In Rust We Trust – A Transpiler from Unsafe C to Safer Rust
In Rust We Trust – A Transpiler from Unsafe C to Safer Rust
论文来自 2022 IEEE International Conference on Software Engineering (ICSE 22) 的《In Rust We Trust – A Transpiler from Unsafe C to Safer Rust》。
摘要
Rust 是一种类型安全的系统编程语言,其编译器会检查内存与并发安全。为便于从既有 C 项目平滑迁移,可使用源到源(source-to-source)转译器通过程序变换将 C 程序自动转换为 Rust。然⽽,现有的 C→Rust 变换工具(例如开源的 C2Rust 转译器[1])存在一个缺点:保留了 C 的不安全语义,仅将其改写为 Rust 的语法。Emre 等人 [2] 指出了这些问题,并利用 rustc 编译器的反馈,将某一类原始指针(raw pointers)重构为 Rust 引用,以提升 C2Rust 输出的整体安全性与“惯用性”(idiomaticness)。
我们聚焦于提升 API 安全性(即在函数签名中尽量减少 unsafe 关键字的使用),采用源到源变换技术,基于代码结构的模式匹配与变换,对 C2Rust 的输出进行自动重构;该方法不依赖 rustc 的编译器反馈。进一步地,通过放宽变换的语义保持(semantics-preserving)约束,我们提出 CRustS:一种全自动的源到源变换方法,可提高转换后代码通过 rustc 安全检查的比例。
我们的方法新增了 220 条 TXL [1] 源到源变换规则,其中 198 条严格保持语义,22 条为语义近似(semantics-approximating);由此缩小了不安全表达式的范围,并暴露出更多可进行安全 Rust 重构的机会。我们在开源与商业 C 项目上对该方法进行了评估;结果显示,变换之后的安全代码占比显著提高,其函数级别的安全代码占比可与惯用 Rust 项目的平均水平相当。
关键词
transpiler, safety, measurement, refactoring, code transformation
1. 引言
为了受益于 rustc 编译器内置的内存与并发安全保障 [4],转译得到的 Rust 程序必须避免不必要的 unsafe 关键字使用,因为它会降低对被标注的函数或代码块的安全检查力度。流行的、人工编写的 惯用(idiomatic) Rust 项目通常有大约 20%–30% 的代码被标记为 unsafe [5][2]。这些 unsafe 大多是为换取较低层级的效率或硬件相关操作而作出的权衡 [3]。
然而,当前的 C→Rust 转译工具(如 c2rust)为了生成语义等价的 Rust 代码,往往会在几乎所有的函数签名中使用 unsafe,从而产出不够惯用的 Rust 代码。这显著限制了 rustc 编译器在转译后 Rust 代码上能够执行的安全检查。此外,即便语义上等价,部分 Rust 代码也常因违背 Rust 设计而无法通过编译;例如,在运行时初始化静态变量在 C 中是合法的,但在 Rust 中不是。
