Challenging Machine Learning-based Clone Detectors via Semantic-preserving Code Transformations
Challenging Machine Learning-based Clone Detectors via Semantic-preserving Code Transformations
论文来自 2023 IEEE Transactions on Software Engineering (TSE 2023) 的《Challenging Machine Learning-based Clone Detectors via Semantic-preserving Code Transformations》。
摘要
软件克隆检测可识别相似或相同的代码片段。在过去的二十年里,它一直是一个活跃的研究课题,引起了广泛的关注。近年来,基于机器学习(ML)的检测器,特别是基于深度学习的检测器,在克隆检测方面表现出了令人印象深刻的能力。由于机器学习技术的进步,这个长期存在的问题似乎已经得到了解决。在这项工作中,我们想通过代码语义保持转换来挑战最近基于机器学习的克隆检测器的鲁棒性。我们首先利用十五个简单的代码转换运算符结合常用的启发式方法(即随机搜索、遗传算法和马尔可夫链蒙特卡洛)来执行等效的程序转换。此外,我们提出了一种基于深度强化学习的序列生成(DRLSG)策略,以有效地指导生成可能逃脱检测的克隆的搜索过程。然后,我们使用原始和生成的克隆对评估基于ML的检测器。我们在一个名为CLONEGEN(代表克隆生成器)的框架中实现了我们的方法。
在评估中,我们借助CLONEGEN对两个最先进的基于机器学习的检测器和四个传统检测器进行语义保持转换后的代码克隆进行了挑战。令人惊讶的是,我们的实验表明,尽管现有的克隆检测器取得了显著的成功,但这些检测器内的ML模型仍然无法区分CLONEGEN中代码转换产生的大量克隆。
此外,使用CLONEGEN生成的克隆对基于ML的克隆检测器进行对抗训练可以提高其鲁棒性和准确性。同时,与常用的启发式算法相比,DRLSG策略在生成代码克隆以降低基于ML的检测器的检测精度方面表现出了最佳的有效性。我们的调查揭示了最新基于机器学习的检测器的一个可解释但始终被忽视的鲁棒性问题。因此,我们呼吁更多地关注这些新的基于机器学习的检测器的鲁棒性。
1. Introduction
通过复制和粘贴操作重用CODE在软件开发中很常见。这种做法通常会生成大量类似的代码,这通常被称为代码克隆。根据Mockus进行的大规模研究[1],超过50%的文件在一些开源项目中被重用。虽然代码克隆在适当利用的情况下可能会有所帮助[2],但由于痛苦的维护成本,它也可能成为糟糕的编程实践[3]。例如,Li等人[4]报告称,22.3%的操作系统缺陷是由代码克隆引起的。此外,代码克隆还会带来侵犯情报财产[5]、[6]、[7]和安全问题[4]、[8]。
回顾过去,源代码克隆检测是一个备受关注的活跃研究领域。基于各种类型的代码表示,已经提出了多种克隆检测器,包括基于文本或token的[9][10]、基于AST的[11]、基于PDG(程序依赖图)的[12]等。这些传统检测器主要用于基于语法的克隆检测(具有语法相似性的克隆)。此外,它们中的许多能力有限(例如,专门用于某种类型的克隆),效率低[13],[14]。
最近,最新的机器学习(ML)方法显著提高了克隆检测器的能力。例如,FCDETECTOR[15]通过AST(抽象语法树)和CFG(控制流图)捕获代码语法和语义信息,训练DNN网络来检测函数的克隆。ASTNN[16]维护了一种基于AST的神经源代码表示,该表示利用双向模型来利用源代码语句的自然性进行克隆检测。TBCCD[17]从AST中获得代码片段的结构信息,从代码标记中获得词汇信息,并采用基于树的传统方法来检测语义克隆。CCLEARNER[18]从源代码中提取标记来训练基于DNN的分类器,然后使用该分类器检测代码库中的克隆。这些新的基于机器学习的方法将最新的机器学习技术与从克隆中提取的代码特征融合在一起,从而获得了高度准确的结果。通常,它们可以检测到大多数语义克隆,准确率超过95%[15]、[16]、[17]。
尽管新的基于机器学习的克隆检测器已经取得了令人印象深刻的成就,但它们的有效性在很大程度上依赖于标记良好的训练数据[19]。用一个数据集训练的检测器的性能在检测另一个数据集中的代码克隆时可能不太有效。与简单的文本不同,源代码包含文本和结构信息,这使得地面实况克隆对更加通用。因此,构建用于代码克隆检测的稳健预测模型本身就具有挑战性。例如,代码片段int b=0;和 int b; b=0;具有相同的语义,但它们的CFG和AST略有不同。因此,与其应用大量的代码混淆和编译器优化,我们能否在某些程序位置生成轻量级的源代码变体,从而有效地降低基于机器学习的检测器的准确性?从这一点出发,我们研究并观察到,采用代码片段的语义保持转换在验证基于机器学习的克隆检测器的鲁棒性方面具有实际意义。
具体来说,我们提出了一个名为CLONEGEN的框架,该框架执行语义保留代码转换,以挑战基于机器学习的克隆检测器。在CLONEGEN中,我们开发了15种轻量级和语义保持的代码转换(例如,变量重命名、for循环到while循环转换、代码顺序交换等)。一般来说,CLONEGEN针对给定代码片段进行廉价但有效的转换(或转换组合),以逃避克隆检测。为了有效地指导15个原子变换的组合,CLONEGEN支持各种启发式策略(即随机搜索、遗传算法和马尔可夫链蒙特卡洛)。从本质上讲,快速找到逃避克隆检测的(接近)最优解是一个如何组合多个变换的优化问题。为了解决这个问题,我们设计了一个深度强化学习(DRL)序列生成模型(称为DRLSG),该模型使用邻近策略优化(PPO)策略神经网络[20]来指导搜索过程。
使用CLONEGEN,我们从广泛使用的OJClone数据集中选择独特的代码片段[21]。给定一个选定的代码片段x,我们生成语义保留的变体,并将x与每个变体配对。然后,我们将形成的克隆对馈送到基于ML的检测器,以质疑它们是否仍然可以确定我们的框架生成的这些代码克隆。
为了评估克隆基因的有效性,克隆基因生成的克隆对被提供给两个最先进的开源基于机器学习的检测器(即ASTNN和TBCCD),以及一个基线检测器TEXTLSTM[22]。我们发现,CLONEGEN提供的克隆对中,分别有40.1%、32.9%和44.2%能够成功避开ASTNN、TBCCD和TEXTLSTM的检测。考虑到这些检测器在OJClone数据集上的原始准确率(超过95%),实验结果证明,CLONEGEN通过DRLSG引导的轻量级代码转换,在降低基于ML的克隆检测器的准确率方面非常有效。同时,我们进一步评估了CLONEGEN通过对抗训练提高基于机器学习的克隆检测器鲁棒性的有效性。在最好的情况下,对抗性训练将模型的f度量提高了43.9%。我们发现,在DRLSG提供的克隆对中,13.2%和15.8%在对抗训练后仍能成功逃脱ASTNN和TBCCD的检测。
总之,我们做出了以下贡献:
- CLONEGEN的设计和实现,它支持各种启发式策略来指导代码转换,并生成语义保持的代码克隆来挑战克隆检测器。
- 提出了一种新的基于DRL的策略,该策略在不同的程序位置调度多个轻量级但有效的代码转换运算符。
- CLONEGEN在基于机器学习的探测器(ASTNN、TBCCD和TEXTLSTM)和传统探测器(NICAD和DECKARD)上的评估。结果表明,CLONEGEN会显著降低这些探测器的探测精度。
- 使用CLONEGEN产生的克隆对基于机器学习的检测器进行进一步的对抗训练,这可以提高所评估的基于机器学习检测器的鲁棒性。值得注意的是,基于DRL的策略在降低对抗训练检测器的检测精度方面最为有效。
2. 序言
2.1 克隆的类型和克隆检测方法
Definition 1. 根据[23],代码克隆通常分为四种类型,即I型、II型、III型和IV型,分别表示原始代码段和新代码段之间的代码相似程度。
- 类型I:除了注释、缩进和布局之外,这两个代码片段基本相同。
- 类型II:除了类型I引起的差异外,两个代码段之间的差异在变量名、函数名、类型等方面也有限。
- 类型III:除了由于类型I和II而产生的差异外,这两个代码片段还进行了轻微的修改,如更改、添加、删除或重新排序语句。
- 类型IV:类型IV仅保留语义相似性。因此,这两个代码片段可能具有相似的功能,但结构模式不同。
I-III型代码克隆通常被称为语法克隆,它复制代码片段并保留大量文本相似性。相比之下,如果复制的代码只是暴露了功能相似性,例如克隆呈现了IV型克隆,即所谓的语义克隆。
多年来,文献中出现了各种克隆探测器[13],[14]。通常,他们将检测到的软件代码转换为特定的表示,并开发方法来区分与生成的表示的相似性。在基于机器学习的检测器出现之前,传统的检测器(如CCALIGNER[10]、DECKARD[11]、CCGRAPH[12])主要依靠token、AST或PDG表示来衡量代码相似性。通常,它们可以成功检测I-III型句法克隆,但无法匹配IV型语义克隆。ASTNN[16]将整个AST拆分为小语句树,用于对程序词汇和句法信息进行手指粒度编码。FCDETECTOR[15]采用融合嵌入生成的句法和语义特征的联合代码表示。TBCCD[17]应用基于树的卷积进行语义克隆检测,该方法利用AST的结构信息和代码标记的词汇信息。这些基于机器学习的检测器在实验数据集上都实现了惊人的高检测精度,通常检测精度超过95%[15]、[16]、[17]。
2.2 克隆检测示例
图1显示了一个代码片段S和S上的IV型和突变型克隆。代码S来自OJClone[21]数据库。它是为了找到不同货币面额(例如{100,50,20,10,5,1})的最小钞票数量,这些钞票加起来等于给定的金额(即输入变量n)。图1中的所有克隆都是同一问题的解决方案,但句法变化程度不同。具体来说,Type IV实例更紧凑——它使用除法而不是连续减法来获得第11行的整数商,并在一个循环中完成计算和打印。

对于这个激励性的例子,训练有素的ASTNN、TEXTLSTM和TBCCD都可以正确地将IV型代码(参考图1中的代码片段#2)与原始代码(图1中参考代码#1)匹配起来——基于机器学习的检测器成功识别了句法和语义克隆。到目前为止,这些基于机器学习的检测器似乎非常有效,但它们能彻底解决语义克隆检测问题吗?
