基于软件的生存机制保护
基于软件的生存机制保护
论文来自 IEEE International Conference on Dependable Systems and Networks 2001(DSN2001)的《Protection of software-based survivability mechanisms》。

碍于时间原因,大部分内容在机翻的基础上修改了明显错误内容,可以凑合着看。如有条件还是建议看论文原文。
摘要
许多现有的生存机制依赖于基于软件的系统监控。一些软件驻留在不一定值得信赖的应用程序主机上。因此,这些软件组件的完整性对于生存性方案的可靠性和可信度至关重要。
本文主要讨论通过软件转换在不可信主机上保护可信软件。采用的技术包括系统地引入别名,并分解程序控制流;通过别名指针将高级控制转换为间接寻址。
通过这样做,我们将程序转换为一种非常缓慢and/or精度很低的数据流信息形式。我们给出了一个理论结果,表明在一般情况下,对转换程序的精确分析是NP难的,并用实证结果证明了我们的技术的适用性。
1. Introduction
在构建可生存系统时,许多现有的机制依赖于基于软件的网络监控和管理。由于可生存机制的一些软件组件将在不一定可信的主机上执行,因此可生存性机制的可靠性和可信度非常值得关注。
在本文中,我们解决了潜在恶意环境中的软件保护问题。我们在可生存分布式系统的背景下研究这个问题[9]。在该系统中,软件探测器部署在网络节点上,用于监控和控制目的。
这些探测器是从一组受信任的服务器发出的。
每个探测器可以采用不同的算法来监视本地信息并与服务器通信。例如,不同的探测器可能使用不同的数据序列,使用不同的协议进行传输,或监测不同的信息。为了击败这种网络范围的监控机制,从而获得对网络的控制,对手必须推断出探测器在监控时使用的算法,或者探测器与服务器通信的协议。每种攻击都需要对程序行为有一定程度的了解,这可以通过程序获得。本文讨论了软件保护的一个重要方面——预防对程序的静态分析。
静态程序分析可以揭示有关程序的大量信息,例如控制流和运行时数据量的可能用途。这些信息可用于促进程序的动态分析,在某些情况下,有助于直接篡改程序。本文介绍了一种基于编译器的方法来强化软件抵御静态分析。基本方法包括一组旨在阻碍静态分析的代码转换。我们的方法与之前提出的代码混淆技术之间的关键区别在于,我们的技术得到了理论和经验复杂性度量的支持。如果没有复杂性度量,代码混淆技术充其量只是摆设。
软件保护问题已在其他研究中进行了研究。值得注意的包括INTEL的IVK项目、Collburg的代码混淆工作和移动密码学。IVK的工作创造了“防篡改软件”一词。他们的技术很新颖,但代价是运行时间成本相当高。
移动密码学研究提出了一种以加密形式执行程序的技术。在目前的形式下,该技术的适用性有限(例如有理函数)。
本文描述的方法是基于易于理解的编程语言原理开发的,这些原理是复杂性度量的基础。
我们的论文结构如下:在第2节中,我们介绍了这项工作所依据的系统模型和假设。第3节介绍了静态分析的基础知识。第4节和第5节介绍了阻碍控制流和数据流分析的转换。第6节讨论了拟议方案的理论和实践基础。第7节介绍了我们的实现和实验结果。
2. The system model
在本节中,我们将描述假设和系统模型,为讨论提供背景。我们的系统由一组通过网络连接的计算主机和一组在这些主机上运行的通信进程组成。主机分为两类:应用程序主机和生存性控制主机。与生存性控制任务相关的过程是在控制主机上运行的控制过程和在应用程序主机上执行的探测程序。探头负责本地监控和重新配置。控制过程从探测器收集监控信息,进行全网络分析,并在认为有必要进行实时更改时向探测器发出重新配置命令。系统架构的概述如图1所示。
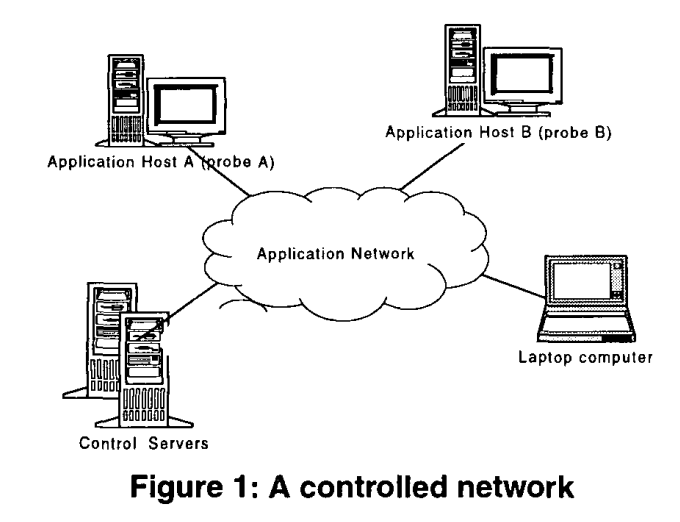
关于该系统的几个特征和假设对讨论很重要。它们列在下面:
- 可信控制服务器:在我们的系统中,控制服务器和在其上运行的控制进程被假定为可信的。
- 可信网络通信:我们假设控制进程和软件探测器之间的网络通信是可信的。
