敏度变得完备,有两条途径:
(1) 正确 join 不同写集合关联的状态【Kim et al. 2018】。例如在上面的示例(Listing 1)中,第 6 行可以这样分析:
我们仍能断定 x 是输出参数,但返回值已不精确:无论是否写入 x,都可能是 。由于后续变换需要精确识别返回值,我们选择在此牺牲完备性。
(2) 让每个写集合精确追踪“被写入指针的精确集合”。当前的欠近似源自三方面:
- 首先,我们对读集合做过近似,且只有当形参不在读集合中时,才可把它加入写集合。因此也必须让读集合精确(这相当于引入读集合灵敏度);
- 其次,当某个抽象地址包含多个指针时,从它读取会让读集合不精确,向它写入会让写集合不精确。为解决该问题,需要为该抽象地址中的不同指针分别维护读/写集合;
- 最后,对循环不敏感分析会使循环内的读/写集合被合并。要避免此问题,就必须对所有循环进行敏感分析。
然而,这些改动会显著降低分析的可扩展性。权衡之后,我们选择牺牲完备性以换取可扩展性与后续变换所需的返回值精度。
3.3 空值性灵敏度(Nullity Sensitivity)
本小节聚焦带空值检查代码的分析,目标是在不把 must-输出参数误判成 may-输出参数的前提下,准确识别不可移除参数。请看下面两段代码:
fn f(x: *mut i32) {
if !x.is_null() {
*x = 1;
}
}fn f(x: *mut i32) {
if !x.is_null() {
*x = 1;
} else { println!("null!"); }
}一个精确的分析应当得出:Listing 2 中的 x 是 must-输出参数;而 Listing 3 中的 x 是不可移除参数。
若我们把 (分配给形参 的符号指针)解释为“非空指针”,会得到错误的结果:在分析 Listing 3 时,条件 !x.is_null() 恒为真,使得第 4 行不可达,从而无法检测到 f 的“仅在空指针时的特定行为”,进而把 x 误判为可移除。
反过来,若把 视作“可空指针”,同样得不到正确结果:此时 !x.is_null() 既可能为真也可能为假。因此在 Listing 2 中,第 4 行可由第 2、3 行两侧到达,导致如下分析结果:
从该结果只能推出:“x 可能未被有效写入”,但不能推出“仅在空时不写”。于是 x 被误判为 may-输出参数。
为提高精度,我们引入空值性灵敏度,区分“ 为空 / 非空”。记 为抽象空集的集合,每个元素是一个变量集合。相应地,抽象状态的定义修订为:
与写集合相似,我们对空集做欠近似:其顶元素的具体含义是空集,而 join 运算使用交集。
当以空值性灵敏度分析 E.is_null() 时,若 的抽象地址为 ,我们派生出两个互异的空集上下文:一个保持当前空集,另一个在当前空集中加入 。在前者关联的状态里,E.is_null() 为 false;在后者关联的状态里,它为 true。对 Listing 2 应用后得到:
因为当 x 非空时会被有效写入,我们可以把 Listing 2 中的 x 正确归类为 must-输出参数。对 Listing 3,分析得出第 4 行在如下状态下可达:
这意味着程序中存在“仅当 为空时才可达的程序点”,从而可把 x 正确归类为不可移除参数。
由于空集同样采用欠近似,空值性灵敏度与写集合灵敏度一样在理论上不完备;可采用与前文相同的办法来保证完备性。但在实践中,我们更重视精度与可扩展性,因此优先考虑它们而非形式完备性。
笔者注:说白了就是当总体规模较小时枚举所有情况排列组合,规模较大时放弃分析
4. 代码转换:移除输出参数