虽然 c2rust 提供了命令行重构工具 [6],用户可以手动撰写命令来改进生成的 Rust 代码,但这需要大量的人工工作以及对源代码相当全面的理解。
在本文中,我们基于 c2rust 构建了一个转译系统,重点在于生成可编译的 Rust 程序,并提升通过编译器检查的安全代码比例。我们的方法旨在系统性地消除函数签名中非必需的 unsafe 关键字,并在完全自动化的方式下,细化安全函数内部 unsafe 代码块(block)的作用域。
2. 我们的方法(OUR APPROACH)
依据 The Rust Reference,unsafe 可以用于四种上下文:函数限定符(Function qualifiers)、unsafe 代码块、Trait 以及 Trait 实现(Trait Implementations)。
在纯 Rust 项目与 C→Rust 转译项目中,绝大多数涉及 unsafe 的 Rust 代码属于前两类上下文,也是本文关注的重点。我们首先处理函数限定符中的 unsafe,原因在于:
- 这是
c2rust转译代码中unsafe的主要使用方式; - 它会使函数体中的所有语句都被视为
unsafe,因此对整体安全比例的影响更大; - 它具有多米诺效应:凡是使用了
unsafe的函数,在调用处要么必须被unsafe代码块包裹,要么被声明为unsafe(例如当该函数作为参数被传递时); - 其中大多数可以通过将函数体内所有不安全语句包裹进
unsafe代码块来移除函数签名上的unsafe。
对于 unsafe 代码块 本身,我们的策略很简单:将其拆分为每条语句一个的 unsafe 块,然后删除非必需的 unsafe。对于相邻的 unsafe 块,我们再进行合并,并在考虑命名作用域的情况下,必要时把中间的一些语句也纳入其中。
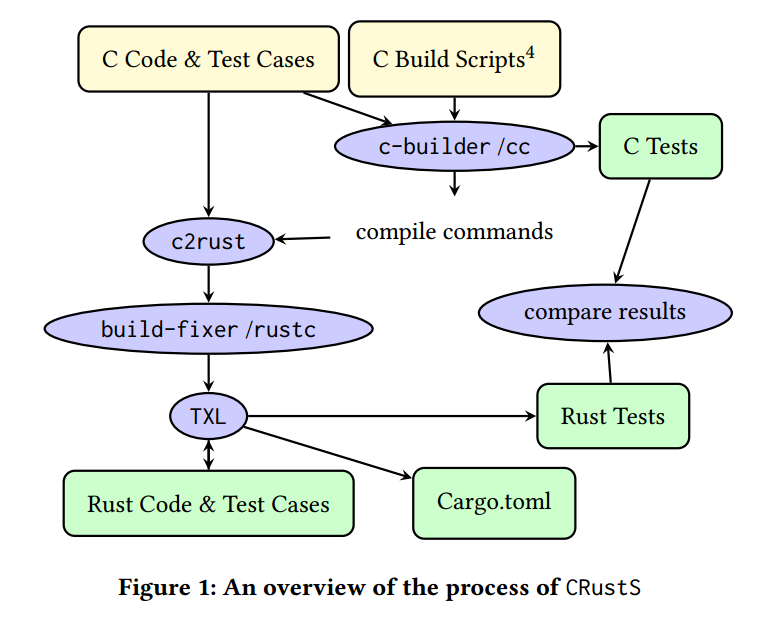
我们将不安全 C 迁移到安全 Rust 的主要处理步骤如图1 所示。该流程在 c2rust 的基础上扩展了以下组件:
c-builder:自动化构建 C 源项目(支持 Make、CMake 或 Bazel),并生成c2rust所需的中间产物(例如compile_commands.json);- 调用
c2rust:将 C 项目转译为一个 Rust 项目; build-fixer:依据rustc的报错提示修复构建错误;- TXL 规则:自动重构 Rust 代码,以减少
unsafe的使用频度与作用域。
一个 TXL 程序通常由许多独立的变换规则组成。每条规则完成一种特定的代码变换;例如,依据硬件规格,将 C 库类型 libc::c_short 转换为 Rust 原生类型 i16。
应用 TXL 变换规则的主要步骤是:
- 解析 Rust 源文件,生成语法树;
- 应用用户自定义的变换规则,重写语法树中需要修改的部分,例如:把语法范畴为
TypeNoBounds[3]、其取值为libc::c_short的每个节点替换为同一语法范畴但取值为i16的节点[4]; - 反向生成(unparse)并美化输出该语法树,得到更新后的 Rust 源代码文件。
注:
TypeNoBounds、libc::c_short、i16、c2rust、rustc等均保留为代码标识符形式,以避免歧义。
3. 评估(EVALUATION)
RQ1. 使用我们的源到源(source-to-source)变换方法,安全函数比例可以提升到什么程度?