- 探测机制的多样性:在这个系统中,探测机制利用了两种形式的多样性,这对后面章节详细介绍的方法至关重要。它们是时间多样性和空间多样性。时间分集的形式是定期用可信控制服务器发出的新版本替换探测器。空间多样性是指在网络中安装不同版本的探测器。每个版本的探测器可能使用不同的探测算法、不同的协议与控制服务器通信,并且可能看起来具有不同的操作语义。这些多样性使得对手需要理解程序算法才能发起智能篡改或模拟攻击。
- 探测器和控制进程之间的高级别交互:在远程主机上执行时,探测器通过预定协议与其控制服务器保持高级别交互。假设探测器执行完整性检查,其结果由控制服务器验证。检查机制也是安装唯一的,因为每个探测程序都可以采用一组不同的检查。本文的任务不是设计检查机制。只需声明可以对软件本身及其执行环境执行完整性检查即可。完整性检查的结果为探测器的身份和真实性奠定了基础。
在这项工作中,我们主要感兴趣的是防御属于智能篡改和模拟攻击类别的复杂攻击。
智能篡改。智能篡改是指对手以某种特定方式修改程序或数据,使程序能够继续以看似不受影响的方式运行(从可信服务器的角度来看),但在损坏的状态或数据上。
模仿。模拟攻击类似于智能篡改,因为攻击者试图建立合法程序的流氓版本。区别在于前者试图模拟原始程序的行为,而后者旨在直接修改程序或其数据。
应该指出的是,这里不考虑拒绝执行攻击。在这种问题背景下,拒绝执行会产生直接的症状,这些症状很容易被可信服务器识别出来(例如通信中断)。与拒绝执行不同,智能篡改或冒充攻击可能不会立即显现;如果攻击者详细了解软件应该做什么以及实例化恶意副本的适当权限,他可以替换原始程序,使替换几乎无法检测到。因此,这种攻击有可能造成实质性的伤害,对手可以操纵程序执行看似有效但恶意的任务。
在存储了多样性方案和完整性检查的情况下,成功的智能篡改或模拟攻击需要了解探测算法和通信协议,以绕过或击败检查机制。这反过来又需要有关程序语义的信息,而我们正是努力保护这些信息。例如,考虑以下代码段:
int a = functionl();
int b = function2();
Check_for_intrusion(&a, &b);
···
p = &a;
integrity_check(p);如果对手篡改了Checkfbr-instruction()函数,他或她需要了解Checkfbr-intervention()功能是否以及如何更改a和b的值,以及a或b是否会在程序中稍后使用。如果没有这些知识,当调用integrit)l-check(p)时,他的行为就会被揭示出来。
我们的前提是,旨在以智能方式篡改或冒充程序的对手必须理解其行为的影响,这归结为对程序语义的理解。获得这种理解的一种方法是通过程序分析。
本文讨论了程序分析的障碍,特别是程序的静态分析。我们的方法包括一个代码转换框架,旨在增加静态程序分析的难度,这将在后面的部分中进行描述。
3. Static analysis of programs
静态分析是指从计算机程序的静态图像中提取信息的技术,通常比动态执行的分析(如模拟执行)更有效。
从软件保护的角度来看,静态分析可以为软件的有针对性的操作提供有用的信息。再次考虑上一节中的代码示例。use-def分析之前的代码段的将很快发现:函数Checkjor-instance()中数据量a的定义将传播到函数integrity_check()中使用(通过其别名p)。基于这一知识,对手可以对Checkfbr-instruction()执行特定的修改,只要他保留了a的语义以供以后使用。
静态分析包括程序控制流敏感和不敏感。流不敏感分析更高效,但代价是精度较低。流敏感分析首先构建程序的控制流图(CFG)。这样的图由作为基本块的节点和指示块之间控制转移的边组成。然后,分析继续解决基于CFG的数据流问题。
值得注意的是,控制流分析是分析的第一阶段,它提供了有关程序调用结构和控制传输的信息,这对后续的数据流分析至关重要。没有这些信息,数据流分析仅限于基本块级别,对于数据使用依赖于程序控制流的程序来说,从根本上来说是无效的。
我们击败静态分析的方法的技术基础是将程序控制流转换为高度依赖数据的性质;也就是说,控制流和数据流分析是相互依存的。这种相互依赖的结果是:(1)两种分析的复杂性都增加了;(2)分析精度降低。