在本节中,我们根据分析结果,描述对 C2Rust 生成的 Rust 代码所做的转换。需要注意的是,分析结果并不能完全捕捉程序员的意图。即使在不改变程序行为的情况下可以移除某个输出参数,开发者也可能更愿意保留它。我们建议一种务实的做法:让程序员提供一份他们希望保留的参数清单。
我们分别演示针对必定产生输出的参数(§4.1)和可能产生输出的参数(§4.2)的代码转换。为清晰起见,我们给出若干示例,展示转换前后的代码片段,并逐行解释修改内容。该转换的目标是:(1)通过用元组与 Option/Result 类型取代输出参数,引入符合 Rust 习惯用法的函数签名;(2)修改函数体以与这些新签名保持一致。与原始签名相比,新的签名为程序员提供了有关函数行为的更精确信息,从而提高代码可理解性。然而,函数体中的修改(例如增加额外的局部变量并使数据流更加复杂)可能会对可读性产生负面影响。我们认为,通过进一步的转换对函数体进行简化可以提升可读性;在展示我们的代码转换之后,我们会简要讨论潜在的简化策略。
4.1 必输出参数(Must-Output Parameters)
考虑下列对函数 f 的两种定义:左侧为转换前的原始代码,其中 x 是一个必输出参数;右侧为完成转换后的代码。

- 第 1 行。 我们移除了类型为
*mut i32的输出参数x,并在返回类型中加入i32,将返回类型改为 。 - 第 2 行。 我们新引入一个类型为
i32的变量xv,并赋予任意初值。原本存入输出参数的值,现在存入xv。此外,我们将x重新定义为指向xv的指针,从而保证引用x的表达式无需修改即可保持语义正确。 - 第 3 行。 对于每个
return,我们构造一个元组,既返回原有的返回值,也返回xv。 - 第 4–6 行。 调用处移除实参
x,并将f返回的元组解构为v0与v1。若x非空,则将v1赋给x。随后,用v0取代原先的返回值使用处。
我们可以通过删除仅用于间接赋值与解引用且未被传递给函数或分配给其他变量的局部变量,来简化函数体以增强可读性:如果 x 仅用于 *x 这样的写入,那么可将 *x 替换为 xv 并移除 x。此外,若 xv 在 return 之前立即被写入,那么 xv 也可以直接移除,改为直接返回该写入的值。这些简化都可以通过语法层面的转换轻松实现。
4.2 可能输出参数(May-Output Parameters)
我们采用两种方法来移除可能输出参数。若我们无法辨识能够指示成功(函数确实向该参数写入)与失败(函数未向该参数写入)的返回值,则保留原有返回值,并额外返回输出参数的值,组合为一个元组(见§4.2.1)。反之,若能够识别出此类返回值,则移除原有返回值,只返回输出参数的值(见§4.2.2)。
为了识别指示成功与失败的返回值,我们依赖分析结果:分析会在“输出参数被写入”时计算函数可能的返回值。若存在多个这样的返回值,它们不仅表明“写入发生”(成功),也通过其具体取值向调用者提供了额外信息。在这种情况下,若删除原有返回值,就会阻止调用者获取超越“成功/失败”二元结论的必要信息,因此必须保留原有返回值。另一方面,若存在一个唯一的值 ,我们将其与“输出参数未被写入”时的返回值集合(同样由分析计算)进行比较:如果在这些返回值中能找到 ,就不能把 视为成功指示;反之,若 不在这些返回值之中,我们就得出 的确表示成功。
为便于成功识别返回值,我们在分析整数时采用集合域(set domain)而非区间域(interval domain)。例如:若一个函数以 表示成功、以 或 表示失败,则集合域可直接得出 。然而在区间域下,区间 会包含 ,从而妨碍我们识别 为成功指示。
4.2.1 保留原始返回值(Retaining Original Return Values)