2.3 Motivation
对于上述问题,我们通过应用几个轻量级代码转换来手动创建克隆代码。给定图1中的代码片段#1,在更改第4行的变量名k后,在第3行将大常数拆分为较小的常数,在第3.4行交换代码顺序,删除第5行的部分代码注释,并在第7,8,9,12行将for循环转换为while循环,我们生成了图1中代码片段#3)。
然后,我们通过将新代码#3与图1中的现有代码段配对,构建了两个克隆实例{#1,#3}和{#2,#3}。现在,我们在这些新的克隆实例上运行ASTNN、TEXTLSTM和TBCCD。我们很好奇,一些简单的代码变体是否会导致一些不同的发现。令人惊讶的是,实验结果表明,所有三个检测器都未能将所有两个代码对归类为代码克隆。这一有趣的结果意味着,一些廉价的代码级更改确实可以使这些检测器中的DNN无效,而无需使用专用的对抗样本或大量的代码混淆(例如,基于编码的混淆[24]、[25]、[26]和CFG平坦化[27]、[28])。这一观察促使我们研究以下问题,以促进对抗性代码克隆生成的自动化:
- 轻量级语义保持转换的代码克隆能否稳定地使基于ML的检测器的检测无效?
- 需要什么样的转换策略来指导组合这些语义保持转换的有效搜索过程?
- 我们能否利用语义保持转换中的新克隆实例来改进基于ML的检测器,这些改进是否会带来明显的好处?
为了回答这些问题,我们提出并实现了克隆生成框架CLONEGEN。
3. CLONEGEN: 概述
在本节中,我们将描述评估基于机器学习的克隆检测器的总体工作流程,解释我们必须解决的三个技术挑战。
3.1 The Overview of CLONEGEN
图2展示了CLONEGEN的概览。一般来说,克隆基因由两个阶段组成:克隆生成阶段和探测器评估阶段。前者以源代码片段作为输入,执行代码等价转换,并输出变异的代码片段。后一个评估阶段将原始代码片段与新生成的代码片段一起馈送到一组最先进的克隆检测器,并输出这些检测器是否可以检测到新的克隆对。
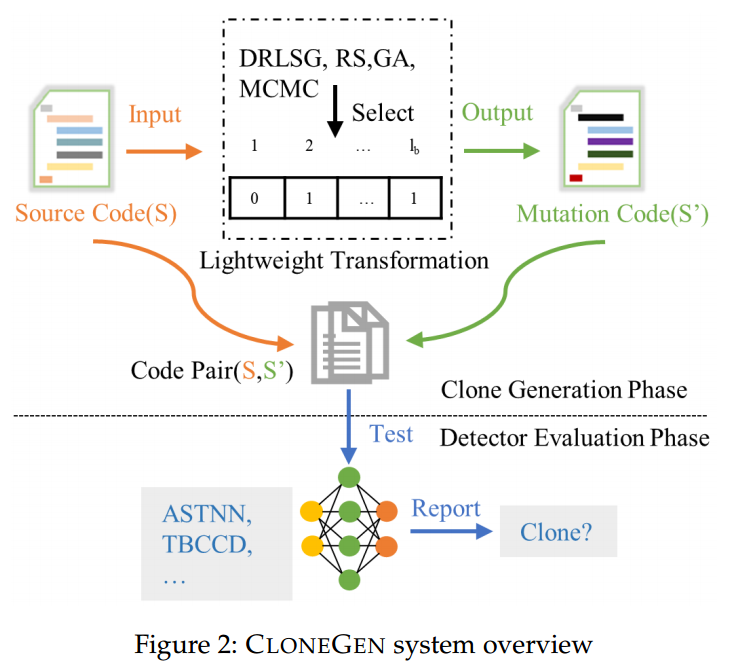
例如,给定图1中的代码#1,CLONEGEN生成代码片段#3的步骤如下。首先,它提取代码片段#1的特征,并搜索可以应用代码转换的位置(见§4.2)。其次,它采用预定义的15个原子转换运算符,以确保所有执行的更改都保留了原始代码的语义(见§4.1)。第三,CLONEGEN还采用了某种转换策略,适当调整激活单个转换运算符的概率(见§4.3)。最后,通过按照搜索策略确定的顺序应用变换运算符,可以生成更有可能从现有检测器中逃逸的新代码(见§4.4)。到目前为止,克隆生成阶段已经完成。
3.2 技术挑战
虽然高层次的想法似乎很简单,但要实现CLONEGEN,有三个挑战需要解决:
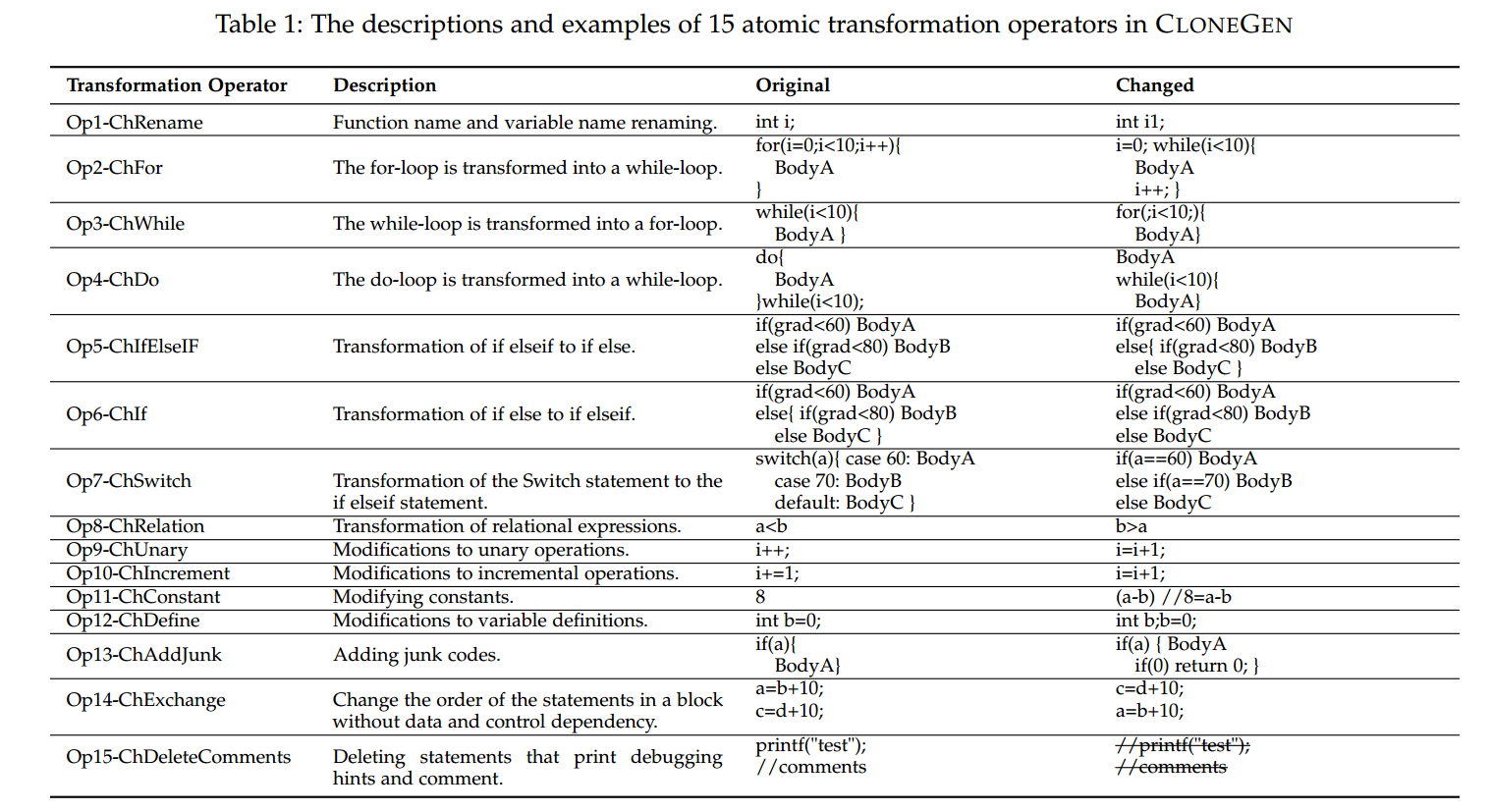
Transformation Operator。在这项工作中,我们需要等价转换,它稍微修改了代码的语法,但保留了代码的语义不变。因此,本研究中的算子不同于突变测试中的突变算子[29]。突变测试对源代码进行突变,以便在程序中插入小错误来衡量测试套件的有效性。因此,变异测试中的变异者在生成新代码时通常会改变代码语义。然而,我们的目标是实现语义等价转换。为了实现这一目标,我们采用了[30]和[31]中提出的许多转换运算符。CLONEGEN总共支持15个唯一的转换运算符,包括变量重命名、用等效语义更改语法结构、添加垃圾代码、删除无关代码、重新排序独立代码等。细节和示例见§4.1。
编码方案(Encoding Schema)
在应用变换算子之前,需要先定位那些可能适用于相应算子的代码位置。举例来说,我们必须先在代码中找到所有的for循环,才能决定是否执行算子 Op2(见表 1 中的 Op2)。因此,满足变换条件的代码片段会被抽象出来以便进行编码。由于评测面向大型代码库,这种抽象需要快速且可扩展。为此,CLONEGEN 设计了一种紧凑的基于比特向量(bitvector)的表示法,用于对“修改某个函数”的搜索空间进行编码。具体而言,设一个函数包含下列要素的数量:
- :变量总数(包括函数名、函数形参、局部变量以及被使用到的全局变量);
- :
for循环语句数; - :
while循环语句数; - :
do-while语句数; - :
if-elseif语句数; - :
if-else语句数; - :
switch语句数; - :关系表达式数;
- :一元运算数(如