4. Degeneration of control-flow (控制流退化)
在普通程序中,当分支指令和目标易于识别时,确定CFG是一个简单的操作——这是一个复杂度为O(n)的线性操作,其中n是程序中基本块的数量。
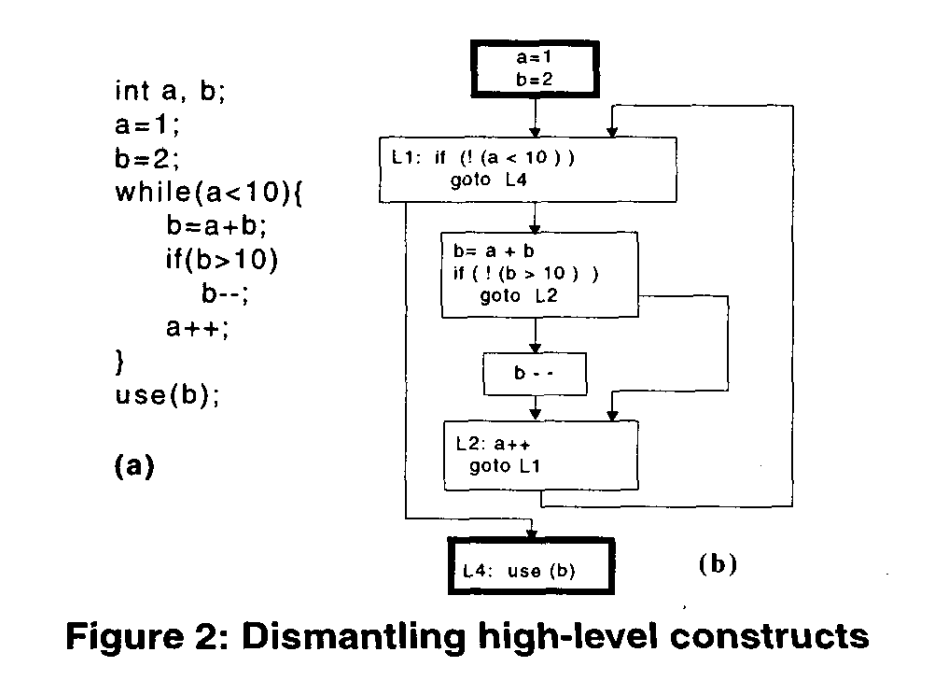
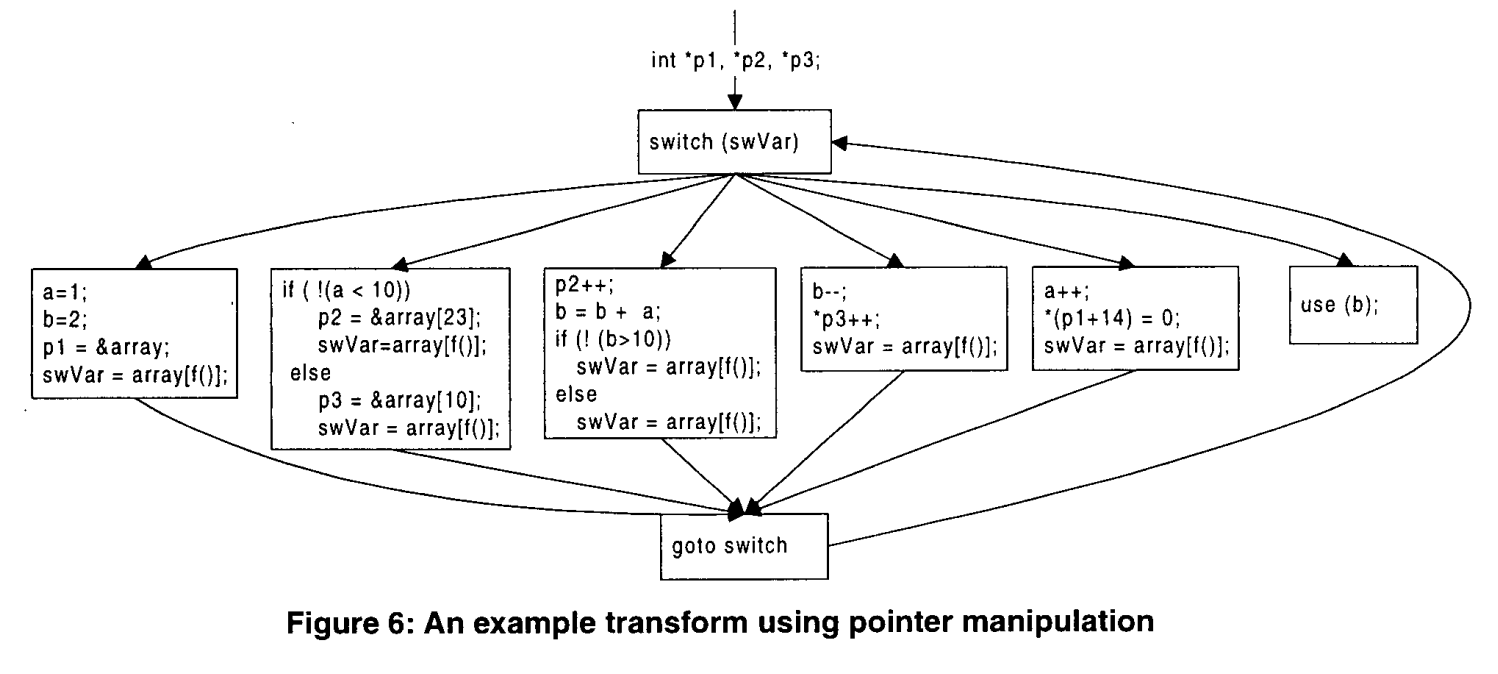
我们采用的第一组代码转换修改了高级控制传输,以阻止程序CFG的静态检测。我们分两步执行此转换。在第一步中,高级控制结构被转换为等效的if-then-goto构造。这种转换如图2所示,其中图2(a)中的示例程序被转换为图2(b)中的结构。
其次,我们修改goto语句,以便动态确定goto目标地址。在C中,我们通过将goto语句替换为switch语句的条目来实现这一点,并且动态计算switch变量以确定下一个要执行的块。转换后的代码(基于图2(a)的代码段)如图3所示。
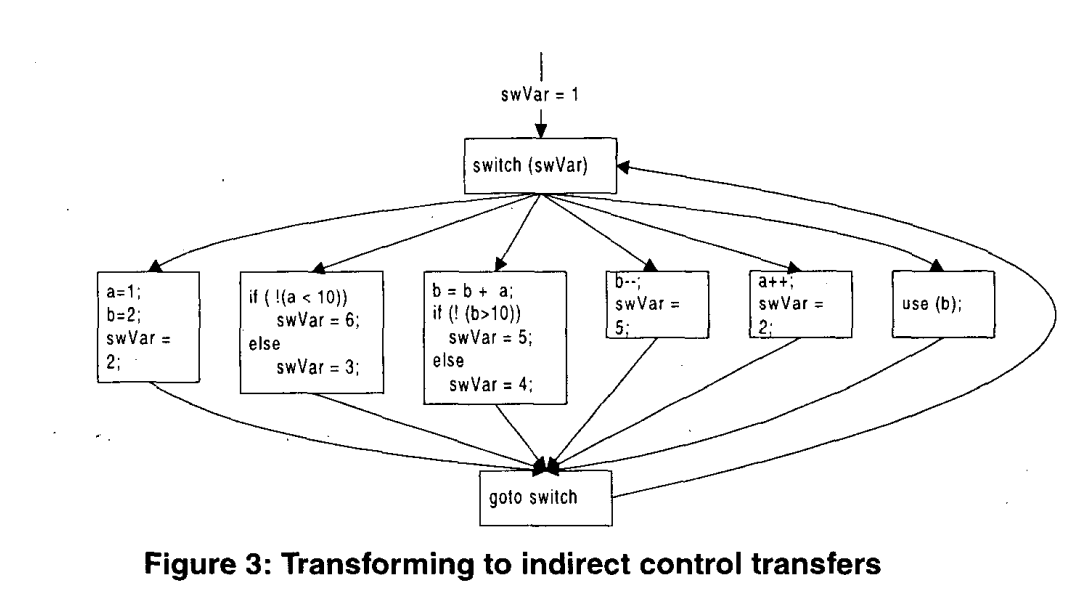
通过上述转换,直接分支被数据相关指令所取代。因此,可以从静态分支目标获得的CFG退化为图3所示的扁平形式。可以证明,这种退化形式等价于流不敏感分析所感知的控制流。不知道分支目标和代码块的执行顺序,每个块都可能是其他块的直接前导和后续。
在没有分支目标信息的情况下,构建静态CFG的复杂性取决于在每个分支点辨别开关变量的最新定义的难易程度。这正是一个经典的use-n-def数据流问题。请注意,我们已经将控制流分析转化为数据流问题。
数据流分析的复杂性受到各种程序特性的影响,如混叠。在下一节中,我们将展示如何操纵数据流特征会给数据流分析带来额外的复杂性,并最终使静态分析成为一个极其困难的问题,如果不是完全不可行的话。
5. Data-flow transformations
在第4节描述的转换之后,构建CFG的复杂性现在取决于确定分支目标的复杂性,这本质上是一个无用的数据流问题。许多经典的数据流问题被证明是NP完全的。数据流分析必须处理的一个基本困难是程序中别名的存在。别名检测对于许多数据流问题至关重要。例如,为了确定实时定义问题,数据流算法必须了解变量之间的别名关系,因为在对任何别名执行分配时都可以修改数据量。
我们的第二组转换侧重于在程序中引入非平凡别名,以影响分支目标的计算和分析。这些转换包括以下技术:
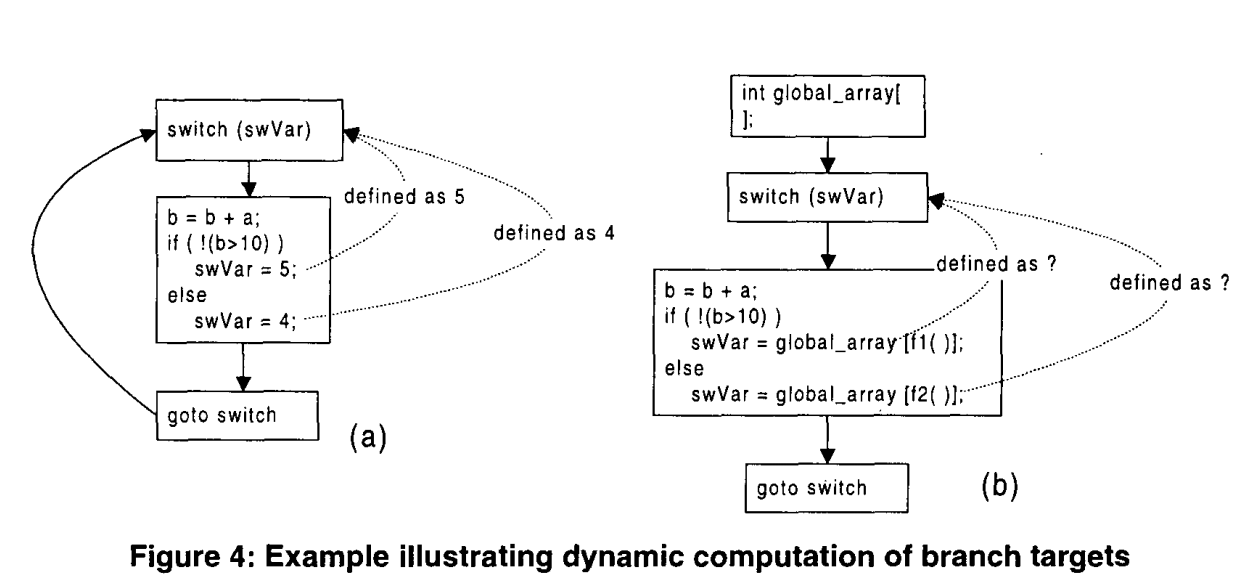
- 分支目标的索引计算:考虑图4(a)中的代码段。分析开关变量swVar(包含分支目标信息)的定义位置的use-n-def分析很简单(虚线表示use-def信息链)。现在考虑图4(b)中的代码段,其中引入了一个全局数组“全局数组”,swVar的值通过数组中的的元素计算得到(f1()和f2()表示下标计算的复杂表达式)。将图4(a)中的常量赋值替换为数组的间接访问意味着静态分析器必须推断出数组值,然后才能确定swVar的值。
- 通过指针操作实现别名:我们在以下步骤中引入别名:
- 在每个函数中,我们引入任意数量的指针变量。我们插入人工基本块或现有块中的代码,将指针分配给现有数据变量,包括全局数组的元素。
- 我们通过这些指针用间接方式替换对变量和数组元素的引用。以前对数据量的有意义计算通过其别名被语义上等效的计算所取代(对global_array元素的赋值可能表现为对指针变量的赋值)
- 指针的使用及其定义尽可能地放在不同的块中。这是为了给使用分析带来困难
一些基本块将执行,而另一些则只是死代码。由于静态分析器不知道实际执行的是哪些块,并且由于指针的定义及其用途被放置在不同的块中,因此分析器将无法推断出每次使用指针时哪个定义是有效的——所有指针分配都将显示为有效的。
例如,对图5(a)中的代码段执行的静态分析可以快速确定在执行过程中只有指针变量p的第二个定义会带到点a。然而,如果将图5(a)中的基本块分解为两个块并且块间跳转使用控制流扁平化技术进行混淆,即图5(b)。静态分析器认为别名关系<*p,a>和<*p、b>同时存在,因为它不知道哪个块首先执行。