考虑对函数 f 的如下两种定义。转换前, 是一个“可能输出”参数,且返回值恒为 。

- 第 1 行。 移除输出参数
x,并把返回类型改为 。 - 第 2 行。 与§4.1一致:用本地变量
xv承接原输出参数的值,并把x重定义为指向xv的指针。 - 第 3 行。 引入布尔变量
xw,用来记录 是否被完整写入。 - 第 4 行。 根据分析,在该行当条件满足时, 会被完整写入,因此将
xw置为true。 - 第 5–6 行。 在保留原有返回值的同时,若 被完整写入则返回
Some(xv),否则返回None。 - 第 7–10 行。 若
v1为Some(v),则使用if let表达式把 赋回调用点的x(参见 Rust 2023g)。其余变更与§4.1相同。
备注:我们也可用
Result<T, ()>代替Option<T>作为返回类型,其中 为单元类型;这主要是风格偏好问题。
为提升可读性,还可以简化 return 语句:原本依赖 xw 在 Some(xv) 与 None 之间二选一。若分析结果表明在到达某个 return 之前 必然已被写入,则可直接返回 Some(xv) 而无需检查 xw;同理,若 必然未被写入,则可直接返回 None。如果据此简化使得 xw 从未被读取,就可以移除 xw 的定义与赋值。注意:本文提出的分析已经足以提供完成上述简化所需的信息。
4.2.2 移除原始返回值(Removing Original Return Values)
考虑对函数 f 的如下两种定义。转换前, 是“可能输出”参数,且返回值以 表示成功、以 表示失败:

- 第 1 行。 移除
x并把返回类型改为Result<i32, i32>:第一个i32对应输出参数的类型,第二个i32对应原始返回类型。 - 第 2–5 行。 与§4.2.1中的修改一致。
- 第 6 行。 若 被完整写入,则返回
Ok(xv);否则返回Err(y),其中y为原始返回值,可能携带与失败相关的信息。 - 第 7–10 行。 用模式匹配替换原代码中基于返回值的判断与随后的分支动作(成功分支与失败分支)。
有时对 f 的返回值并不会立即检查(而是把返回结果赋值给中间变量y),例如:
转换前调用处
let y = f(x, c);转换后调用处
let y = match f(c) {
Ok(v) => { if !x.is_null() { *x = v; } 0 }
Err(v) => { v }};在这种情形下,我们通过模式匹配重建原始的返回值:成功时, 由分析结果给出;失败时,从 Err 中提取该值。注意:若失败指示值是唯一的,则可用 Option<T> 代替 Result<T, E>。
5. 评估(EVALUATION)
在本节中,我们使用 55 个真实世界的 C 程序来评估我们的方法。首先,我们描述实现于 Nopcrat 的系统,它体现了我们的思路(§5.1),以及收集基准程序的流程(§5.2)。我们的实现与基准程序均已公开(Hong and Ryu 2024)。随后,我们围绕以下研究问题来评估本方法:
- RQ1. 可扩展性: 它能否高效地分析并转换大型程序?(§5.3)
- RQ2. 有用性: 它能识别出多少输出参数?为移除这些参数需要进行到何种程度的代码修改?(§5.4)
- RQ3. 正确性: 它是否能在保持语义不变的前提下转换代码?(§5.5)
- RQ4. 对性能的影响: 移除输出参数对程序性能有何影响?(§5.6)
我们的实验在一台 Ubuntu 机器上进行,配置为 Intel Core i7-6700K(4 核、8 线程、4GHz)与 32GB 内存。最后,我们讨论可能影响结论有效性的威胁(§5.7)。
