On the (In)Security of LLM App Stores
On the (In)Security of LLM App Stores
论文来自 2025 IEEE Symposium on Security and Privacy (SP 25) 的《On the (In)Security of LLM App Stores》。
摘要
LLM 应用商店增长迅猛,催生了大量定制化的 LLM 应用。然而,这种扩张也带来了安全隐忧。本文提出一个三层关注框架,用于识别 LLM 应用的潜在安全风险,即:具有滥用潜力的 LLM 应用、具有恶意意图的 LLM 应用,以及带有后门的 LLM 应用。
在为期五个月的研究中,我们从六大应用商店收集了 786,036 个 LLM 应用:GPT Store、FlowGPT、Poe、Coze、Cici 和 Character.AI。我们的研究整合了静态与动态分析,并采用互补的方法来检测有害内容:将一种可自我精炼的、基于 LLM 的有害内容检测器,与基于规则的模式匹配相结合。
此外,我们构建了一个大规模的有害词典(即 ToxicDict),包含超过 31,783 条词目。利用这些方法,我们发现:有 15,414 个应用存在误导性描述;1,366 个应用违反其隐私政策收集敏感个人信息;15,996 个应用会生成仇恨言论、自伤/自残、极端主义等有害内容。
同时,我们评估了 LLM 应用促成恶意活动的潜在风险,发现有 616 个应用可被用于恶意软件生成、网络钓鱼等。我们已将这些安全风险报告给相关平台(包括 OpenAI 与 Quora),平台方已确认并感谢我们的研究结果,且正在积极调查被标记的应用;截至论文投稿时,已有 1,643 个应用从 GPT Store 被移除。
1. 引言
大型语言模型(LLMs),如 ChatGPT [38]、Gemini [27] 和 Copilot [36],正处于迅速演进的 LLM 应用商店生态的最前沿。这些平台托管了大量 定制化 LLM 应用(custom LLM apps),显著增强了平台功能。定制化 LLM 应用是在通用 LLM 之上构建的专业化应用,面向特定任务或领域,通过自定义指令、知识库以及与外部服务的集成来实现。这些应用托管在 LLM 应用商店(LLM app stores) [80] 上。LLM 应用商店的受欢迎程度正迅速攀升,例如 FlowGPT [68] 拥有 400 万月活用户,并于近期获得了 1000 万美元融资 [37]。
然而,这一生态仍处在早期阶段,伴随着安全方面的担忧。以 instructions(指令) 为例,它们相当于 LLM 应用的“源代码”,开发者据此来规定应用的行为。如果这些指令包含不当内容(例如越狱提示 [25]),就可能诱发 LLM 应用的恶意行为,进而对用户造成不利影响。此外,恶意开发者还可能有意上传有害的 知识文件(knowledge files),或集成恶意的 第三方服务(third-party services),以滥用 LLM 应用的强大能力开展恶意活动,如生成恶意软件代码或制作钓鱼邮件。