i++); - :自变更运算数(如
i+=1); - :常量值的数量;
- :变量定义出现的次数;
- :代码块(
{...})数量; - :同构语句块的数量(这些语句块在控制流中彼此无依赖);
- :
print与注释语句的数量。
则编码后比特向量的长度为上述各值之和:
在生成阶段(generation phase),若某个二进制位被置为 1,CLONEGEN 就会在对应的代码位置应用相应的变换算子。然而,如何为等价变换选择与特定代码结构相匹配的算子,并制定最优应用策略,仍是一个困难问题——目标是在不同优化目标下生成语义克隆。因此,我们需要一种变换策略(transformation strategy)。
Transformation Strategy. 如上所述,在定义转换运算符并对搜索空间进行编码后,还有另一个挑战:我们应该如何决定编码后每个比特的启用机会(即1),以最大限度地提高生成的语义克隆的多样性,从而挑战现有的基于机器学习的克隆检测器?一般来说,这似乎是一个具有巨大搜索空间的组合优化问题(例如,图1中的代码片段#1为245),可以通过常用的启发式策略来解决,如随机搜索(RS)、遗传算法(GA)[32]、马尔可夫链蒙特卡洛(MCMC)[33]和最近流行的深度强化学习(DRL)等。这些策略通常需要一些目标或目标函数(例如,遗传算法中的适应度函数)。关于这一挑战,在§4.3中,对于常用的策略(RS、GA和MCMC),我们根据一些现有的研究[34]、[35]、[36]实施这些策略来指导转型。然而,利用DRL来解决这个问题并不简单,为此,我们在第5节中提出了DRLSG模型。
4. CLONEGEN: TECHNICAL APPROACH
在本节中,我们将详细介绍CLONEGEN的主要步骤。
4.1 变换算子(Transformation Operator)
CLONEGEN 通过一组原子操作(atomic operations)来变换给定程序的源代码。这些代码变换不得改变程序的语义。因此,我们形式化地把这些操作定义为等价变换(equivalence transformations)。
定义 2(等价变换). 设
表示对代码片段 施加一组原子代码变换算子 的组合而得到代码片段 的一次变换()。则 与 构成一对语义克隆(semantic clones)。
表 1 总结了 CLONEGEN 中所有的原子变换算子。第一列给出算子名称,第二列简要描述每个原子操作如何生效,第三列展示一次等价变换之前的一个简单代码示例,最后一列给出变换之后的代码。图 3 展示了代码变换连续表述(successive formulations)的表示方法。我们基于 Txl语言 实现了这些算子。

基于表 1 所定义的这 15 个算子的变换是轻量级(lightweight)的,因为在 TXL 中仅采用了词法分析。由于没有在 CFG(控制流图)、PDG(程序依赖图)或CG(调用图)上进行复杂的操作,故这些变换只在语法层面起作用。
与此同时,变换仍然能够保证语义等价——所有算子都保证在变换前后保持相同语义。即便是 Op4(把 do-while 循环语句改写成 while 循环),其语义仍是等价的:do-while 循环体会在进入改写后的 while 循环之前先执行一次。对于 Op14,我们只对没有任何数据或控制依赖的语句进行重排,这类分析既快速又简便。对于 Op15,我们只删除注释或用于打印调试提示、中间结果的语句。对其余算子而言,也可以直观地看出它们不会改变代码语义(关于这些算子的操作语义,请参见图 3 中的定义)。
4.2 编码(Encoding)
在进行代码变换之前,必须先识别语法特征(syntactic features),即表 1 中某个原子操作可应用到的代码片段位置。我们使用 feature count(特征计数) 来表示 CLONEGEN 能在多少个代码片段上执行相应的原子操作。表 2 以图 1 的代码 #1 为例,展示了这些语法特征及其特征计数。表 2 的第一列与第二列分别对应表 1 中的原子操作与其所使用的记号变量,第三列给出它们的取值。最后一列列出了对图 1 中代码 #1 进行编码后得到的比特向量。
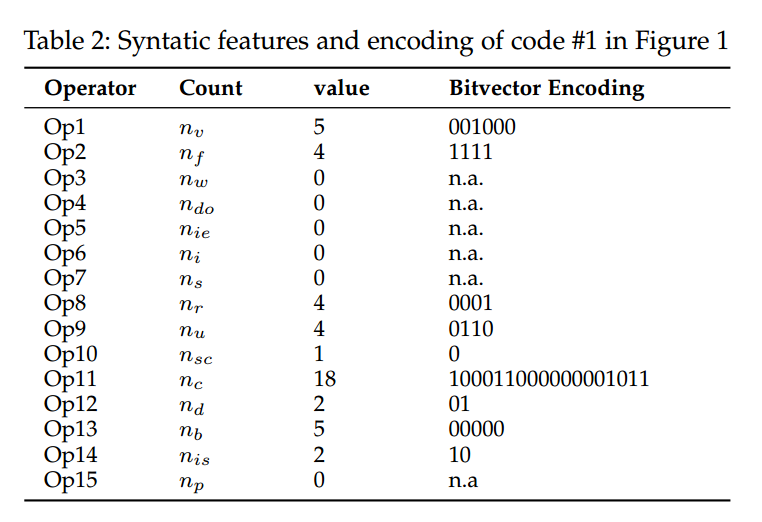
例如,如果某段源代码中有 4 个 for 循环,那么语法特征 for-loop 的特征计数就是。
在第三列中,数值 0 表示不存在可以应用对应原子操作的位置。比如,代码 #1 中没有 while 循环,因此.