5.1 实现(Implementation)
我们在 Rust 编译器之上实现了 Nopcrat(Rust 2023a)。系统在将 Rust 代码降至 Rust 的中层中间表示(MIR)(Rust 2023c)之后对其进行分析;MIR 将函数表示为包含基本块的控制流图。为进行代码转换,Nopcrat 依赖 Rust 的高层中间表示(HIR)(Rust 2023b),它类似抽象语法树,但已去除语法糖并完成符号解析。我们使用了 C2Rust v0.18.0,并做了少量修改。
此外,在分析和转换之前,我们需要对 C2Rust 的输出进行后处理。原因是 C2Rust 将每个 C 文件翻译为一个 Rust 文件,把其他文件中的定义声明为 extern 定义,并在链接期解析函数调用。然而,Rust 提供了用于导入定义的 use 关键字,并且这些导入会在编译期进行类型检查。因此,为确保我们在转换过程中对函数签名的改动能够正确地影响类型检查,我们需要将这些 extern 定义替换为 use 语句。Emre 等人(2021)提出的 ResolveImports 工具可以完成该后处理,但其支持的是更早版本的 C2Rust。为此,我们实现了一个工具,对 C2Rust v0.18.0 的输出执行相同的任务。
尽管我们的实现使用 C2Rust 进行语法层面的翻译,但并不排斥其他 C→Rust 翻译器。我们实现的分析器假定输入的 Rust 代码只使用与 C 等价的特性,不包含 Rust 特有的特性,如安全引用、trait 与泛型。任何遵循此约束的现有 C→Rust 翻译器都可以替代 C2Rust。反过来,若某些工具通过引入 Rust 特性来改进 C2Rust 的输出(Emre et al. 2023, 2021; Hong and Ryu 2023; Zhang et al. 2023),则与我们当前的实现不兼容。不过,这一限制并非我们方法本身所固有;若要扩展实现以支持这些 Rust 特性,是可行且不会带来显著挑战的。
5.2 基准程序收集(Benchmark Program Collection)
我们从两个来源收集了基准程序:(1)CROWN 使用的那些程序(Zhang et al. 2023),以及(2)GNU 软件包。由于 CROWN 的基准集合主要由小型程序组成(少于 5k 行代码),我们决定用来自 GNU 软件包的大型程序进行扩充。起初,我们从 GNU Package Blurbs(GNU 2023)所列的软件包中收集了 41 个,所有这些 C 程序都满足以下条件:
- 规模不超过 100k 行代码(用
cloc衡量)(Danial 2023); - 能在我们的 Ubuntu 机器上成功编译;
- 知名度较高,即该软件包在维基百科上有单独条目。
在翻译这些程序的过程中,C2Rust 在 4 个软件包(adns、gmp、parted、readline)上发生崩溃。另外,在两个软件包(bison 与 m4)中,由于存在同名但类型不同的定义,我们无法用 use 替换 extern 声明。排除这些之后,我们得到一个最终集合,包含 35 个软件包。将它们与来自 CROWN 的 20 个程序合并,我们总共获得 55 个基准程序。需要说明的是,C2Rust 偶尔会产生类型错误的 Rust 代码,主要由缺失的类型转换引起,我们对这些问题进行了手工修复。表1 报告了这些基准程序的规模。
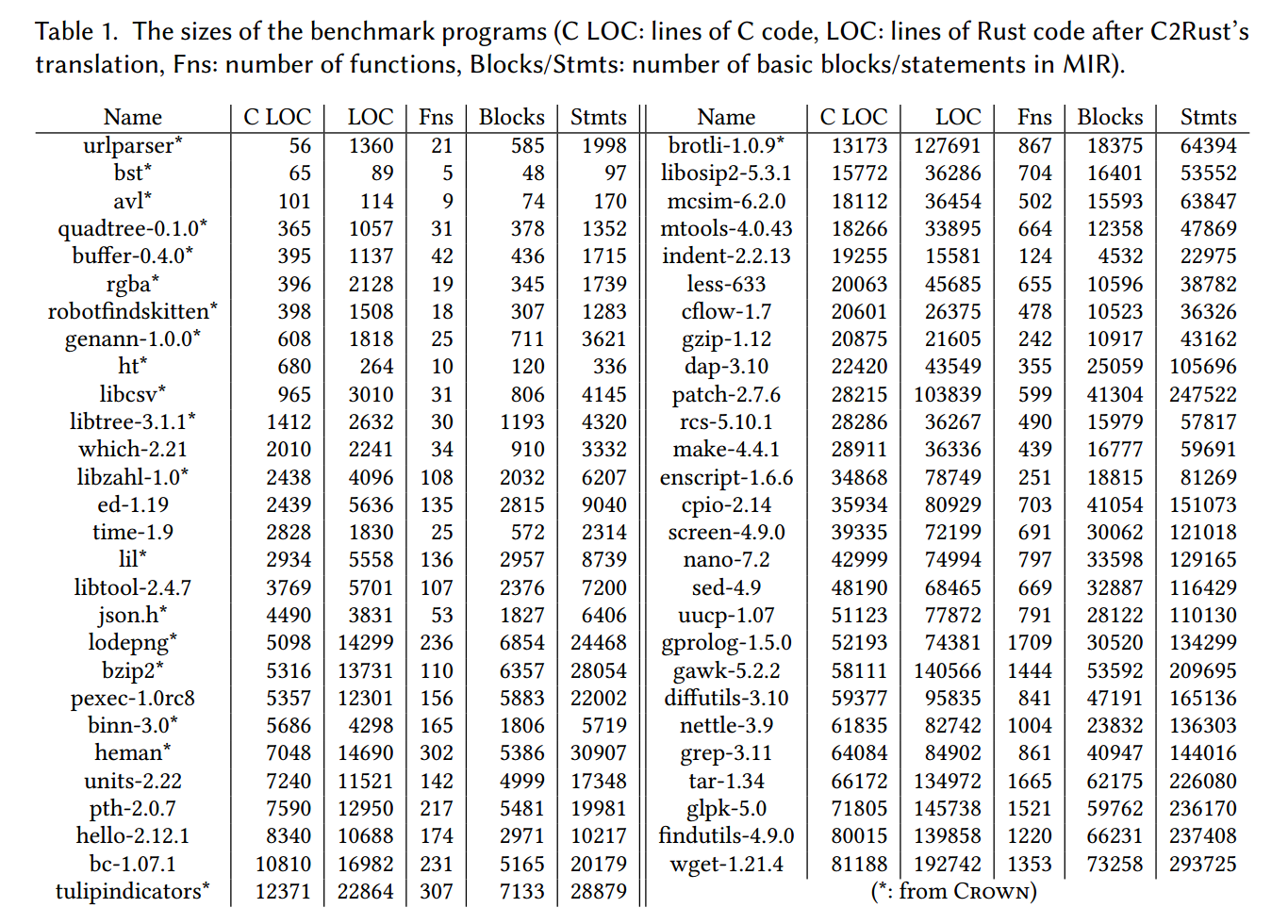
5.3 RQ1:可扩展性(Scalability)