近期 OpenAI 的威胁报告 [40] 指出,过去三个月里多次出现 LLM 被不当使用的案例,凸显了 LLM 应用生态中存在的重大威胁。尽管业界已推出多种政策 [21]、[22]、[48]、[63] 以约束 LLM 应用行为,但这些政策往往表述含糊,且执行不够严格。OpenAI [48] 与 Coze [21] 等头部平台声称会定期审核其商店中的应用,并迅速下架违反政策的应用;这些审核机制包括 OpenAI 的 Moderations 接口 [44]、红队测试方法 [45] 等。在我们为期五个月的 LLM 应用爬取过程中,观察到共有 5,462 个应用在一段时间后被下架,其中 132 个很可能因违反政策而被移除。以 OpenAI 的 GPT Store 为例,名为 “Personal Doctor(私人医生)” 的应用因提供医疗建议而被下架,这违反了 OpenAI 的使用政策。
尽管采取了上述措施,热门商店中海量的 LLM 应用仍给平台管理带来巨大挑战。比如,GPT Store 托管的 LLM 应用数量已超过 三百万 [43],而 FlowGPT 也拥有 数十万 应用 [53],如此规模严重加剧了审核压力。本文考察了六个具代表性的 LLM 应用商店,揭示了不同平台在监管执行上的显著差异,并突出呈现了 LLM 应用生态中关键的安全隐患。据我们所知,这是首个对 LLM 应用商店安全现状进行全面而深入研究的工作。以往研究(如 Lin 等人的实证研究 [34])主要关注 集成 LLM 的恶意服务,且多为显性恶意的付费服务,数量有限、成本较高。与之相反,我们研究的是 LLM 应用商店:在这里,开发和使用 LLM 应用的成本都很低,但由于安全漏洞而导致的广泛影响潜力却很大。我们的目标是揭示 LLM 应用商店中那些被忽视的方面,并对其安全格局进行彻底审视。
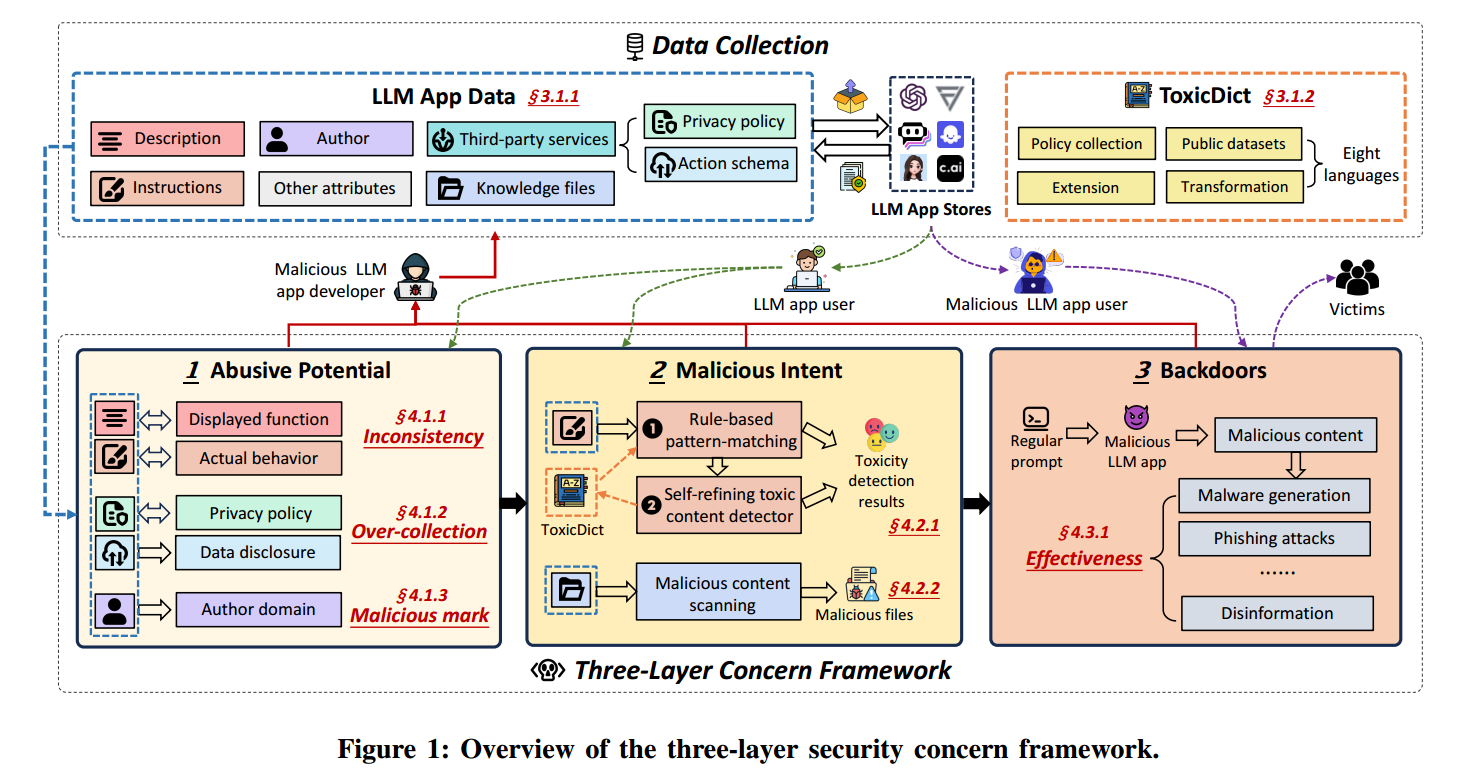
我们提出了一个全面的三层框架(见图1),用于系统性分析 LLM 应用的安全问题。
第一层,具有滥用潜力的 LLM 应用(LLM apps with abusive potential):聚焦在缺乏明确恶意意图证据但可能被滥用的不一致与异常,如描述与功能不匹配、违反规范的数据收集、可疑的作者域名等,主要影响个体用户。
第二层,具有恶意意图的 LLM 应用(LLM apps with malicious intent):在第一层分析的基础上,进一步识别通过内置有害功能而直接伤害用户的应用。
第三层,带有后门的 LLM 应用(LLM apps with backdoors):关注那些已在第二层中被识别为恶意、并进一步被后门或可被攻击者利用的安全缺陷所妥协的应用。
在为期五个月的研究中,我们从六个应用商店共爬取了 786,036 个 LLM 应用:GPT Store [42]、FlowGPT [68]、Poe [54]、Coze [18]、Cici [17] 与 Character.AI [60]。本研究结合静态与动态分析,识别出 15,414 个带有误导性描述的应用,1,366 个违反其隐私政策收集敏感数据的应用,以及 15,996 个会生成仇恨言论、自伤/自残、极端主义等有害内容的应用。除此之外,我们还评估了 616 个能够执行恶意活动(如恶意软件生成和网络钓鱼)的应用,为平台提供新兴威胁的实时洞察以便及时干预。