又如,代码 #1 中共有 5 个变量 ,于是。 需要注意的是,main 函数不能被重命名,因此不计入 的特征计数。
综上,针对图 1 的代码片段 #1,其比特向量长度为,即表 2 中 “value” 一列数值之和。
使用比特向量对变换搜索空间编码之后,比特向量的长度就等于第二列给出的特征计数;当某个比特位为 1 时,表示相应的原子操作会在这些特征(即可应用的位置)上生效;为 0 时则不生效。符号 “n.a.” 表示没有可用的语法特征与该原子操作匹配,此时特征计数必须为 0。下一节将说明我们如何用不同策略来填充这个比特向量。
4.3 变换策略(Transformation Strategy)
在完成编码步骤之后,CLONEGEN 需要一套变换策略来生成多样化的语义克隆。
如前所述,寻找“应用若干原子操作的最优次序”的搜索问题,可以视为一个组合优化问题。因此,我们可以借助现有的优化算法来得到不同的解。在 CLONEGEN 中,我们实现了三种常用的启发式策略:随机搜索(RS)、遗传算法(GA)、马尔可夫链蒙特卡洛(MCMC)。各策略要点如下。
Random-Search(随机搜索):
RS 策略以等概率将比特向量中的各位随机置为 0 或 1。它不考虑待检测源代码的结构,也不考虑不同克隆检测器采用的特征。因此,RS 更倾向于生成其等价改动主要源于随机性的语义克隆。
Genetic Algorithm(遗传算法):
GA 策略在每次随机生成之后,计算原始代码与新生成代码之间的相似度。其核心思想是生成在文本层面与原始代码差异最大的代码。具体做法是:将两份代码都转换为字符串,再计算它们的字符串编辑距离 [39] 以获得代码相似度。编辑距离反映“把一个字符串变为另一个字符串所需的修改步数”,这里将其作为 GA 的适应度函数(fitness function)。因此,GA 倾向于生成与原代码差距较大(编辑距离大)的语义克隆[35, 36]。
Markov Chain Monte Carlo(马尔可夫链蒙特卡洛):
MCMC 策略使用 n-gram 算法来估计一个子序列在给定前缀后出现的概率。已有研究观察到,软件程序具有概率性特征,可为不同的词序列分配概率[34, 40]。给定代码语句序列,我们用 来近似表示在语句 到 之后出现语句 的概率。受 [41] 启发,我们还引入 困惑度(perplexity) 指标来衡量代码出现的概率“难度”。当使用 n-gram(令 )时,困惑度为:
依据上式,MCMC 通过若干次迭代来引导代码变换,并输出满足上述困惑度条件的克隆。于是,MCMC 倾向于生成难以理解(困惑度高)的语义克隆 [34]。
尽管上述三种策略总体上是有效的,但它们没有把被评估的克隆检测器的反馈(如检测结果)纳入考虑。为缓解这一限制,我们专门设计并实现了一种基于深度强化学习(DRL)的方法 DRLSG,以交互式地利用检测器的结果来生成更复杂的语义克隆(见 §5)。
4.4 克隆生成(Clone Generation)
如图 2 所示,CLONEGEN 在不同策略的引导下执行轻量级的变换阶段。以一个示例说明:在图 1 的原始代码中存在 4 个 for 循环。表 2 的最后一列给出了使用 RS(随机搜索)策略得到的比特向量。正如 §4.2 所述,比特向量中比特位为 1 表示 CLONEGEN 必须在相应的代码片段上执行代码变异操作;比特位为 0 则表示应当保持该处代码不变。由于算子 Op2 的所有相关比特位都被置为 1,CLONEGEN 会把这 4 个 for 循环都变换为保持语义的 while 循环(见图 1 中的代码 #3)。因为这些策略带有随机性,我们可以得到大量的代码变体(例如,把图 1 中的代码 #3 进一步变为代码 #1 的多种版本)。对于 RS 之外的策略(即 GA、MCMC 与 DRLSG),并不会保留所有变体——为了保证有效性,只会保留那些满足特定优化目标(例如困惑度)的变体。值得注意的是,我们的原子操作是轻量级的:根据实验(§6 所述),这些变换操作都能在相对较短的时间内完成。
5. DRLSG: THEORY AND DESIGN
在本节中,我们介绍了强化学习的背景知识和我们提出的深度强化学习序列生成(DRLSG)策略。
5.1 深度强化学习
近年来,深度强化学习(DRL)算法已被用于各个领域[42]、[43]、[44],最著名的是AlphaGo[45],用于击败围棋中最好的人类棋手,DRL已迅速成为人工智能界的焦点。本文基于深度强化学习为变换序列生成高质量的源代码。在我们开始介绍我们的方法之前,我们简要介绍了DRL的背景知识。以下典型DRL过程的表述与[46]中给出的演示有关。
我们简要介绍DRL中常用的术语:
- Agent:学习者和决策者的角色。
- Environment:由主体以外的事物组成并与之交互的一切。
- Action:代理体的行为表示。
- State:能力体从环境中获得的信息。
- Reward:环境对行动的反馈。
- Strategy:代理根据状态执行的下一个动作的功能。
- on-policy:代理学习和与环境交互时对应的策略是相同的。
- off-policy:当要学习的代理和与环境交互的代理不同时的策略。