我们通过分析与转换代码所需时间来评估所提方法的可扩展性。实验结果表明该方法具有良好的可扩展性:对每个基准程序,分析与转换都能成功完成,且最长耗时为 213 秒。本小节对结果作详细说明。
我们首先考察 max sensitivity(记为 )对复杂循环成功分析的影响。我们取 为从 到 的若干值,以及 。由于在循环中一旦出现对“另一个指针”的写入,可能写集的数量会翻倍, 以指数方式增大(每次翻倍)。图4a 给出了各个 取值下,能被成功分析的程序数量。实验在 32GB 内存约束下进行;若超出该上限,则会因内存不足而导致分析失败。
当 时,我们能成功分析全部 55 个程序。但随着 增大,失败的程序增多;当 时,只有 47 个程序仍可被分析。原因是分析高 的循环时,需要构造大量不同的写集合,消耗显著内存。我们认为,现有的一些技术(例如稀疏分析;Hardekopf and Lin 2009; Oh et al. 2012)有望用于降低内存消耗,从而使更多高 的程序可被分析。
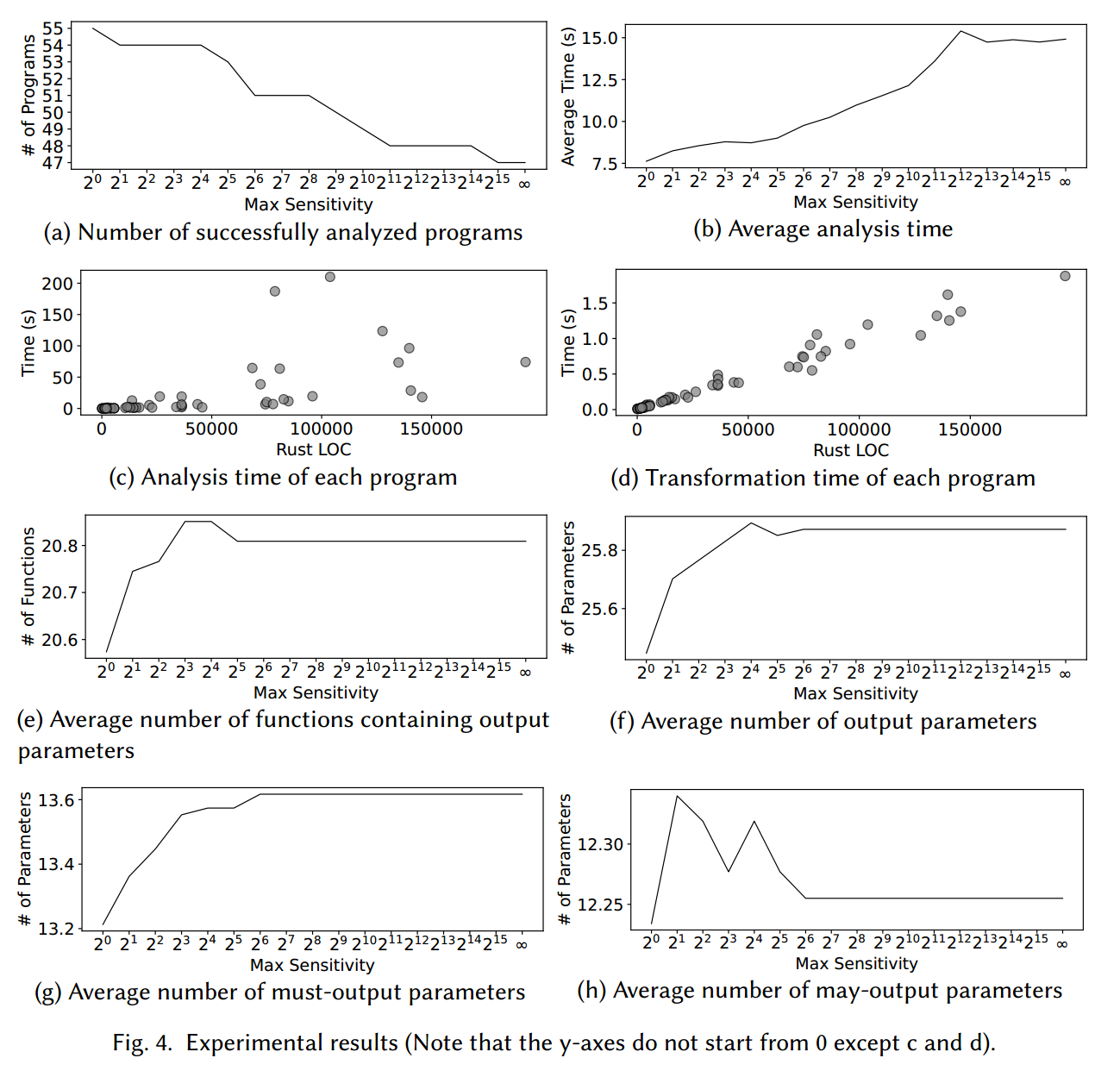
接着我们讨论不同 对分析时间的影响。这里,我们只讨论无论 取值如何都能被分析的 47 个程序。图 4b 展示了不同 下的平均分析时间:当 时为 7.6 秒;随着 增大而增加,在 时达到 14.9 秒。注意,分析仅在整个翻译流程中执行一次。因此,除非分析时间极长,一般优先考虑精度是合理的。鉴于分析时间的增加幅度适中,出于工程实用性,选择更高的 值是可取的,因为这允许获得更高精度。
随后我们研究程序规模对分析时间的影响。令 ,对全部 55 个程序进行考察。图 4c 将每个程序的分析时间与其 Rust 代码行数(LOC,横轴)作图。整体上,分析时间随 LOC 增大而上升,但相关性并不强。例如:一个 139k LOC 的程序(glpk)仅耗时 18 秒,而 110k LOC 的程序(patch)却耗时 211 秒。这源于我们分析的自底向上特性:各函数相互独立地被分析。单个函数的分析时间相对于其自身规模往往呈超线性复杂度。因此,分析一个复杂函数会比分析多个简单函数耗时更多。以 patch 为例,单个函数 yyparse 含 7,526 个基本块与 46,878 条语句,单独就耗费 115 秒(在总计 211 秒中)。
最后,我们考察转换时间。在该实验中,我们对每个程序采用“该程序能承受的最高 ”所得到的分析结果来执行转换。图 4d 表明:每个程序都能在 2 秒内完成转换,并且转换时间与 LOC 近似线性相关。这种线性关系来自于:转换基于分析结果进行直接的语法树遍历,流程相对简单。
5.4 RQ2:有用性(Usefulness)
我们评估所提方法在自动移除输出参数、减轻程序员负担方面的有用性。若满足以下两点,我们认为方法是“有用的”:
(1) 能在真实代码中识别出大量输出参数;
(2) 移除这些参数需要相当规模的代码修改。
为衡量有用性,我们统计“识别出的输出参数数量”以及“移除它们所需的代码改动规模”。
实验结果验证了方法的有用性:对每个程序采用其能承受的最高 ,在全部 55 个程序上,我们平均识别出 30.4 个输出参数,其中 15.5 个为必输出参数、14.9 个为可能输出参数,分布在平均 24.4 个不同函数中。有 13 个程序(avl、bst、buffer、genann、ht、libcsv、libtree、libzahl、quadtree、robotfindskitten、time、tulipindicators、urlparser)没有输出参数,其余程序至少有 1 个。我们认为“平均 30.4 个输出参数”是衡量该方法有用性的一个强信号。移除这些已识别的参数,平均需要修改 13.9 个文件,涉及新增 313.6 行与删除 285.3 行代码。若手工完成这些修改,工作量十分可观。