我们通过对开源与商业C 项目在转译前后的对比来评估 CRustS 的效果。
对数据集中每个项目,我们统计其代码规模(以代码行数 计)以及其安全/不安全函数比例。然后,我们将这些统计与使用 c2rust 与 CRustS 转换后的若干项目进行对比,以衡量安全函数比例的提升与处理效率。结果见表 1。
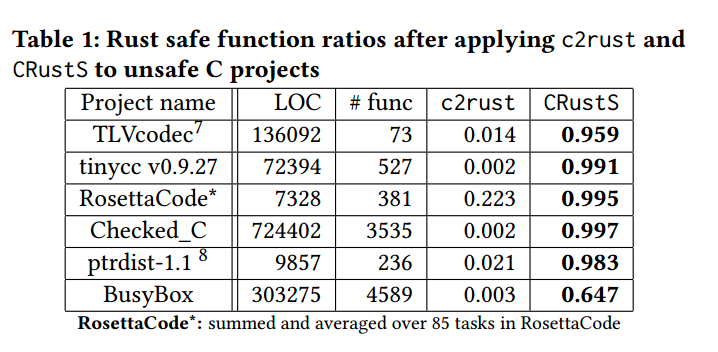
如结果所示,相比于原始(按定义其安全函数比例为 的)不安全 C 项目,转换后的安全函数比例获得了显著提升。需要注意的是,大多数项目的安全函数比例都超过 。尽管 BusyBox 的安全函数比例明显低于 ,但与之前已被转换的 RustyBox 项目相比,改进幅度仍然可观。进一步分析显示,该案例中相对较低的安全函数比例主要由其操作系统相关的数据结构所致——这在操作系统类项目中较为常见。针对该类型项目的解决方案将是我们后续研究的方向之一。
RQ2. 这些提升安全性的 Rust 项目转换成果,在产品团队中是如何被接受的?
某大型通信公司的多个产品团队试用了 CRustS。其中一个来自 TLVcodec 产品的团队给出了正面反馈。最突出的评价包括:“它克服了学习一种新语言的陡峭曲线”,以及“它减少了将遗留 C 代码转到 Rust 的工作量”。
另一个产品团队在一个低层硬件控制产品上试用了 CRustS,希望将一个核心 C 模块的 2K 行代码快速转成Rust 初始版本,以便启动该模块从 C 到 Rust 的迁移。在这次尝试中,工具在生产环境中的初始部署与小幅适配耗时约两天,随后又在一天后产出了转换得到的 Rust 项目。与人工重写相比,该方案的交付周期显著更短;据项目经理评估,在该特定案例中,人工重写将超过两周。
该团队对我们的工具给予了高度评价,认为它“很快就产出了一个 Rust 初始实现,并为后续工作提供了坚实的踏板”。与此同时,他们也指出了工具的若干不足,主要集中在C 宏与枚举(enum)处理方面;这些问题已纳入我们的改进计划。
Citation
Ownership Guided C to Rust Translation
Computer Aided Verification (CAV 2023)、CCF A
Don’t Write, but Return: Replacing Output Parameters with Algebraic Data Types in C-to-Rust Translation
Proceedings of the ACM on Programming Languages (PACMPL) - PLDI 2024、CCF A
论文提出把c风格的输出参数替换为Rust风格的函数返回值
Concrat: An automatic C-to-Rust lock API translator for concurrent programs
ICSE 2023、CCF A
把C风格的锁替换为Rust的锁API
VERT: Verified Equivalent Rust Transpilation with Large Language Models as Few-Shot Learners
提出了 VERT:先把源语言经由 WebAssembly 编译成“正确性先验”的 Rust 参考程序,再用 LLM 生成可读的候选 Rust,并通过形式化验证与参考程序对比;若验证失败就迭代重生成,最终得到既可读、又具正确性保证的 Rust 翻译。
EVOC2RUST: A Skeleton-guided Framework for Project-Level C-to-Rust Translation
采用骨架引导式翻译策略实现项目级转换
Towards a Transpiler for C/C++ to Safer Rust
C++ to Rust
Integrating Rules and Semantics for LLM-Based C-to-Rust Translation
该论文针对遗留 C 代码自动翻译到 Rust 的难题,指出早期规则法覆盖有限、直接用 LLM 翻译又常违反 Rust 规则且语义不一致。为此提出 IRENE 框架,结合规则增强检索(由自研静态分析器生成规则选例)、结构化摘要引导语义理解与基于编译器诊断的迭代纠错,并在 xCodeEval 与华为 HW-Bench 上用八种 LLM 评估其翻译准确性与安全性。