在强化学习中,策略(policy)指明在给定状态下应采取的动作,通常记为 。若用深度学习技术进行强化学习,策略就由一个神经网络表示。网络内部含有一组参数,我们用 表示策略 的参数 [47]。我们把环境输出的状态 与智能体输出的动作 按时间串接起来,记作一条轨迹(Trajectory) (如下式):
每条轨迹发生的概率可写为:
回报函数(reward function)决定了在某一状态下采取某个动作能够获得多少分。我们的目标是调整演员(actor)中的参数 ,使得期望回报
尽可能大。因此我们采用梯度上升:
其中,仅 与 有关,可得其梯度形式为
PPO(Proximal Policy Optimization) [20] 属于策略梯度的一种。用当前策略 采样得到的数据在 更新后就过时了;为了复用旧数据,我们希望从on-policy 转到 off-policy。做法是采用重要性采样(importance sampling),把参数从 替换为 。此时,数据由 采样得到,但训练时要调整的仍是模型参数 。梯度变为:
5.2 DRLSG的设计
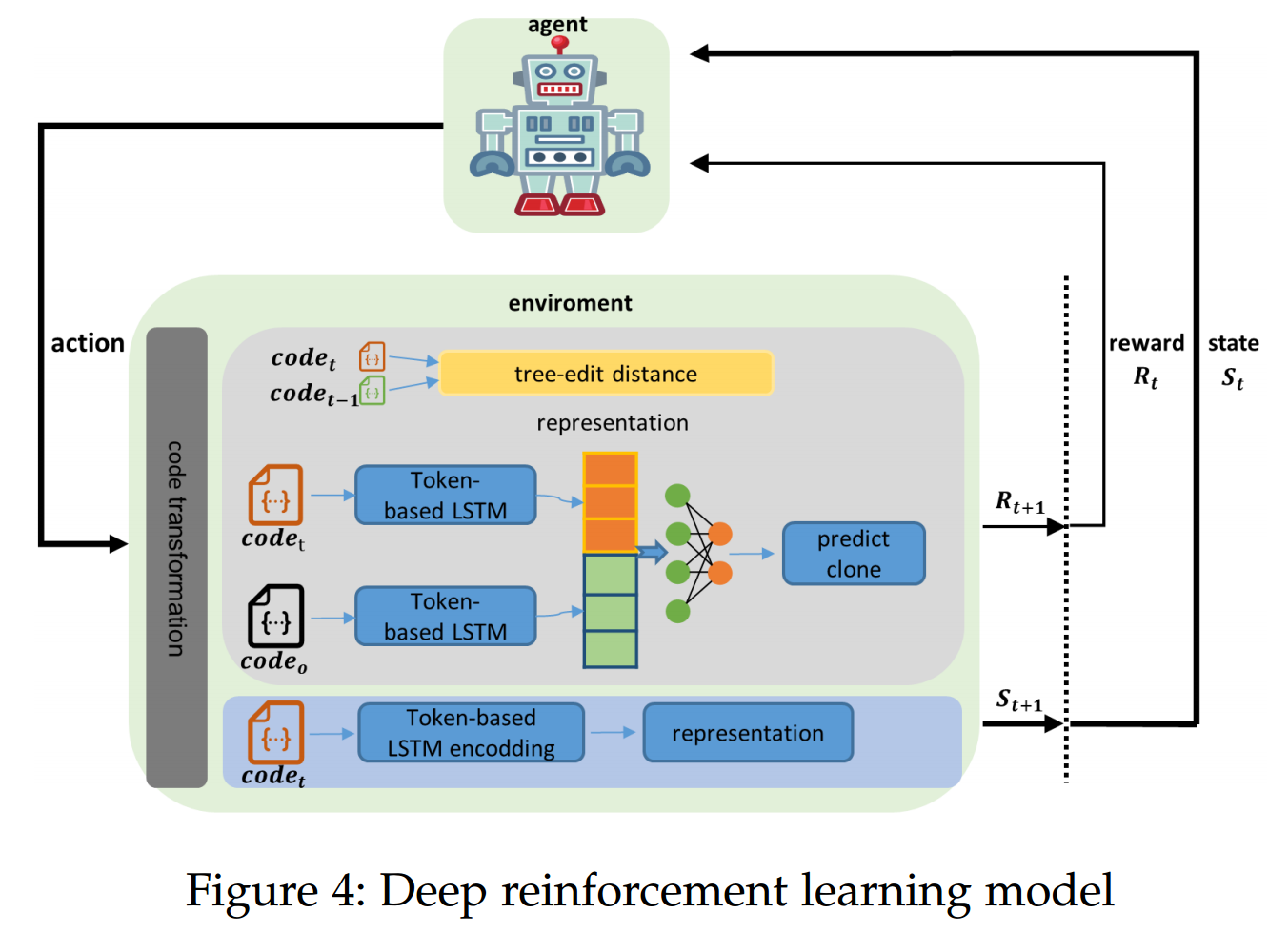
如图4所示,我们的DRLSG模型有两个主要组成部分:代理和环境。代理主要由神经网络组成,这里我们选择openAI开源的PPO2模型作为我们的代理。代理的输入是代码的编码向量(状态),我们训练代理选择相应的变换算子§4.1,以最大化奖励值。环境由三个主要部分组成:根据代理选择的动作进行代码转换,对代码进行编码以获得作为环境状态的向量,并计算当前决策的奖励。接下来,我们将介绍DRLSG的具体设计。
5.2.1 动作空间
在DRLSG任务中,训练代理从给定状态的动作空间中选择要执行的动作。我们使用设计为模型动作空间的15个转换,在我们的任务中,模型的目标是从15个转换中选择一组操作来转换源代码。这些变换如表1所示,其中我们给出了具体操作和简单示例的描述,图3中我们给出了相应等效变换的形式化定义。
5.2.2 Reward
奖励函数旨在指导代理的整体行为,奖励是DRL的关键,我们需要最大化代理的累积收益。我们代理的主要目标是生成可以逃脱基于M1的克隆工具检测的变体代码。为此,我们将每一步的奖励函数形式化为算法1。

如图 4 所示,我们的 奖励(reward) 由与当前动作相关的两个主要组成部分构成:
- 计算当前代码与前一时刻代码之间的编辑距离(即 与 之间);
- 基于当前动作得到 与基准代码 之间的克隆检测结果。
二者共同构成奖励,我们考虑的是长期回报。
我们实现了一个基于文本的孪生网络(Siamese)源代码克隆检测模型,使用两套双向 LSTM(BiLSTM) 作为孪生结构中的两个分支。将 与 转换为文本序列后输入 BiLSTM,获得其表示。如果 TextLSTM 将 与 判为非克隆,我们就给予一个较大的正奖励(见算法 1 的第 1–3 行),并终止当前轮学习,表示我们已经得到了当前代码的一条有效变换序列。
编辑距离(edit distance)表示把一个字符串变为另一个字符串所需的最少单字符编辑操作次数,操作包括:插入、删除、替换。例如,把 “kitten” 变为 “sitting” 的最少操作序列为:将 “k” 替换为 “s”,将 “e” 替换为 “i”,并在末尾插入 “g”,因此两者的编辑距离为 3。基于编辑距离,我们实现了一个文本序列相似度指标 代码文本相似度(Code Text Similarity,记作 codeTextSim),定义如下:
其中,len 表示代码序列的长度;若两段代码的编辑距离为 0,则它们的相似度 codeTextSim = 1.0,意味着两段代码没有差异。如果当前状态模型所执行的动作产生的 相比前一状态的 没有变化,则它们的 codeTextSim = 1。对此我们给予一个负惩罚:(见算法 1 的第 4–6 行)。这样设计的目的是避免环境中的奖励过于稀疏,从而提升学习效率并尽快收敛 [48]。另外,由于理论上可以插入无限量的“垃圾代码”,为控制代码复杂度,我们使用 统计在当前回合中 op13 被使用的次数;若当前智能体选择的动作为 op13,还会额外施加一个负惩罚 (算法 1 的第 7–10 行)。在实现中,我们经验性地将 、 与 分别设为 10、0.5 与 0.5。
5.2.3 状态(state)
在 DRL 中,状态表示环境的当前状态。在我们的模型里,由当前动作得到的变换后代码即表示当前状态,并可用该代码的编码向量表征。对于给定的源代码,我们先把它转换为文本序列,再用一个双向 LSTM 模型对其进行编码;该模型与 §5.2.2 中提到的克隆检测模型相同。
6. Evaluation
在本节中,我们旨在通过实验评估调查以下四个研究问题(RQ):
- RQ1:不同的转换策略有多有效?现有的基于机器学习的检测器在检测CLONEGEN生成的语义克隆方面的鲁棒性如何?
- RQ2:当检测结果可用时,我们提出的DRLSG的有效性如何?基于机器学习的检测器能否通过CLONEGEN的对抗训练得到增强?
- RQ3:不同类型的原子转换运算符有多有效?
- RQ4:传统的克隆检测器在检测CLONEGEN产生的语义克隆方面有多准确?