由于分析可能产生漏报(false negative),我们进行了人工检查:从每个程序中随机挑选 1 个函数(其某个参数未被识别为输出参数),共 55 个函数;我们对这些参数进行人工验证,判断它们是否确为漏报。在 tulipindicators 的如下函数中,我们发现了1 个漏报:
fn tc_config_set_to_default(mut config: *mut tc_config) {
memcpy(config, tc_config_default(), size_of::<tc_config>()); }分析器由于缺少 C 库函数模型,未能将 memcpy 识别为对 config 的写入。通过为库函数建立模型即可解决。尽管此项调查并不穷尽,但它表明我们提出的分析具有较低的漏报率。
接下来我们分析不同 值对“识别输出参数”的影响。图 4e、图 4f、图 4g、图 4h 分别给出了对“能在任意 下被分析”的 47 个程序,在每个 取值下的平均数量:
(i)包含输出参数的函数数;
(ii)输出参数总数;
(iii)必输出参数数;
(iv)可能输出参数数。
随着 的增加,分析精度提升,因此识别到的输出参数数量总体上随 增加而增加,但也存在个别例外——这是因为一些在小 下无法识别(或被判定为不可移除)的参数,会在更大的 下被识别出来。此外,随着 增加,可能输出参数的数量先上升后下降:其下降的原因在于,其中一部分会在更高的 下被重新分类为必输出参数。
5.5 RQ3:正确性(Correctness)
我们通过检查转换后的程序是否与原程序保持相同语义来评估所提方法的正确性。若分析产生误报(false positives),则在转换阶段会错误地移除并非输出参数的参数,从而改变程序语义。为进行评估,我们对每个程序使用其自带测试套件;在 55 个程序中,有 26 个带有测试。转换之前,这 26 个程序全部通过其测试;转换之后,其中 25 个仍然通过。唯一失败的程序是 tar,原因在于下述特定函数:
static mut current_format: archive_format;
fn decode_header(format_pointer: *mut archive_format, /* ... */) {
*format_pointer = format;
/* ... */
if current_format == GNU_FORMAT { /* ... */ }
/* ... */
}
decode_header(&mut current_format, /* ... */);分析将 format_pointer 判定为必输出参数。这并非误报:该参数总是会被函数写入。问题在于:某个调用点将全局变量 current_format 的指针作为实参传入,而 decode_header 在写入 format_pointer 之后又读取了 current_format。因此,从 current_format 处读取到的值应当与写入到 format_pointer 的值一致。然而,如果我们移除了 format_pointer,并把它重定义为指向局部变量的指针,那么对它的写入将不再影响 current_format,从而改变了函数语义。我们验证了:若在转换时手动将 format_pointer 排除在“应移除的输出参数”之外,转换后的程序就能通过测试。
为解决该问题,我们需要扩展“不可移除参数”的定义,将上述模式囊括其中,并相应调整分析:需要识别“指向全局变量的指针”。当前的实现把所有全局变量视作一个单一的抽象内存位置;我们可以修改分析,使其能够区分不同的全局变量。