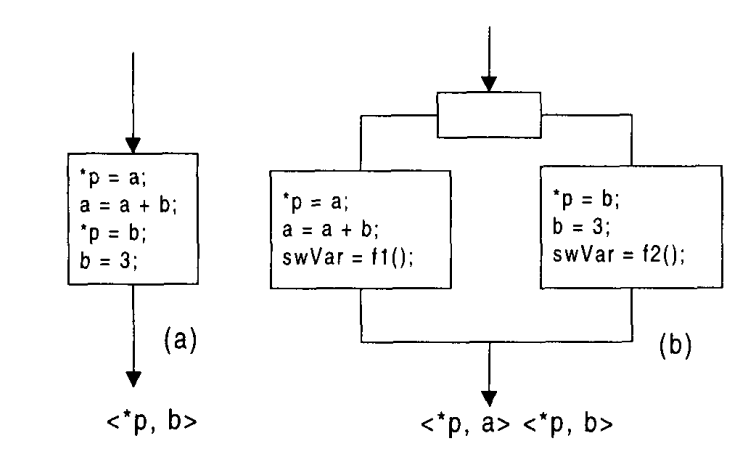
图6展示了应用于图2(a)中程序的示例转换。转换的结果如下:静态分析器将报告不精确的别名关系,这表明全局数组已被更改,其内容不会保持静态。通过引入足够的别名,分析将把数组元素解析为一组可能的值。这反过来意味着,在每次使用时,控制程序退化形式的执行流的开关变量可以取一组很大的值。
可以说,如果对手可以捕获swVar的初始值,那么他就可以找到要执行的第一个块,并从那里识别出每个后续块。
虽然这可能允许对手恢复一些原始控制流,但重要的是要注意,这种分析需要对每个前一个块进行解释,以恢复当前的基本块,这一努力超过了大多数静态分析的成本。
也可以说,每个块只需要模拟一次,因此,分析这样的程序的复杂性介于静态分析和完整执行跟踪之间,分析时间与程序中的块数成正比。击败这种分析的一种方法是展开循环,并引入语义上等效的基本块,这些块将在执行过程中随机选择。因此,恢复程序控制流所需的努力将与完整的模拟相当。此外,swVar的初始计算可以在使用后从内存中删除,以避免不必要的信息暴露。
6. Complexity evaluation
到目前为止,我们推测识别间接分支目标地址的难度受到程序中别名的影响。在本节中,我们通过提供一个证明来支持这一说法,在这个证明中,我们证明了在存在通用指针的情况下,静态确定精确的间接分支地址是一个NP难题。
6.1. A NP-hard argument
定理1:在存在一般指针的情况下,确定精确的间接分支目标地址的问题是NP难的。
证明:我们的证明包括从3-SAT问题到确定精确间接分支目标的多项式时间缩减。这是Myers最初提出的证明的变体,他在证明中证明了在存在别名的情况下,各种数据流问题都是NP难的。Landi后来提出了一个类似的证明,证明在存在通用指针的情况下,别名检测是NP难的。详细的缩减可以在其他扩展文件中找到。
NP难证明证明了在存在通用指针的情况下,静态确定分支目标地址的问题是NP难的。这个结果适用于通用程序集(带有通用指针),在第一次反应时,它可能与我们的转换生成的程序集不同。我们必须进一步确定,转换后的程序集并不代表一类受限制的程序,证明也适用。我们对此的处理方式如下。
假设一般程序集是A,我们的变换产生的程序集是A',为了证明A'不是A的受限子集(相对于NP难证明),只需证明:
1)A中的每个实例A都有多项式时间映射到A'中功能等效的实例即可。
2)如果存在多项式时间算法来求解A'中任何实例的间接分支目标,则该算法可用于求解A实例的间接分支目标。
从A的实例到A'的实例建立多项式时间映射很简单;这个映射完全由我们在第4节和第5节中描述的代码转换组成。
由于第4节和第5节中介绍的转换是语义保持的转换,因此解析A'中实例的间接分支目标的算法根据定义将解析A中功能等效实例的间接分枝目标。更直观地说,如果A'中一个实例的所有间接分支目标都解析为直接跳转,则恢复原始控制构造(从平坦的if-else-goto构造)并因此推断出A中原始程序的分支目标是多项式时间任务。
除了多层指针引用和条件分支外,3-SAT 的还原并不利用任何程序特性。第 4 节和第 5 节中描述的转换保留了条件分支以及任意层次的指针和指针引用。从直观的角度来看,这表明 3-SAT 的还原也适用于转换后的程序。
6.2. 近似分析方法的复杂性评估
虽然NP难结果对基于别名的代码转换来说是个好兆头,但我们仍然需要根据可能的启发式和近似方法来评估我们的方法。在本节中,我们将探讨两种分析方法的效果:暴力搜索和别名近似。
暴力搜索法。为了确定以程序退化形式出现的代码块的执行顺序,对手可能会采用暴力搜索方法,在该方法中探索代码块顺序的所有组合。这是一种朴素的穷举搜索启发式方法,其中每个块都被认为是当前块的直接继承者(包括当前块本身)。这种暴力方法的时间复杂度为O(n^k),其中n是不同程序块的数量,k是将要执行的块的数量。显然,这代表了最坏情况下的时间复杂度,当n和k的值足够大时,效率极低。
别名检测近似方法。在存在通用指针和递归数据结构的情况下,精确别名检测的问题是不可判定的。然而,在实践中,通常使用近似算法。别名分析算法可以在程序内以及跨程序边界分析别名。
