Improving Automatic C-to-Rust Translation with Static Analysis
Improving Automatic C-to-Rust Translation with Static Analysis
论文来自 2023 IEEE International Conference on Software Engineering (ICSE 23) 的《Improving Automatic C-to-Rust Translation with Static Analysis》。
摘要
尽管 C 语言在系统编程领域广受欢迎,但也因其贫乏的语言级安全机制而“臭名昭著”,由此导致了严重的缺陷与漏洞。即便通过了类型检查,C 程序仍可能存在内存与线程方面的错误。为了解决这一由来已久的问题,近年来出现了 Rust,它配备了丰富的安全机制,尤以其“所有权”类型系统著称。Rust 通过类型检查来防止内存与线程错误。将遗留的 C 程序用 Rust 重写,开发者便能发现此前未知的缺陷,并避免引入新的错误。
然而,Rust 在遗留程序中的落地仍受限于手工 C→Rust 翻译的高成本。Rust 的安全特性在语义上与 C 的不安全特性存在差异,这要求程序员精确理解其程序行为,方能正确重写。现有的 C→Rust 翻译器并未缓解这一负担,因为它们通常只是将 C 的特性做语法层面的映射,转成 Rust 中仍然“不安全”的写法,从而把进一步的重构工作留给了程序员。
本文提出改进当前 C→Rust 翻译水平的问题设定:通过自动将不安全特性替换为安全特性,提高翻译结果的安全性与可用性。具体而言,我们识别出两类需要替换的重要不安全特性:锁 API 与 输出参数。我们给出了关于锁 API 的实验结果,并讨论了对输出参数的后续计划。
1. 引言
C 是一种被广泛使用的系统编程语言,但其贫乏的语言级安全机制导致了软件系统中严重的缺陷与漏洞。过去十年里,开源社区已披露的漏洞中大约有一半出现在 C 程序中 [29]。尽管 C 是静态类型语言,其薄弱的类型系统并不能消除大多数内存与线程错误。即便某个程序通过了类型检查,也无法保证其在内存与并发方面是安全的。这迫使 C 程序员必须手动防止此类错误,既耗时又容易出错。
Rust [3],[28] 是一种较新的系统编程语言,旨在弥补 C 的局限。其“所有权”类型系统同时确保内存与线程安全 [23]。Rust 还提供了 C 所不具备的高层抽象,例如闭包 [24,§13.1]、泛型 [24,§10.1] 和 trait [24,§10.2]。这些特性使代码更加简洁,并减少对不安全类型转换的需求,从而降低缺陷产生的可能性。
Rust 的设计在优先保证安全性的同时仍能提供良好性能,为系统编程社区改进遗留系统软件的安全性提供了契机。将 C 程序用 Rust 重写,在 Rust 类型检查器的帮助下,人们可以发现此前未知的缺陷。以 cURL 为例,若其开发者当初用 Rust 重写,其中已知的安全漏洞有一半以上本可以被轻松发现 [22]。此外,一旦把软件迁移到 Rust,在引入新特性的同时产生新缺陷的风险也会显著降低。
鉴于 Rust 在提升软件安全性方面的益处,程序员正在用 Rust 重新实现关键的系统软件。例如,Mozilla 用 Rust 开发了 Servo 浏览器,并以 Servo 的部分模块替换了 Firefox 的相应模块。Rust 的安全机制使复杂 HTML 渲染器的正确实现成为可能 [17]。操作系统作为系统程序中最复杂的一类,也在采用 Rust。最新发布的 Linux 内核已经支持编写 Rust 代码 [10]。Android 与 Fuchsia 也在其实现中使用了 Rust [2],[35]。
然而,手工进行 C→Rust 翻译的高成本阻碍了 Rust 在系统程序中的更广泛落地。由于 C 与 Rust 之间存在差异,这一翻译过程不仅劳力密集,而且难以保证正确性。Rust 为安全性提供了新特性,这些特性在句法与语义上都与 C 的对应概念不同。举例来说,Rust 提供了 引用(reference)这一保证受控访问的“指针”形式,但其使用约束远比 C 中的普通指针严格。这些差异要求程序员精确理解自己程序的行为以及 Rust 的相关特性。