由于实验未发现误报,我们进一步进行了人工调查。我们从每个包含“已识别的可能/必输出参数”的程序中随机选择 1 个函数,共得到 41 个具有可能输出参数的函数与 41 个具有必输出参数的函数。随后,我们人工检查这些被识别的参数是否确为输出参数。结论是:41 个必输出参数全部为真阳性;但在 41 个可能输出参数中,有 1 个实际上是必输出参数。该参数出现在 hello 程序的如下函数中:

左边是原始 C,右边是 C2Rust 的翻译。参数 m 实际上是一个必输出参数,原因是:(1)除非执行流到达 default 分支(第 4 行缺少 break,因此存在贯穿),函数都会对 m 写入;并且(2)default 分支会将 lose 置为 1,随后程序退出。由于 Rust 的 match 不支持贯穿,C2Rust 将带有贯穿的 switch 翻译为:先给一个临时变量 block 赋值,再由条件语句基于 block 进行检查。当控制流汇合(上例中第 7 行)时,分析器会将 block 与 lose 的取值都视为可能为 或 ,从而未能识别出“当未写入 m 时,函数总会退出”这一事实。这表明:直接分析原始 C 代码可能比分析已翻译的 Rust 代码得到更精确的结果。将 m 误判为“可能输出参数”会导致转换后代码不够 Rust 惯用(例如函数会返回 Some,但从不返回 None)。尽管如此,这种误判不会改变程序行为。结合实验与人工调查未发现误报,我们认为本分析的精度足以满足实际使用。
5.6 RQ4:对性能的影响(Impact on Performance)
在移除输出参数时,一个合理的担忧是目标程序可能出现性能下降。与“向输出参数写入”相比,直接返回一个值可能会触发值复制,在处理大型结构体时尤为昂贵。然而,得益于编译器优化,即便返回了值也未必会发生复制,因此性能影响可能可以忽略。
为考察这一问题,我们通过运行各程序的测试套件来测量性能。由于这些套件并非专为性能评估设计,其执行时间可能不够稳定。为保证结果可靠,我们剔除了单次执行时间低于 0.1 秒的测试套件,最终剩余 20 个程序参与评测。每个测试套件重复执行 12 次,并在剔除最快与最慢两次后,基于剩余 10 次计算平均执行时间。我们比较 Rust 程序在转换前后的执行时间,并以 --release 选项编译以启用优化。
结果显示:与原版本相比,转换后的程序平均仅出现0.5% 的减速。具体来看,原版本在 11 个案例中更快;而转换后的版本在 9 个案例中更快。由此可见,移除输出参数并不会带来显著的性能退化。
5.7 有效性威胁(Threats to Validity)
对我们评估结果构成主要威胁的是:在正确性与性能评估上依赖测试套件。通过测试并不等价于程序必然正确;但在实践中,测试套件是检验程序语义最常用的手段。此外,在开发过程中,我们曾经发现实现中的 bug,并且这些语义差异也通过测试套件的执行被揭示出来。至于性能,由于这些测试并非为此目的而设计,能否有效暴露性能差异并不明朗。
为补充我们的评估,我们还进行了一个额外的性能对比实验:比较原始 C 程序与C2Rust 生成的程序。结果观察到后者因翻译带来平均 11.5% 的减速。虽然深入分析该减速的原因超出了本文范围,但这一现象暗示——若确实存在显著的性能差异,测试套件能够有效揭示。
6. 相关工作(RELATED WORK)
6.1 转换 C2Rust 生成的代码(Transforming C2Rust-Generated Code)