过程内别名分析需要将过程入口节点处的别名集、从当前过程中调用的任何过程传播回来的别名集以及每个指针分配语句的别名处理函数(传递函数)作为输入。存在用于处理过程内别名分析的众所周知的数据流框架。它们分为流量敏感和流量不敏感方法。流敏感方法利用控制流路信息,比流不敏感方法更精确。第4节和第5节中描述的转换产生了静态控制流的退化形式。因此,对这种形式的控制流进行的流量敏感分析失去了其相对于流量不敏感方法的精度优势。
图7展示了这样一个示例。

图7中的CFG显示,赋值q=&c覆盖了别名关系<*q,b>,p=&d覆盖了<*p,a>。对图7(A)中的控制流进行的流敏感别名分析算法将导致该段的别名集(<*A,c>,<*p、D>,<*q,c>)。图7(b)中的退化控制流基本上表示了具有这些块的所有可能路径的集合。即使是流敏感分析算法,充其量也必须以别名集<*a,c>,<*p,a><*p、d>,<*q,c>、<*q,b>结束。Horwitz给出了精确流不敏感别名分析的定义。根据该定义,图7(b)中CFG获得的流敏感分析结果与图7(a)中CFC得出的精确流不敏感性算法的结果完全相同。因此,我们推测,对于控制流的简并形式,流敏感分析不能比其流不敏感对应分析更精确。
本文中提出的转换是程序内转换,因为它们不会影响程序级别的控制流分析。然而,程序间别名分析本质上是基于程序内别名分析的结果,因此其精度也会受到影响。超越当前方案的一步是推广变换以产生退化PCG,这将进一步降低分析结果。关于这一主题的详细讨论以及对现有别名分析框架复杂性的深入研究可以在[21]中找到。
7. Implementation and Performance Results
我们在SUIF编程环境中的ANSI C源代码转换器中实现了这些转换。在我们的实现中,我们为代码转换开发了编译器传递。每次遍历SUIF表示并执行所需的修改。确切的转换由随机种子决定:也就是说,每次编译产生的程序都是不同的。例如,全局数组的布局、转换的控制传输的确切百分比以及添加的死块数量都是由种子生成的随机数决定的。
我们在SPEC95基准程序上测试了通过实验转换获得的性能结果。这里的问题有三个衡量标准:运行转换程序的性能、静态分析的性能和静态分析的精度。
通过转换程序的运行时性能,我们指的是转换后的执行时间和可执行对象大小。这些措施反映了变换的成本。静态分析的性能是指分析工具达到关闭和终止所需的时间。一个相关但同样重要的标准是静态分析的精度,它表明分析结果与真实别名关系相比有多准确。
7.1. Performance of the transformed program
以下数据是通过将我们的转换应用于SPEC95基准程序而获得的。本实验使用了三个SPEC程序,Compress95、Go和LI。
Go是中国棋类游戏围棋的一个分支密集实现。Compress95实现了一个紧密循环的压缩算法,LI是LISP解释器的典型输入输出约束程序。这些程序是编译器社区使用的标准基准测试。
它们体现了在通用编程中广泛使用的三大类高级语言结构。然而,在该解决方案所针对的网络程序类别上测试我们的结果会更令人满意。但如果没有这一点,我们相信这些测试程序是现实世界程序的良好代表。
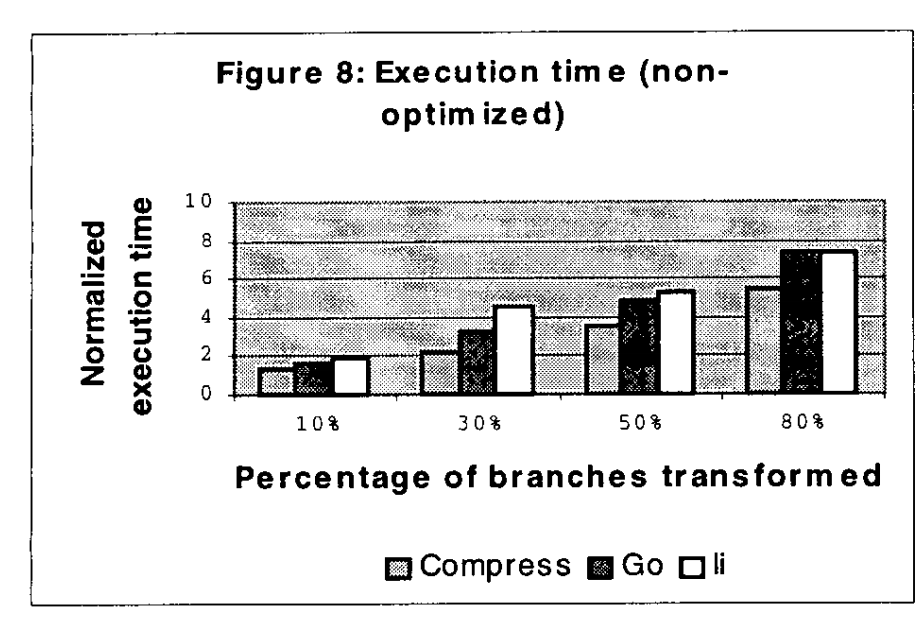
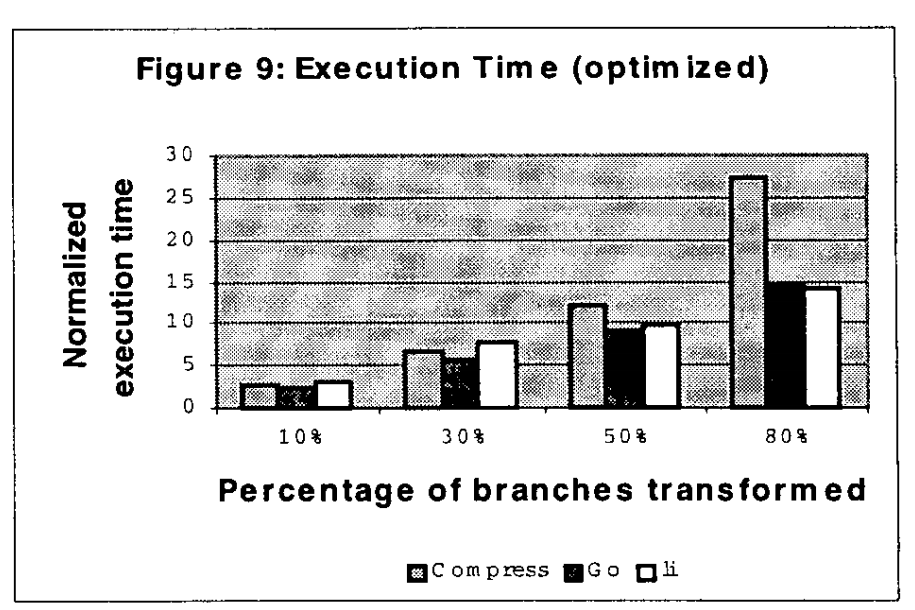
我们对程序的优化版本(使用gcc -O选项)和非优化版本进行了实验。实验在SPARC服务器上执行。实验结果表明,在这两种情况下,性能放缓都随着程序中转换分支的百分比呈指数级增长。平均而言,当程序中更实质性的部分被混淆时,由于优化而导致的性能加速会显著降低。
这是一个令人鼓舞的结果;这高度暗示(尽管不是决定性的)我们的转换极大地阻碍了编译器能够执行的优化。
Go和li在优化和非优化代码方面的性能相似。在三个原始程序中,编译器优化在Compress上表现最佳,由于优化,执行时间减少了80%。然而,如图9所示,我们的转换消除了Compress的显著优化潜力;转换和优化后的Compress的执行速度与原始优化程序的性能差异最大。由于Compress是一个循环密集型程序,因此在执行转换后,某些能够实现显著循环或循环内核优化的分析不再可能。