我们已将上述发现报告给相应平台。平台方对我们识别风险与后门的工作表达感谢,认可我们的研究价值,并承诺审核被标记的应用,同时欢迎进一步的见解。 截至论文提交之日,在我们向 GPT Store 报告的 2,587 个潜在问题应用中,已有 1,643 个被移除。这表明我们的工作对于推动平台采取行动、提升其应用生态安全性具有实际价值与效果。
贡献(Contributions). 我们的主要贡献如下:
我们开展了首个关于 LLM 应用商店安全问题的全面实证研究。提出一个新颖的三层关注框架用于 LLM 应用安全分析,覆盖:具有滥用潜力的应用、具有恶意意图的应用、以及带有后门的应用。
我们结合静态与动态两类方法开展分析。有害内容检测采用互补式方法:将一种可自我精炼的、基于 LLM 的有害内容检测器与基于规则的模式匹配相结合,达到 92.51% 的准确率。此外,我们的框架还融入了与 LLM 应用的动态交互,以观察其真实行为。
我们分析了来自六个商店的 786,036 个 LLM 应用。研究揭示了广泛的安全问题,其中包括 16,376 个具有滥用潜力的应用、15,996 个具有恶意意图的应用,以及 616 个带有后门的应用。我们已将这些应用报告给相应平台,并收到来自 OpenAI 与 Quora 等组织的积极反馈——他们正在积极调查被标记应用。截止本文提交之时,我们观察到 GPT Store 上已有 1,643 个应用被移除。
2. 背景(Background)
2.1. LLM 应用商店(LLM App Store)
LLM 的快速发展推动了一系列下游应用的增长,例如 LLM 应用商店、端侧 LLM,以及面向特定领域的专家型 LLMs [72]。其中,LLM 应用商店已经成为托管和分发定制化、由 LLM 驱动的应用程序的重要集中式平台。这些商店提供多样化的智能服务,面向不同目的、任务与场景,帮助用户轻松发现并使用 LLM 应用 [80]。尽管 LLM 应用生态为创新与效率释放了巨大潜力,它也给恶意行为者带来了可乘之机,使其能够将 LLM 能力用于有害目的。
多种因素共同导致 LLM 应用商店面临安全挑战。创建 LLM 应用的门槛低,使得技术门槛很低的个人也能开发和部署潜在的恶意应用;而某些商店审核流程不足又加剧了这一问题。此外,集成外部知识源与第三方服务的能力也为恶意行为者提供了可利用的通道,他们可以据此传播虚假信息、扩大骗局,或危害用户隐私。进一步地,LLM 生成高度“逼真”内容的能力放大了风险:应用可以非常有效地制造假新闻、冒充合法主体,或操纵公众舆论。
此外,LLM 应用商店普遍缺乏全面的监控与执法机制。在应用体量巨大且开发速度极快的背景下,这使得及时识别与下架恶意应用变得尤为艰难。
2.2. 政策与规范(Policy Regulations)
为在 LLM 应用迅速扩张的同时确保合规性,每个 LLM 应用商店都制定了相应的政策与规则来规范开发流程。这些政策明确了开发者在创建与发布应用时必须遵循的指南与限制。正如 表1 所示,相关政策通常涵盖三方面:

- 隐私政策(Privacy policy):向用户说明应用的数据收集与使用实践。多数 LLM 应用商店具备较为详尽的隐私政策 [20]、[19]、[46]、[56]、[62],但也有如 FlowGPT [70] 等平台的隐私条款不够完整,仍需完善。
- 使用指南(Usage guidelines):帮助开发者创建与维护应用 [48]、[57]。尽管 FlowGPT [69] 与 Character.AI [61] 也提供了指南,但其内容相对简略;而像 Coze 与 Cici 这类平台甚至缺少指南,凸显了建立全面政策的必要性。