这就产生了对自动化 C→Rust 翻译的需求,但目前在该方向上的工作仍然有限。最广泛使用的自动 C→Rust 翻译器 C2Rust [40] 基本只做句法层面的翻译。它利用了 Rust 在提供安全保障特性的同时也保留了与 C 对应的不安全特性这一事实。比如,Rust 也有原始指针(raw pointer),其访问可能并不安全,与 C 的指针类似。C2Rust 生成的程序继续使用这些不安全特性,因此无法依靠类型检查来确保安全。通常期望程序员在 C2Rust 翻译之后,再手工把这些不安全特性替换为安全特性。Emre 等人 [12] 提出过一种方法,将 C2Rust 生成程序中的原始指针替换为引用,但其他不安全特性依然存在。
本文旨在改进当前最先进的自动 C→Rust 翻译:用安全特性替换 C2Rust 生成程序中的不安全特性。由于安全特性在语义上与不安全特性不同,我们需要静态分析来推断目标程序中不安全特性的行为并进行替换。每类不安全特性都有其独特性,因而需要专门设计相应的静态分析。本工作识别出两类需要优先替换的重要不安全特性:锁 API 与 输出参数(§III)。我们展示了将 C 的锁 API 替换为 Rust 锁 API 的结果(§IV),并讨论对输出参数以及其他重要不安全特性的计划(§V)。
2. 背景与相关工作
C2Rust [40] 是目前最广泛使用的 C→Rust 翻译器。其翻译属于“句法层面”的:针对 C 代码中使用到的每一种特性,找到 Rust 中一个可能不安全但在语法上可对齐的等价特性,以此化解 C 与 Rust 之间的句法差异。
C2Rust 在翻译过程中会保留所有 C 的类型以及对 C 标准库函数的调用。下面给出一段 C 代码及其由 C2Rust 生成的 Rust 版本:
// C
void f(int x) { if (x == 1) printf("Hello, world!"); }// C2Rust 生成的 Rust
fn f(mut x: libc::c_int) {
if x == 1 as libc::c_int {
printf(b"Hello, world!\0" as *const u8 as *const libc::c_char);
}
}虽然函数定义与条件语句被做了句法层面的翻译,但类型 与函数 仍被保留下来。Rust 程序员更倾向于如下写法:
fn f(x: i32) { if x == 1 { print!("Hello, world!"); } }这里使用了 Rust 的原生整数类型 (其位宽可能随硬件而变)以及由标准库提供的 宏。
C2Rust 也会把 C 的指针保留下来——在 Rust 中翻译为原始指针(raw pointer)。原始指针与 C 指针等价,无法保证安全访问。以下是使用指针的 C 代码及其由 C2Rust 生成的 Rust 版本:
// C
void f(int *p) { *p = 1; }// C2Rust 生成的 Rust(原始指针 *mut)
fn f(mut p: *mut libc::c_int) {
unsafe { *p = 1 as libc::c_int; }
}其中 表示原始指针。为确保内存安全,Rust 提供了原始指针的安全替代物:引用(reference)。引用约束更严格,但在被借用规则允许的前提下始终可安全访问。程序员更偏好使用引用,如下:
fn f(p: &mut i32) { *p = 1; }其中 &mut 表示可变引用。
CRustS [26] 通过“句法重写”增强 C2Rust 的输出。它基于 TXL 变换语言 [9] 编写的 220 条句法替换规则进行处理,例如可把 替换为 。
Emre 等人 [12] 提出,用引用替换 C2Rust 生成代码中的原始指针。但“盲目地把所有原始指针都替换为引用”并不可行,原因有二:其一,受引用语义的约束,并非所有原始指针都能替换;其二,当编译器无法自行推断时,引用需要显式的生命周期(即有效范围)注解。为解决这些问题,他们采用“借助编译器反馈的迭代改写”:先将所有原始指针替换为引用,然后根据编译器的报错信息继续修改代码(把部分引用改回原始指针,或补充生命周期注解),如此往复,直到代码能够成功通过编译为止。