三个基准测试的对象大小随着分支替换的增加而增长(见图10和图11)。Go是一个分支密集型程序,通过我们的转换显示了最大的代码增长。对于直接分支的80%替换,Go和Li的可执行文件大小增加了3倍,Compress的可执行程序大小增加了大约10%。压缩包含的静态分支相对较少,这导致转换时代码增长的可能性较小。
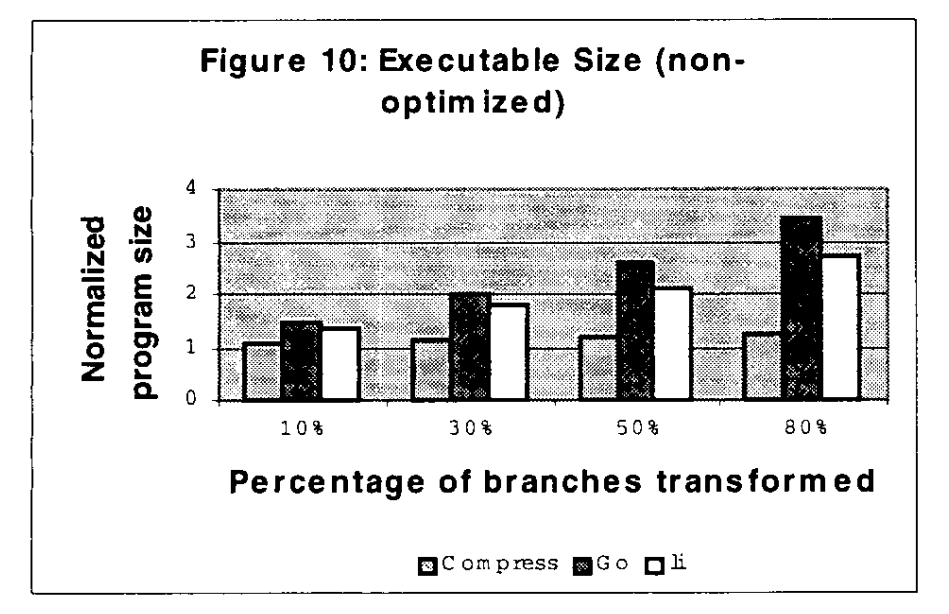
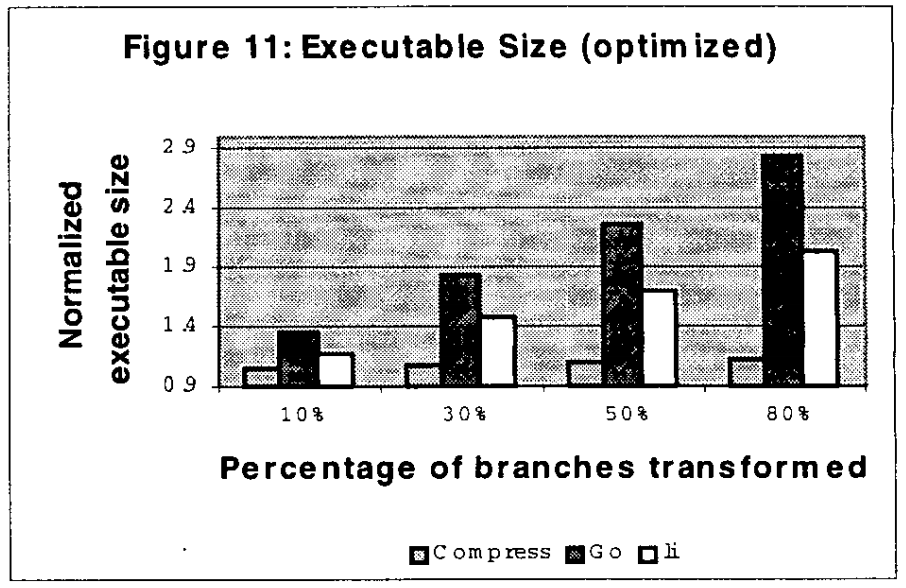
我们认为,这些结果代表了许多项目。平均而言,替换50%的分支将导致程序的执行速度提高4倍。与此同时,该项目的规模将几乎翻一番。
在这些实验中,我们使用随机算法来选择要变换的分支。一个明显的未来改进是使用智能来执行以下操作:a)识别程序中需要更多保护以防止静态分析的区域,b)有选择地对执行频率较低的分支执行转换,以获得更好的性能损失。需要考虑这两个标准之间的权衡,以获得最有效的解决方案。
7.2. Performance and precision of static analysis
在这个实验中,我们针对现有的分析工具和算法测试了我们的技术。最先进的分析工具包括NPIC工具和PAF工具包。它们都实现了一种跨过程、流敏感的算法。NPIC和PAF仅执行一次控制流分析,无需进一步细化流程图。
在我们的实验中,PAF成功分析了小样本程序(运行到完成),但未能处理SPEC基准测试中包含的一些大型程序。对于分析失败是由于别名分析中出现的困难还是无法处理原始输入程序的大小,失败特征尚无定论。我们使用PAF成功完成的测试用例包括一系列包含大量循环构造和分支语句的示例程序。在这些测试用例中,PAF终止了报告程序中尽可能多的别名;换句话说,它报告说,任何指针变量都可能被别名化为赋值语句左侧出现的每个变量。由于测试程序的大小,我们观察到转换前后分析时间的差异可以忽略不计。尽管测试用例有限,但PAF工具的经验表明,PAF未能解决扁平化基本块上的别名问题,我们使数据流和控制流相互依赖的技术带来了一个根本性的困难,即现有的分析算法缺乏处理的复杂性。
NPIC实现了一种稍微更激进的算法,其中包括函数指针分析等功能。它执行迭代分析,将程序间和程序内分析交织在一起。每次程序内阶段生成新的混叠信息时,它都会传播到其后续函数,然后这些函数会重复其程序内分析,以此类推,直到混叠集收敛。不幸的是,IBM不再维护和分发该工具。因此,NPIC的经验仅限于NPIC算法的分析实验。
NPIC算法的有限数量的实验是在小程序上进行的。在半自动分析允许的范围内,这些实验表明,当分析终止时,几乎没有达到准确度。
在使用索引计算和混叠来计算分支目标的特定情况下,NPIC开始指出全局数组的元素可能包含许多可能的值。随着迭代的进行,这些信息从未被完善过。相反,在后续迭代中确定的别名关系增加了数组元素被认为具有的可能值集。该算法最终终止,并声称全局数组的元素被更改了任意次数,并且它们可以包含任意值。涉及数组元素的计算被认为是不可分析的。这反过来意味着间接分支目标无法精确确定。因此,这些块之间的别名信息传播并没有变得更容易,别名关系也从未得到细化。
8. Conclusion
保护可信软件免受不可信主机的攻击,对于现代网络中的许多关键功能来说都很重要。例如,考虑分布式入侵检测系统,其中部分ID程序需要在不可信任的主机上运行。如果这些程序成为恶意攻击的目标并遭到破坏,将产生严重后果。
在本文中,我们考虑了一类重要的攻击,即基于程序二进制形式的静态分析的攻击。我们提出了一种通过紧密耦合程序的控制流和数据流来击败分析的策略。由于可接受精度的数据流分析取决于控制流信息,因此这种方法能够大大延长分析时间,并将分析精度降低到无用的水平。我们建立的理论界限表明,对以这种方式转换的程序的分析是NP难的
我们以ANSI C编译器的形式开发了一个转换的实际实例化。编译器对程序源代码进行了许多更改,包括:程序控制流的退化;系统和普遍地创建别名;以及引入数据相关分支。我们注意到,这些转换不依赖于类C指针范式,它们可以应用于存在显式内存引用的任何中间表示。