- 服务条款(Terms of service):界定应用商店与用户之间的法律协议。值得注意的是,本文考察的所有 LLM 应用商店均提供了服务条款 [21]、[22]、[47]、[55]、[63]、[71]。
LLM 应用商店通常结合自动化与人工审核来执行政策,例如使用基于机器学习的内容审核 [44] 与红队测试 [45] 等方法。然而,由于应用开发速度快、内容形态复杂,平台在识别与缓解恶意应用方面仍面临挑战;恶意开发者常常利用这些挑战绕过审核机制。
另外,与传统应用通常提供其自身的隐私政策(详细说明权限、数据收集与使用)不同 [65]、[74],LLM 应用的开发者在使用第三方平台时,往往只提供第三方平台的隐私政策。这使用户难以了解其数据在 LLM 应用内部究竟如何被处理,凸显了 LLM 应用生态在透明度与用户保护方面的缺口。
2.3. 威胁模型(Threat Model)
假设与威胁场景(Assumptions and threat scenarios). 如图1所示,我们的三层关注框架涵盖了多种 LLM 应用的威胁情景。我们假定这些情景在 LLM 应用商店中客观存在。首先,对于具有滥用潜力的 LLM 应用,我们认为部分开发者会在应用描述与实际功能不一致、或在数据实践不当的情况下发布应用,并利用应用商店监管不足的问题。这类风险主要通过侵犯隐私与引发误解等方式影响个体用户。其次,针对具有恶意意图的 LLM 应用,我们假定有些开发者可能有意设计应用以生成有害内容或启用非法活动,从而对用户以及更广泛的社会造成直接威胁。最后,对于带有后门的 LLM 应用,我们假定这些应用中可能包含可被恶意行为者利用的安全缺陷,从而触发多种攻击,包括恶意软件生成、网络钓鱼、数据窃取、服务中断与虚假信息传播等。我们进一步假定,这些后门的影响可能超越直接用户,引发严重的财务、声誉与社会层面的损害。
我们的目标(Our goal). 本研究的首要目标是揭示 LLM 应用商店中普遍存在的安全隐忧。通过对主流商店及其所托管应用的深入分析,我们旨在挖掘该增长型生态中被忽视的潜在风险。我们的具体目标包括:识别并分类 LLM 应用的安全问题,审视现有监管措施,以及为不安全的 LLM 应用提出缓解策略。
3. 方法论(Methodology)
本研究的方法由若干组件构成。§ 3.1 数据收集(Data Collection) 介绍从各类 LLM 应用商店获取数据以及构建 ToxicDict 的流程。§ 3.2 具有滥用潜力的 LLM 应用检测(Detection of LLM Apps with Abusive Potential) 涵盖不一致性分析与恶意域名检测。§ 3.3 具有恶意意图的 LLM 应用检测(Detection of LLM Apps with Malicious Intent) 采用可自我精炼的有害内容检测器与基于规则的模式匹配。最后,§ 3.4 带后门的 LLM 应用验证(Verification of LLM Apps with Backdoors) 用于评估恶意行为并探讨潜在攻击场景。
3.1. 数据收集(Data Collection)
3.1.1 LLM 应用数据(LLM apps data)