近来,也出现了可进行代码翻译的语言模型 [5],[6],[13],[19],[25],[31],[32],[36],[38],[39]。虽然它们可以把 C 代码翻译成 Rust,但其翻译无法保证语义保持。
除 C→Rust 之外,学界还提出了许多更“安全”的 C 替代语言及(半)自动翻译到这些语言的方法 [7],[8],[11],[14]–[16],[18],[27],[30],[33]。然而,与 Rust 不同,它们通常只保证有限形式的内存安全。例如,Cyclone [18] 防止悬垂指针解引用;Checked C [11] 保证不存在空指针解引用与越界访问。
3. 提出的问题(Proposed Problem)
我们旨在改进当前最先进的自动 C→Rust 翻译:把 C2Rust 生成程序中的不安全特性替换为安全特性。本文重点讨论两类重要的不安全特性:锁 API 与 输出参数。
A. 锁 API(Lock API)
锁被广泛用于防止数据竞争(data race):当多个线程同时对同一内存地址进行读写时,就可能发生数据竞争。为避免数据竞争,每个线程在访问共享数据之前和之后,分别获取与释放一个锁。不幸的是,如果线程获取了错误的锁、获取得太晚,或过早释放,即便使用了锁,数据竞争仍可能发生。
C 语言中最常用的锁 API 是 pthreads [4],它提供了 与 两个函数,分别用于获取与释放作为参数传入的互斥量。线程需要在访问共享数据的前后调用这两个函数,如下例所示:
int n = ...;
pthread_mutex_t m = ...;
void inc() {
pthread_mutex_lock(&m);
n += 1;
pthread_mutex_unlock(&m);
}其中 是共享整数, 是保护 的锁。每次访问 时,线程都应当持有 。
当使用 pthreads 时,正确使用锁的责任在程序员,因为该 API 并不会校验程序中锁使用的正确性。程序员在使用锁时容易犯两类错误:
- 数据—锁不匹配(data-lock mismatch):访问某块数据时获取了错误的锁;
- 流程—锁不匹配(flow-lock mismatch):在错误的程序时机获取(或释放)了锁。
下面是一个数据—锁不匹配的例子:
pthread_mutex_lock(&m2);
n1 += 1;
pthread_mutex_unlock(&m2);而程序的其他部分在访问 时获取的是 。上面这段代码错误地获取了 (本应获取 )。
下面是一个流程—锁不匹配的例子:
void f1() { n += 1; pthread_mutex_lock(&m); ... }
void f2() { ... pthread_mutex_unlock(&m); n += 1; }此处程序使用 来保护 。函数 在获取 之前就访问了 ,而 在释放 之后又访问了 ,二者都不正确。
与此形成对比的是,Rust 的锁 API 能确保每一次加锁的使用都是正确的 [23]。为防止数据—锁与流程—锁的不匹配,Rust 的锁 API 将
- 数据—锁关系(哪把锁保护哪块数据),以及
- 流程—锁关系(在程序的哪个点位持有哪些锁)
都显式化到程序中。
首先,它把锁与共享数据绑定,从而显式暴露数据—锁关系。可以把“Rust 的每个锁”理解为“C 中的一把锁 + 与之绑定的共享数据”。下面这段代码创建了一个初始值为 的锁,并命名为 :
use std::sync::Mutex;
static m: Mutex<i32> = Mutex::new(0);要访问共享数据,线程必须获取与该数据绑定的锁,从而消除了“数据—锁不匹配”的可能性。其次,Rust 引入了 guard(保护者)的概念来显式表达流程—锁关系。对锁调用 方法会返回一个 guard,它是指向受保护数据的特殊指针。线程只能通过对 guard 解引用来访问数据;当 guard 被 (释放)时,与之关联的锁会自动释放。下面展示了 guard 的创建、使用与释放:
let mut g = m.lock().unwrap();
*g += 1;
drop(g);由于 Rust 的所有权类型系统,一个函数只能在变量初始化之后且移交到其他函数之前使用该变量。因此,线程只有在持有锁时才能使用相应的 guard,从而不会发生流程—锁不匹配。