6.1 实现与实验设置(Implementation and experimental setup)
6.1.1 CLONEGEN 的数据集(Datasets for CLONEGEN)
在我们的评估中,使用了 OJClone [21] —— 一个在源代码研究中被广泛使用的数据库 [15], [16], [17], [21], [49], [50]。
OJClone 由 104 个文件夹构成,每个文件夹都包含同一题目的 500 份解答(即克隆)。我们从每个 OJClone 文件夹中抽取代码构成初始数据集 ,并分别对 应用 4 种策略(RS、GA、MCMC 与 DRLSG),从而得到 4 个新的数据集,分别记为 、、 与 。

表 3 展示了在 OJClone 数据集中,用这四种变换策略处理 52,000 段源代码所消耗的时间。对每段代码(共 52,000 段),我们都应用四种不同策略以生成成对的代码。需要注意的是:
- RS 策略为每个片段只生成一个代码变体;
- 另外三种策略会生成多个克隆候选,然后利用相应的优化目标选出最佳者。
最终,上述四个生成数据集的规模相同:
RS 策略耗时仅 0.88 小时,为四者中最快。GA 与 MCMC 在变换代码时需要进行一定的语法分析,因此比 RS 更慢。DRLSG 需要一个基于机器学习的编码器来对源代码编码,并利用基于机器学习的检测器进行相似度分析;同时,每次变换只选择一个算子,因此总体上更慢。
6.1.2 被评估的克隆检测器(Assessed Clone Detectors)
已有许多基于机器学习的 C/C++ 源代码克隆检测器(包括 [15], [16], [17], [21], [49], [50], [50], [51], [52], [53] 等)。但其中有些不开源,另一些在处理我们的数据集时存在实现问题(如 FCDETECTOR [15])。最终,我们采用了两个开源检测器:ASTNN [16] 与 TBCCD [17]。此外,我们还在 OJClone 数据集上应用了 TextLSTM [22] 模型。训练/测试步骤遵循其 GitHub 页面提供的指南,并采用文献 [16], [17] 推荐的参数,以保证公平比较。
这里,TextLSTM 的文本嵌入维度为 300,BiLSTM 的隐藏层大小为 256。训练过程中,我们将数据集按 80%/10%/10% 划分为训练/验证/测试集,使用 Adam 优化器(学习率 0.001)训练 20 个 epoch,并在训练过程中保存 F1 最佳的模型。上述超参均根据我们的实验经验设定。
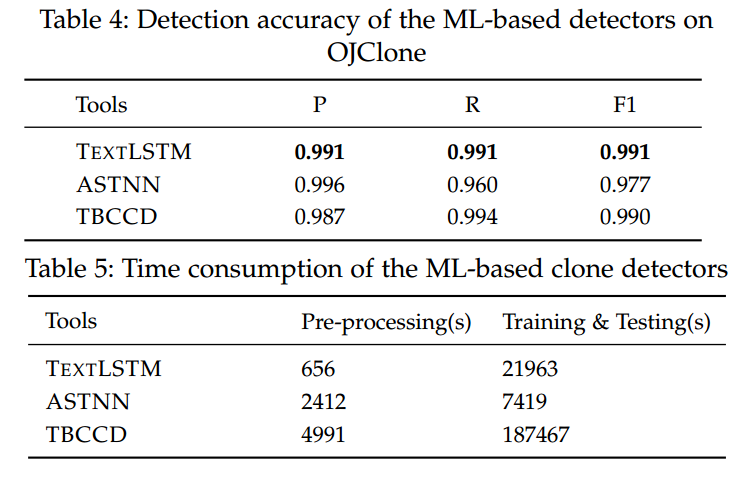
详细结果见表 4:ASTNN 与 TBCCD 由我们复现得出,它们在 OJClone 上的 F1 均 > 0.96。由于 OJClone 差异较大、属于 IV 型克隆,这表明现有的 ML 检测器已取得较好效果——其中 TextLSTM 的 F1 = 0.991,表现最佳。表 5 汇总了三种 ML 检测器在搭建过程中的耗时:TextLSTM 在数据预处理上耗时最少;ASTNN 在训练与测试上耗时最少;TBCCD 耗时最多(预处理 1.38 小时,训练与测试 52 小时)。
6.1.3 基线变换策略(Baseline Transformation Strategies)
如 §4.3 所述,搜索“最优原子操作序列”的问题可以视为组合优化。因此,我们可以借助多种优化算法来获得不同解。在本文中,我们把所提出的 DRLSG 与常用的启发式策略 RS、GA、MCMC 进行比较。GA 的参数设置参考了相关工作 [35], [36], [38];MCMC 的参数设置参考了 [34], [54]。
6.1.4 评价指标(Evaluation Metrics)
得到四个新的数据集后,我们将它们输入被测的克隆检测器。需要注意的是:为了评估检测器内部 ML 模型 的鲁棒性,这些数据集中的实例带有两类标签:clone 与 non-clone。以 为例,它包含 52,000 对克隆对(每一对由原始数据集 的一个样本与 RS 策略生成的对应变体组成),以及 52,000 对非克隆对(来自不同文件夹且经 RS 变换后的代码片段配对)。
我们用精确率(Precision, )、召回率(Recall, )与 F1 值(F1-Measure, )来衡量基于 ML 的检测器的性能。设:
- :把正类正确判为正(真正);
- :把正类错判为负(假负);
- :把负类错判为正(假正);
- :把负类正确判为负(真负)。
则 、、 计算如下:
此外,我们还用 Recall (R) 来评估传统工具在代码克隆检测上的表现;R 是这些检测器(如 [10], [55])常用的评价指标。
笔者注:F1采用调和平均计算,提高P和R中的较小的值对结果更敏感。
6.1.5 实验环境(Environment)
所有实验均在一台 AMAX 计算服务器上完成。其配置为:两颗 2.1 GHz 的 24 核 CPU、四块 NVIDIA GeForce RTX 3090 GPU、以及 384 GB 内存。
6.2 研究问题 RQ1:基于机器学习的检测器 vs. CLONEGEN
本节回答 RQ1:评估 CLONEGEN 绕过基于机器学习(ML)的克隆检测器的有效性。为此,我们将初始数据集 用作三个被评估检测器的训练集。随后,对每一种不同的变换策略,使用其对应生成的数据集()作为测试集。
接着,我们评估这些检测器在 CLONEGEN 生成的代码对上的鲁棒性。表 6 给出了三种检测器的准确率。总体而言,这些基于 ML 的检测器在面对四种变换策略时表现出差异化的准确率。
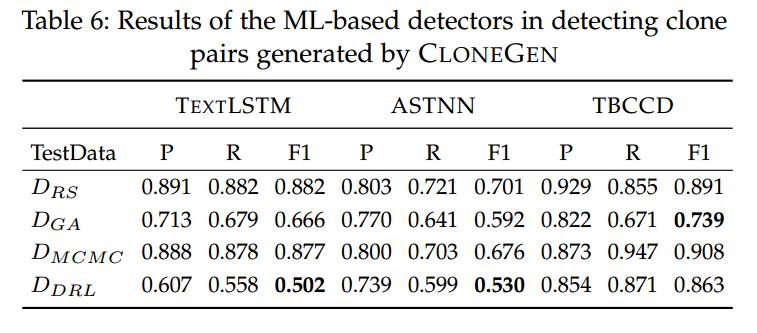
TextLSTM 直接把代码转换为文本序列,送入 LSTM 神经网络以获得代码的嵌入向量,再将该向量输入到一个浅层前馈神经网络进行二分类判断。在 上,TextLSTM 的克隆检测性能最好(表 4 中 )。但在四种策略的测试集上,TextLSTM 的 从 0.502 下降到 0.882 不等,均显著低于其在原始数据集上的表现(0.991)。四种策略中,DRLSG 的绕过能力最强(),而 RS 最弱(),说明随机变换更容易被 TextLSTM 识别。
ASTNN 是建立在程序 AST(抽象语法树)之上的神经网络。其 范围为 0.530–0.701。在四种策略中,DRLSG 表现最好,RS 最差。结果表明,不同策略都能在一定程度上绕过 ASTNN 的 AST 基检测。
TBCCD 同时利用结构化 AST 与词法 token 信息,构建树卷积神经网络。据表 6,TBCCD 相比 ASTNN 与 TextLSTM 具有更好的鲁棒性,平均 。其中对 MCMC 的抵抗最好(),表明其对 MCMC 引导的变换相对不敏感。由 GA 生成的代码对在 TBCCD 上的 ,其次是 DRLSG(0.863)与 RS(0.891)。该结果说明:token 信息的引入提升了基于 ML 的检测器在面对代码变换时的韧性。
小结(基于表 6 的观察):
文本驱动的纯文本检测器 TextLSTM 很容易被绕过;而基于混合抽象(如同时使用 Token 与 AST)的模型更具韧性,尤其是 TBCCD。从 CLONEGEN 的角度看,DRLSG 策略在对抗 TextLSTM 与 ASTNN 的测试中表现出最佳有效性。
回答 RQ1:由 CLONEGEN 生成的代码对能够有效绕过当前最先进的基于 ML 的克隆检测器的检测,使这些检测器的 在许多场景下从 90%+ 急剧下降到 50%–70%。其中,TextLSTM 尽管效率最高,却最为脆弱(最低 );TBCCD 的鲁棒性最好,但代价是高昂的预处理与训练成本;而 ASTNN 在效率与鲁棒性之间取得了一定平衡(克隆检测只是 ASTNN 支持的众多任务之一)。
6.3 研究问题 RQ2:使用 CLONEGEN 进行对抗式训练(Adversarial Training with CLONEGEN)