已有若干工具被提出,用于把 Rust 的语言特性并入由 C2Rust 生成的代码。然而,它们当中没有任何一个专门针对“用元组与 Option/Result 替换输出参数”。CRustS(Ling et al. 2022)使用语法层面的替换规则,缺乏进行需要更深语义理解的复杂转换的能力。Laertes(Emre et al. 2023, 2021)与 CROWN(Zhang et al. 2023)都处理了“将不安全的原始指针替换为安全引用”。其中,Laertes 依赖 Rust 编译器的反馈来决定哪些原始指针可被转换为引用;与此相反,CROWN 对指针进行所有权分析,相较 Laertes 能把更广范围的指针转换为引用。另有 Concrat(Hong and Ryu 2023)专注于用 Rust 的锁 API替换 C 的锁 API,其方法是对锁的使用进行数据流分析。
6.2 面向 Rust 的静态分析(Static Analysis for Rust)
面向 Rust 的静态分析技术已出现若干,主要聚焦于缺陷检测。这些研究的目标是分析人工编写的 Rust 代码,而非像我们这样处理C2Rust 生成的代码。其中一项有代表性的工作是 MIRChecker(Li et al. 2021),它在抽象解释框架下进行静态分析,专门针对 Rust 程序中特有的缺陷模式(例如运行时 panic、生命周期破坏等),但并未提出新的灵敏度设定。另外,Rudra(Bae et al. 2021)与 SafeDrop(Cui et al. 2023)通过数据流分析来发现内存相关缺陷。
6.3 灵敏度(Sensitivities)
在抽象解释文献中,人们提出了多种灵敏度(sensitivity)设定。一般而言,这些设定旨在提升静态分析精度;而我们提出的写集合灵敏度与可空性(nullity)灵敏度则是专为提升输出参数识别的精度而设计的。
- 调用点灵敏度(call-site sensitivity)(Might et al. 2010; Sharir and Pnueli 1981; Shivers 1988)区分不同调用点对同一函数的调用。由于输出参数应当与调用上下文无关,我们的方法不采用调用点灵敏度。
- 抽象调用状态灵敏度(abstract call state sensitivity)(Sharir and Pnueli 1981)常用于自底向上分析,以区分函数的不同抽象输入状态。我们的可空性灵敏度可以看作其一个受限形式:它仅关注抽象输入状态中的“可空性信息”。
- 轨迹历史灵敏度(trace history sensitivity)/ 轨迹划分(trace partitioning)(Handjieva and Tzolovski 1998; Mauborgne and Rival 2005; Rival and Mauborgne 2007)区分不同的执行轨迹历史。我们的写集合灵敏度可视作一种受限形式,它专门关心对参数的有效写入历史。
- 对象灵敏度(object sensitivity)(Milanova et al. 2002, 2005; Smaragdakis et al. 2011)通常用于面向对象语言的静态分析。然而,C 与 Rust 都非面向对象语言,因此对象灵敏度不在我们的考虑范围内。
关于灵敏度的形式化综述,可参见 Kim et al.(2018)。
7 结论(CONCLUSION)
本文研究了在 C→Rust 翻译过程中移除输出参数的问题。我们的主要贡献在于:基于抽象解释框架,设计了一种静态分析技术来识别输出参数,并提取实现转换所需的关键信息。该技术引入了抽象读/写/排除集合、写集合灵敏度与可空性灵敏度。评估结果表明,所提方法具有良好的可扩展性与有用性,在多数情况下保持正确。