C2Rust 生成代码中保留的 C 锁 API 是我们要替换的一项重要不安全特性。由于 C2Rust 保留了所有 C 的类型与库调用,C 的锁 API 也就被保留在生成程序里,这使程序无法受益于 Rust 锁 API 所保证的线程安全。核心挑战在于:如何通过静态分析高效且精确地计算出程序中的数据—锁关系与流程—锁关系。没有这两类信息就无法进行替换,因为 Rust 的锁 API 要求这些关系在代码里是显式的。
B. 输出参数(Output Parameters)
输出参数指的是用于“输出”而非“输入”的参数。不同于某些把输出参数作为原生语言特性的语言,C 通过指针来模拟输出参数。要使用输出参数,函数接收一个指针,并只写入该地址(不读取)。在 C 中使用输出参数主要有两个原因。
其一:返回多个值。
在支持元组的语言里,函数可以返回一个元组来携带多个返回值。由于 C 没有元组,函数只能把其中一个值作为返回值,其余值通过输出参数返回。下面的函数示例就通过一个输出参数,同时返回了整数除法的商与余数:
int div(int n, int d, int *r) {
int q = n / d;
*r = n - q * d;
return q;
}其二:实现“半谓词”(semipredicate)。
“半谓词”是可能失败的函数;例如,当除数为 时,除法函数会失败。在很多语言中,实现半谓词的常用方案是异常:当函数失败时抛出异常,调用者用异常处理器来识别失败。然而 C 没有异常机制,因此程序员常用输出参数来实现半谓词。典型做法是:把半谓词实现为带输出参数的函数;成功时,函数把结果写入输出参数,并返回一个表示成功的值;失败时,函数返回一个表示失败的值,且不写入输出参数。如下例所示:只有当除数非零时,该函数才返回商:
int div(int n, int d, int *q) {
if (d == 0) return -1;
*q = n / d;
return 0;
}虽然输出参数在 C 中很实用,但如果可能,应当尽量避免 [1]。原因如下:
- 可读性受损。参数本意是输入而非输出;通过输出参数返回值,比“直接返回结果”的函数更难理解。
- 安全性受损。带输出参数的函数调用端通常会先声明一个未初始化变量,再把该变量的指针传入函数。若该函数是半谓词,则在失败路径上,该变量可能保持未初始化状态;如果随后不加小心地读取它,就会导致未定义行为。
Rust 提供了安全的替代机制来消除输出参数:元组(tuple)与 Option。
当函数需要返回多个值时,可以直接返回一个元组,例如:
fn div(n: i32, d: i32) -> (i32, i32) {
let q = n / d;
let r = n - q * d;
return (q, r);
}当函数是半谓词时,可以返回一个 Option:它要么是 (表示成功,并携带一个内部值),要么是 (表示失败,不携带值)。下面给出用 实现半谓词的示例:
fn div(n: i32, d: i32) -> Option<i32> {
if d == 0 { return None; }
let q = n / d;
return Some(q);
}在 C2Rust 生成的代码中,用元组与 Option 替换输出参数非常重要。由于 C2Rust 不会增减函数形参,输出参数会在翻译后保留下来,从而损害生成的 Rust 代码的可读性与安全性。
然而,想要自动移除输出参数并不容易,难点包括:
- 识别输出参数本身并非易事;
- 对于半谓词,还需要识别返回值的语义(哪些返回值代表“成功”,哪些代表“失败”)。没有这些信息,就不可能把调用端的错误处理逻辑正确转换为 Rust 风格的返回类型。
因此,我们需要高效的静态分析来定位输出参数,并推断半谓词返回值的实际含义。
4. 已取得的成果(Achieved Results)
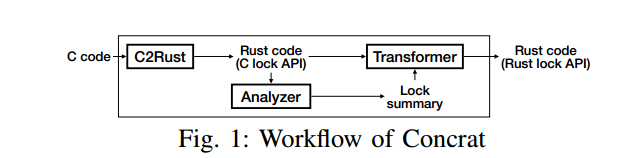