本节以实验结果来回答 RQ2:用 CLONEGEN 生成的对抗样本增强基于 ML 的克隆检测器的训练,是否能够抵御 CLONEGEN。
RQ1 的结论揭示了这些 ML 检测器在鲁棒性上的问题。一个常见的思路是“以矛铸盾”,即把 CLONEGEN 产生的代码克隆对转化为对抗样本,用于再训练这些 ML 模型。
众所周知,训练数据显著影响深度学习模型的性能 [19]。一般而言,训练数据越完整,模型表现越好。为此,我们用四种不同策略生成的对抗样本来增强原始数据集 。得到如下训练集:
其中,、、、 是在 上再次应用四种策略得到的新数据集(满足 )。
测试集仍使用 §6.2 中相同的四个集合:。由于随机性,新生成的训练集(如 )与对应的测试集(如 )并不相同。我们在不改动任何模型超参的前提下,对三种 ML 检测器进行再训练。
笔者注:虽然测试集和训练集不同,但本质上都是在上经过变换得到的。这样训练后F1值肯定会升高。
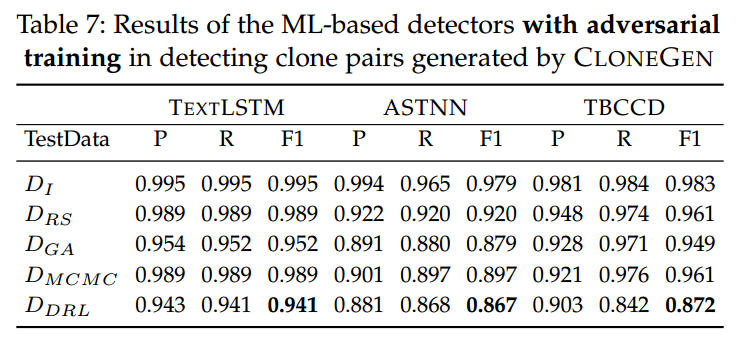
随后,我们重新计算每个检测器在四种变换策略下的 (见表 7)。例如,表 7 中的行 表示保留模型在测试集 上的准确率;与表 4 的 行相比:
- 对 TextLSTM 而言,对抗训练将 从 0.991 提升到 0.995;
- 对 ASTNN,对抗训练带来轻微提升, 从 0.977 升至 0.979;
- 对 TBCCD,新训练使 、 小幅下降至 0.981 与 0.983,而 小幅上升至 0.984。
这些结果是合理的:对抗样本与原始样本差异较大;另外,由于表 4 中的准确率已非常高,对抗训练不可能带来巨幅提升。
就不同策略的绕检效果而言:由 DRLSG 产生的数据集()在表 7 的后四行中始终给出最低的检测准确率——清楚显示 DRLSG 生成的克隆对最难被检测到;其中至少 13% 的样本无法被 ASTNN 与 TBCCD 检出。相对地,RS()是四种策略中最易检测的。GA()与 MCMC()处于中间水平。
就不同 ML 检测器的鲁棒性而言:对抗训练后,这些检测器在捕获多种生成克隆方面的准确率普遍令人满意。如图 5 所示,总体上对抗训练能提升这些 ML 检测器的鲁棒性,其表现为 的普遍上升。更具体地:
- TextLSTM 的 平均提升 0.236,最佳情况在 上提升 0.439;
- ASTNN 的 平均提升 0.266,在 上的最大提升为 0.337;
- TBCCD 的 平均仅提升 0.085,在 上的最大提升为 0.210。
回答 RQ2:使用 CLONEGEN 样本进行对抗训练后,基于 ML 的克隆检测器的 显著提升,说明对抗训练增强了这些检测器的鲁棒性。同时,DRLSG 在生成难以检测的克隆方面表现最佳:在 TextLSTM、ASTNN、TBCCD 三者上,它都能使检测准确率最低,优于其余三种策略。
6.4 研究问题 RQ3:变换算子的有效性(Effectiveness of Transformation Operators)
本节回答 RQ3,即这些原子变换算子本身的有效性。不同于前文“把全部算子一起用”的实验,这里我们分组评估算子。具体地,参考 [26],将算子划为两组:
- 与语义克隆高度相关的一组(Op1–ChRename、Op2–ChFor、Op3–ChWhile、Op4–ChDo、Op5–ChIfElseIF、Op6–ChIF、Op7–ChSwitch、Op8–ChRelation、Op9–ChUnary、Op10–ChIncrement、Op12–ChDefine、Op14–ChExchange);
- 简单混淆(obfuscation) 的一组(Op13–ChAddJunk、Op11–Constant、Op15–ChDelete)。
为探究两类算子对检测器的影响,我们新生成两个克隆数据集:只应用第一组算子的语义克隆数据集 ,以及只应用第二组算子的混淆数据集 。为消除不同启发式策略的副作用,本节不使用上一节的那些策略;我们采用直接的激进方式:对某类算子,将比特向量中对应位全部置 1,从而在所有满足条件的代码位置完整地应用该类算子。

表 8 的“Original”列表示仅用 训练得到的模型;“Adversarial”列表示把对抗样本加入训练集(即 )后得到的模型。表中 行给出在原始数据上的准确率;而 、 行给出在两类算子生成的数据集上的准确率。
总体来看,两类变换对模型准确率的影响都显著:无论“Original”还是“Adversarial”,第二行()与第三行()的 都低于第一行()。在两类变换之间,混淆类(如 )在绕过 TextLSTM、ASTNN、TBCCD 检测方面更占优:其在“Original”与“Adversarial”训练下的平均 分别为 0.742 与 0.945。与此同时,语义克隆类变换 也能显著影响基于 ML 的检测,平均 为 0.877(Original)与 0.962(Adversarial)。因此,实验表明:混淆类算子总体更能影响 ML 检测器的准确率。
回答 RQ3:从实验结果看,两组算子都有效——都能生成能逃逸基于 ML 的克隆检测器的代码对;其中,混淆类变换更为有效,且对 TextLSTM 与 ASTNN 的检测准确率降低更明显。
6.5 研究问题 RQ4:传统检测器 vs. CLONEGEN(Traditional Detectors vs. CLONEGEN)
本节回答 RQ4:传统克隆检测器能否抵御 CLONEGEN?尽管基于 ML 的检测器在性能上可观,但传统检测器仍广泛用于实践。先前研究 [56] 指出:传统检测器 DECKARD 在原始 OJClone 上的召回率很低(0.05),SOURCERERCC 的召回率尚可(0.74)。
为评估 CLONEGEN 生成的克隆代码能在何种程度上绕过传统检测器,我们选取四个开源检测器进行实验:SOURCERERCC [55]、DECKARD [11]、CCALIGNER [10]、NICAD [57]。表 9 给出四种策略下的实验结果;表 10 列出仅检测时间(传统检测器无需预处理或训练,可直接检测)。其中“Processing Number”指并行线程数;我们实际使用 104 线程(与 OJClone 的文件夹数一致)。如果不并行,传统检测器可能需要数天甚至一周才能完成检测。

传统检测器不包含内置 ML 模型;它们通过在源码表示(token [10,55]、text [57]、tree [11]、依赖图 [12] 等)上识别可疑模式来检测克隆。我们把它们视作黑盒:输入 CLONEGEN 生成的代码对,让其输出“克隆/非克隆”,最后统计总体召回率。
总体结果:CLONEGEN 使大多数传统检测器的召回率极低;在 上平均 0.049。并且,DRLSG 对传统检测器的打击最强(比其他策略更有效),因为其产生的代码改动更多、语法差异更大——这意味着在 DRLSG 下,CLONEGEN 能以超过 90% 的成功率快速生成可绕过这些检测器的代码对。我们重点观察召回率 < 0.10 的检测器:
- SOURCERERCC(基于 token)最低,recall = 0.001,极易被击败;
- NICAD 通过格式化、美化与规范化实现“意图克隆”的精确检测,其召回率第二低 0.026;
- CCALIGNER 结合滑动窗口与哈希,面向大间隔克隆,其 recall = 0.07;
- DECKARD(基于树的特征向量)在四者中最高,也仅 0.099。
回答 RQ4:传统克隆检测器对 CLONEGEN 生成的代码对几乎没有抵抗力,尤其是对 数据集。即便是通常被认为比 token 基方法更鲁棒的树基检测器(如 DECKARD),其在 CLONEGEN 生成的数据集上的召回率也不足 10%。
7 讨论(Discussion)
7.1 可信性威胁(Threats to Validity)