在我们对示例程序进行的概念验证实验中,转换后的版本击败了目前可用的静态分析工具。尽管这些实验不是也永远不可能成为确凿的证据,但我们认为这些结果是有希望的迹象,表明我们有一种实用的方法来击败静态分析。
我们注意到,所描述的转换生成的程序具有相当大的代码多样性(转换是在每次编译的基础上随机选择的)。当部署在网络中的不同点时,此类程序对类攻击具有很高的弹性,因为大多数类攻击都利用了常见的软件缺陷。
值得注意的是,这项工作的目的是消除静态分析可用于推断软件篡改或模拟有用信息的可能性。换句话说,最佳结果是,除了实际执行之外,不应该有有效的方法来分析程序。我们还注意到,许多形式的动态程序分析都利用了静态信息,本文中描述的技术将有助于防御这些形式的分析。
References
Aigner, G. et al. "The SUIF2 Compiler Infrastructure", Documentation of the Computer Systems Laboratory, Stanford University.
Aucsmith, D., "Tamper Resistant Software", Proceeding of the 1st Information Hiding Workshop, Cambridge, England, 1996.
Ball, T. and J. R. Larus. "Optimally Profiling and Tracing Programs", ACM Transactions on Programming Languages and Systems, Vol 16, No. 4, July 1994, pp. 1319-1360.
Collberg, C., C. Thomborson, and D. Low, "Breaking Abstractions and Unstructuring Data Structures", IEEE International Conference on Computer Languages, Chicago, May 1998.
Collberg, C., C. Thomborson, and D. Low, "A Taxonomy of Obfuscating Transformations", Techreport 148, Department of Computer Science, University of Auckland, July 1997.
Forrest, S. and A. Soma, "Building Diverse Computer Systems", in the 1996 Proceedings of the Hot Topics of Operating Systems.
Hohl, F., "Time Limited Blackbox Security: Protecting Mobile Agents from Malicious Hosts", in Lecture Notes in Computer Science, vol. 1419, Mobile Agents and Security. Edited by G. Vigna. Springer-Verlag, 1998.
Hitunen, M. and R. D. Schlichting, "Adaptive Distributed and Fault-Tolerant Systems", International Journal of Computer Systems Science and Engineering, Vol. 11, No. 5, pp. 125-133, September 1996.
Knight, J., K. Sullivan, M. Elder, and C. Wang, "Survivability Architectures: Issues and Approaches", in Proceedings: DARPA Information Survivability Conference and Exposition, IEEE Computer Society Press. pp. 157-171.