为将 C2Rust 生成代码中的 C 锁 API 替换为 Rust 锁 API,我们提出了 Concrat,它由 C2Rust、一个静态分析器以及一个 Rust 代码变换器 组成 [20]。图 1 展示了 Concrat 的工作流:静态分析器在 C2Rust 生成的代码上执行我们提出的数据流分析,产出一份锁摘要(lock summary),其中描述了数据—锁关系与流程—锁关系;随后,代码变换器依据该锁摘要,将程序中的锁 API 进行替换。
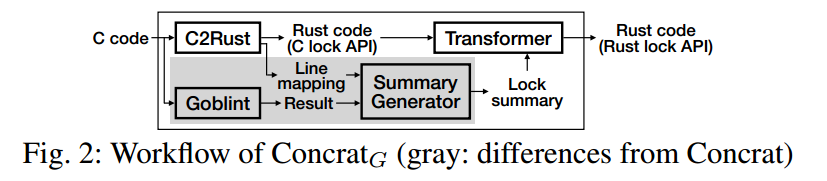
为将我们的分析器与面向并发 C 程序的最新静态分析器 Goblint [34],[37] 对比,我们额外构建了 Concrat_G,其框架与 Concrat 相同,但将我们的分析器替换为 Goblint。图 2 给出了 Concrat_G 的工作流。由于 Goblint 分析的是 C 源码,我们的摘要生成器会借助 C2Rust 产生的“C→Rust 行映射”,把 Goblint 的分析结果转换成锁摘要。
我们使用来自 GitHub 的 46 个真实并发 C 程序对 Concrat 进行了评估。实验环境为一台 Ubuntu 主机(Intel Core i7-6700K,4 核 8 线程,4GHz,32GB 内存)。我们的实现与评测数据已公开 [21]。
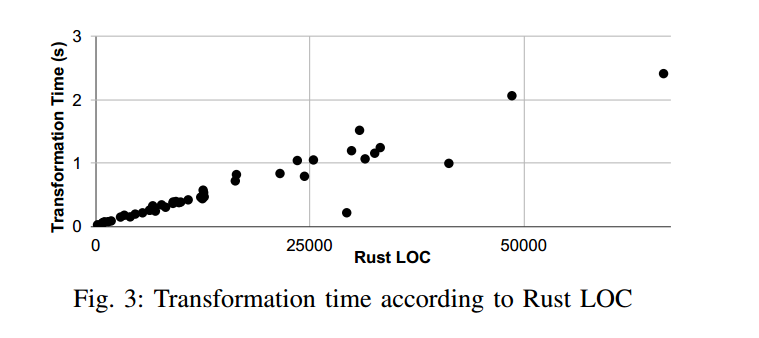
我们的评估结果表明,代码变换器具有良好的可扩展性、适用性广且正确。如图 3 所示,变换时间与代码规模近似成正比:在 66 KLOC 上仅需 2.5 s。我们把“若程序在变换后能成功编译”视为“变换器对该程序适用”。在 46 个程序中,29 个能直接编译通过,5 个在手工修改数行后可编译通过,12 个无法通过编译。12 个失败原因归纳为三类:按条件加锁的函数、函数指针以及指向锁的指针。我们把“若程序在变换后,其所有测试用例均通过”视为“变换器正确”。在 34 个可编译的程序中,20 个带有测试;在这 20 个中,1 个在 C2Rust 翻译前就失败,1 个在 C2Rust 翻译后失败,17 个在我们的变换后通过,另有 1 个在我们的变换后失败。尽管我们没有给出形式化的正确性证明,但我们的设计将一次 lock 函数调用变换为一次 lock 方法调用,并将一次 unlock 调用变换为“drop 一个 guard(其析构函数会释放相关联的锁)”,从直观上支撑了变换的正确性。
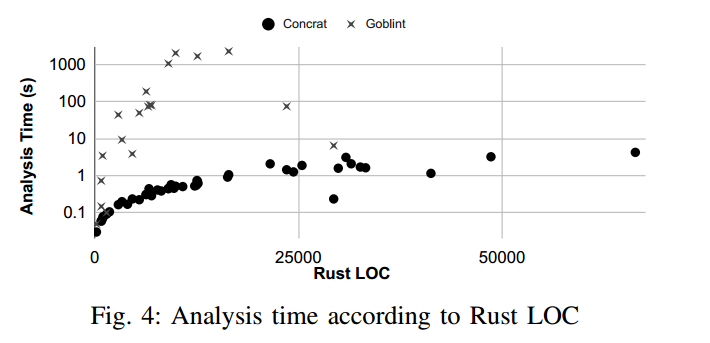
评估结果还表明,我们的分析器相比 Goblint 更具可扩展性且更精确。在 66 KLOC 上,我们的分析器仅需 4.3 s;而 Goblint 因内部错误或 24 小时的超时限制,未能分析 27 个程序,对其余 19 个程序的分析耗时比我们慢 1.1× 至 3923×(见图 4)。我们认定:若分析器给出的锁摘要能使变换器生成可编译的代码,则该分析器是精确的;因为不精确的锁摘要会导致变换后的代码无法编译。在 Goblint 能分析的 19 个程序中,使用我们的分析器时有 2 个变换后无法编译;而使用 Goblint 时有 6 个变换后无法编译。
5. 未来计划(Future Plans)
我们将提出一种方法,用 元组(tuples) 与 选项类型(options) 来替换输出参数。该方法需要静态分析:既要检测哪里使用了输出参数,也要推断半谓词(semipredicate)函数返回值所表达的语义。此外,我们还需基于静态分析结果设计一个 Rust 代码变换器。目前,我们正在收集实际使用输出参数的 C 代码,以归纳现实代码中的常见用法模式;分析器与变换器将以这些模式为依据进行开发。我们相信,可以像在“锁 API”工作中那样对本方法进行评估:对变换器评估其可扩展性、适用性与正确性,对分析器评估其可扩展性与精度。我们预计在 2023 年底完成这部分工作。
在解决输出参数问题之后,我们将识别 C2Rust 生成代码中另一类重要的不安全特性,并将其替换为合适的安全特性。尽管尚未最终确定具体目标,候选方向包括:用 Box 替换 malloc,把接受 void * 指针的函数改造为泛型函数,以及将循环改造为使用迭代器与高阶函数的形式。虽然目前尚无法给出具体的评估计划,但我们预期可以采用与之前相似的评估流程。我们预计在 2024 年底完成该项工作。