内部效度 的威胁主要来自本文中使用的传统检测器与基于 ML 的检测器的参数设置。为减轻此问题:对传统检测器我们采用默认配置;传统检测器通常可调参数很少,结果也相对稳定。对基于 ML 的检测器,我们使用其论文 [16], [17] 中公开报告的参数,并对未公开的部分进行小幅微调,最终使我们训练的模型能够复现对应论文中报告的相近结果。通过这一严格过程,我们认为本文方法与所有基线检测器之间的比较是公平的。
外部效度 的威胁主要来自两方面。其一,我们只使用 OJClone 的 C 语言数据集进行评测。该数据集是一个大规模语义克隆的开源基准。目前我们的评估仅覆盖 C/C++,但考虑到其它高级语言(如 Java)在语言特性(如面向对象)上与 C/C++ 有相似之处,我们相信本文结论能够推广到其它高级语言的克隆检测。其二,受工具可用性限制,本文只评估了三种基于 ML 的检测器。未来,当更多检测器开源可用(如 [50], [51]),我们希望扩展到更多 ML 检测器,乃至代码抄袭检测工具(如 Moss [58])。
7.2 变换算子的影响(Impact of Transformation Operators)

如表 11 所示,我们分析了 15 个提出的变换算子对四类常用源码表示的影响。我们将影响分为三个级别:
- 严重影响:算子破坏了原有表示的结构;
- 轻微影响:只改变表示的结点属性(例如在 AST/CFG 中仅改变某个结点的属性);
- 无影响:表示的属性与结构均不改变。
基于 token 的检测器几乎对所有算子带来的改变都敏感,只有 Op1(重命名标识符) 与 Op14(交换语句) 影响较小。因此,token-based 检测器通常只能检测 Type-I/II 克隆,我们的算子可以轻松规避这类检测器(如 SOURCERERCC [55]、CCALIGNER [10]、CCFINDERX [59])。
基于 AST 的检测器(如 DECKARD [11])总体上优于 token-based,但 AST 结构对控制流/数据流层面的改变并不稳健,例如 Op2–Op14 引入的变更。因此,AST-based 检测器擅长 Type-I/II,但仍可能被我们的算子绕过。与之相对,基于 CFG/PDG 的检测器(如 CCGRAPH [12])对控制流/数据流变化更为鲁棒;尤其对 CFG-based 检测器而言,它们对 Op8–Op11 的变换(例如 while ↔ for 的改写)更不敏感。不过,Op4、Op7、Op12、Op13 会对四类表示都产生严重影响,因为这些算子对应的变换属于 Type-IV(语义克隆) 的层面。
7.3 轻量级代码变换还是混淆器?(Lightweight Code Transformation or Obfuscators?)
在本研究中,我们采用变换算子与策略并实现了框架 CLONEGEN,以执行轻量级且保持语义的代码变换。其实,现有的软件代码混淆器 [27], [34], [60], [61], [62] 也能对源代码施加等价变换。但我们没有直接使用这些混淆器,主要有三点原因:
绕过克隆检测本质上是一个在变换代价与逃逸收益之间权衡的折衷问题。混淆器通常非免费,而且耗时相对较高。为此,我们提供一种轻量但有效的代码变换方法。
混淆通常用于知识产权(IP)保护。因此,经过混淆后的代码往往可读性与可维护性较差。例如,原始代码
int i = 1;经由文献 [62] 的混淆器编码后,可能变为:
int o_8ffc9af5e5913588bc0b7705602caf02=
(0x0000000000000002 + 0x0000000000000201 +
0x0000000000000081 - 0x00000000000000A03);- 更重要的是,小而简单的变换相较于复杂变换更便于算法开发者分析与调试鲁棒性问题。因此,简单而有效的变换通常更有利于算法开发与研究。
8. 相关工作
8.1 Code Clone Detection
通常,现有的克隆检测器可分为基于文本、基于token、基于结构的代码克隆检测方法。基于文本的方法[9]、[57]、[63]以字符串的形式表示代码片段。如果两个代码片段的文本内容相似,则将其视为克隆。[4]、[10]、[18]、[55]、[59]中描述的方法将源代码表示为一系列token序列,并在token序列上使用不同的相似性检测算法来检测代码克隆。[11]、[16]、[64]、[65]中描述的方法通过提取代码的语法来获得代码的语义特征,从而检测代码相似性。
最近,一些方法[6]、[51]、[66]通过提取语义代码特征来执行代码克隆检测,例如使用混合特征,如程序的CFG和AST[15]、[67]、[68],或通过基于学习的方法[15]、[16]、[17]、[18]、[49]、[51],[65]、[67][69]、[70]。关于克隆检测器的评估,BigCloneBench[71]提供了一个克隆检测基准来评估克隆检测器,现有的研究[13]、[23]、[72]、[73]、[74]、[75]侧重于在某些方面评估传统检测器,仍然缺乏系统地挑战和评估最新基于机器学习的克隆检测器鲁棒性的研究。
8.2 Code Mutation
代码突变经常用于代码测试。突变测试,生成大量突变体,这些突变体会自动嵌入代码中,以执行目标程序来检测其错误[76]、[77]、[78]、[79]。突变测试也可用于测试代码克隆检测器的有效性。Roy等人[57]识别并标准化了潜在克隆,然后使用动态聚类对潜在克隆进行简单的文本行比较。Roy等人[31]提出了一种突变插入方法来测试代码克隆。这个想法是将一段人工代码重新插入到一段源代码中,这样就可以人为伪造不同类型的代码克隆对,然后用目标克隆检测器进行测试。他们提出的工具是对代码进行随机转换,这可能会改变原始代码的语义。
Svajlenko等人[80]提出了一种基于突变分析的基准框架,该框架评估了不同类型克隆的克隆检测工具的召回率,并且特定类型克隆的编辑不需要人为干预。与可以转换代码但不能保证语义保留的方法[31]、[80]不同,我们的方法总是生成语义等效的克隆以进行鲁棒性验证。最近,Zhang等人[54]只使用了这项工作中包含的一个转换运算符(重命名变量)来证明一些源代码处理方法(例如,ASTNN和基于Token的LSTM模型)在代码分类问题中并不可靠。在本文中,我们的方法证明了基于ML的克隆检测器在检测简单但有效的等效转换后的代码克隆方面不够健全。
8.3 Code Obfuscation
等价变换也常用于代码混淆。程序混淆是一组保持语义的程序变异技术。它主要用于隐藏程序的意图或在软件发布前保护其知识产权。Liu等人[34]提出了一种基于语言模型的混淆框架。它使JSNice[81]等代码重构工具更难重构程序。Breanna等人[35]提出了MOSSAD,这是一种通过插入垃圾代码来制作代码抄袭工具的方法,可以有效地击败MOSS等盗窃检测器[58]。
Schulze等人[82]提出应用代码混淆来评估一些传统克隆检测器的鲁棒性。他们半自动地对源代码应用了一些代码混淆,没有考虑指导代码突变的策略。我们工作的目标是进行简单而有效的转换,以生成语义克隆,从而避开基于学习和传统的克隆检测器。我们的轻量级方法使开发人员更容易在克隆检测器中快速发现和定位鲁棒性问题,而不是应用繁重的权重转换(编码[62]、CFG扁平化[27]或其他编译器优化[36])
9. Conclusion
本文介绍了CLONEGEN,这是一个轻量级但有效的代码转换框架,可以通过自动生成克隆对来评估基于机器学习的克隆检测器的鲁棒性。几种最先进的基于ML的和传统的克隆检测器。实验结果表明,我们的轻量级变换在评估克隆检测器的鲁棒性方面是有效的,并且可以显著降低三种最新的基于ML的检测器的性能,即ASTNN、TBCCD、TEXTLSTM。我们的研究揭示了基于机器学习的克隆检测器的鲁棒性,这需要更稳健和有效的数据收集和模型训练方法。一种可能的解决方案是设计一种混合源代码表示,以提高现有基于机器学习的检测器的能力。我们的源代码和实验数据在https://github.com/CloneGen/CLONEGEN.