Larus, J., "Efficient Program Tracing", Computer, Vol. 26, No. 5, May 1993, pp. 52-61.
Muchnick, S., Advanced Compiler Design Implementation, Morgan Kaufmann, 1997.
Myers, E., "A Precise Inter-procedural Data Flow Algorithm", in the Conference Record of the Eighth POPL, Williamsburg, VA, January, 1981, pp. 219-230.
Hind, M., M. Burke, P. Carini and J. Choi, "Inter-procedural Pointer Analysis", ACM Transactions on Programming Languages and Systems, Vol. 21, No. 4, July 1999, pp. 848-894.
Horwitz, S., "Precise Flow-insensitive May-alias Analysis is NP-Hard", ACM Transactions on Programming Languages and Systems, Vol. 19, No. 1, pp. 1-6.
Landi, W., "Interprocedural Aliasing in the Presence of Pointers", Ph.D. Dissertation, Rutgers University, 1992.
Landi, W., "Undecidability of Static Analysis", ACM Letters on Programming Languages and Systems, Vol. 1, No. 4, December 1992, pp. 323-337.
Landi, W. and B. Ryders, "A Safe Approximation Algorithm for Interprocedural Pointer Analysis", Techreport, Rutgers University, 1991.
The Prolangs Analysis Framework (PAF). Rutgers University. http://www.prolangs.rutgers.edu/public
Rosen, B., "Data Flow Analysis for Procedural Languages", Journal of the ACM, Vol. 26, No. 2, pp. 322-344.
Sander, T., and C. Tschudin, "Protecting Mobile Agents Against Malicious Hosts", in the Proceedings of the 1998 IEEE Symposium of Research in Security and Privacy, Oakland, 1998.
Wang, C., "A Security Architecture for Survivability Mechanisms", Ph.D. Dissertation, October 2000, University of Virginia.
Wang, C., Hill. J., Knight J., Davidson, J. "Software Protection in Malicious Environments", CS Technical Report. CS-00-12, Department of Computer Science, University of Virginia.