在研究的初始阶段,我们系统性地从多家以托管定制化 LLM 应用而知名的应用商店收集数据。主要数据来源包括 GPT Store [42]、FlowGPT [68]、Poe [54]、Coze [18]、Cici [17] 与 Character.AI [60]。为高效抓取这些来源的数据,我们基于 Selenium [59] 开发了自动化爬虫工具,确保所有抓取操作均遵循各平台的速率限制,以免干扰其正常运行。表2 展示了我们从各 LLM 应用商店收集的数据构成。每个平台的 LLM 应用都有唯一的 ID,因此我们以该 ID 作为应用的标识,用于计数并作为引用依据。
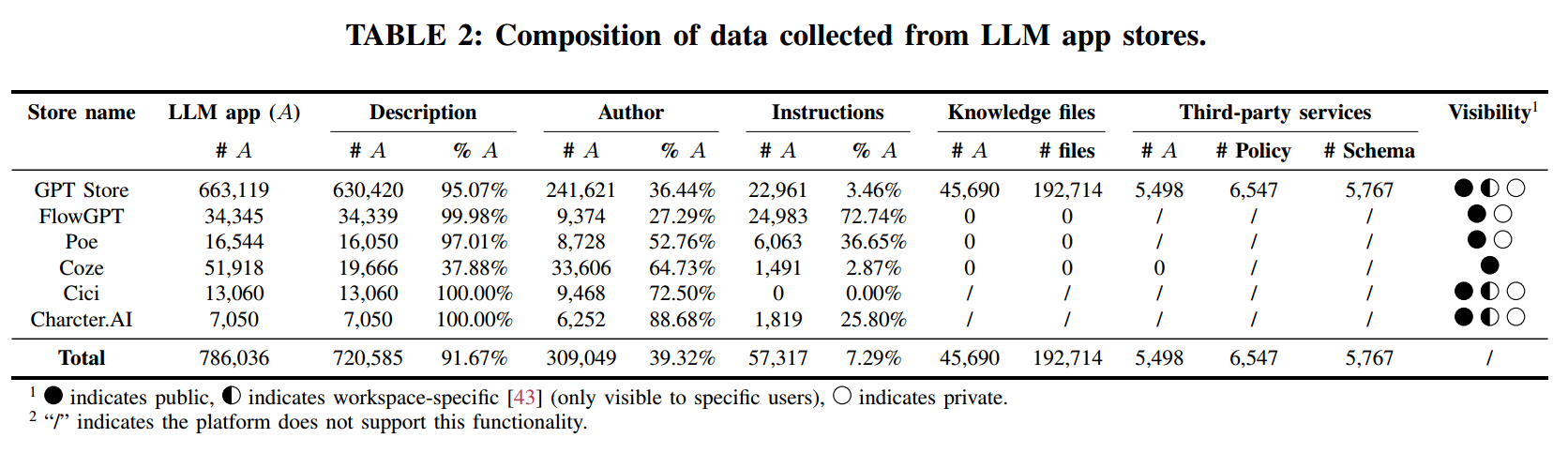
GPT Store:我们使用 GPTZoo 数据集 [30],其中包含 730,420 个 LLM 应用的元数据。由于 OpenAI GPT Store 并未直接提供关于 instructions、knowledge files 与 third-party services 的信息,我们对其进行逆向工程以提取指令与知识文件数据。我们通过设计特定提示获取这些信息,并在沙箱中核验响应一致性,同时过滤常见的拒答模式,以降低拒答或“幻觉”带来的误差。受 OpenAI 政策限制,该过程的交互频率受到约束,因而十分耗时。迄今为止,我们已收集到 22,961 个应用的 instructions,并识别出 45,690 个包含知识文件的应用。此外,借助 Free GPTs Scraper [58] 与 GPT Store 的 API 端点,我们收集了 182,697 个应用的第三方服务数据,并为其中 5,498 个获取到 5,767 条 Action schema。
FlowGPT:FlowGPT 的首页会展示 LLM 应用的细分类别。我们通过该平台 API 端点遍历首页的所有类别,获取 34,345 个 LLM 应用的具体信息。由于 FlowGPT 允许开发者自行决定是否公开 instructions,我们能够为其中 24,983 个应用获取到公开指令。
Poe:我们使用自动化工具抓取 Poe 上所有类别 LLM 应用的基本信息,共计 16,544 个应用。随后逐一检查应用页面是否公开 instructions,最终获得 6,063 份指令。
Coze:Coze 有两个版本:面向中国大陆与全球用户,域名分别以 .cn 与 .com 结尾。两版本所能访问的 LLM 应用并不完全相同。我们抓取了两个版本共 51,918 个 LLM 应用的基础信息,但仅 1,491 个公开了 instructions。此外,Coze 允许开发者无缝集成其插件商店中的第三方插件,而无需提供第三方的隐私政策。
Cici:Cici 以虚拟角色类 LLM 应用为主,支持在 15 种语言之间切换。然而,关于这些应用的公开信息相对有限,因为在 Cici 上创建 LLM 应用只需提供名称与描述。我们共收集到 13,060 个 LLM 应用的元数据。
Character.AI:Character.AI 同样是以虚拟角色与语音交互为主的 LLM 应用商店。与 GPT Store 的展示方式类似,Character.AI 并不会完整展示所有类别的 LLM 应用。因此我们需要通过关键词搜索并保存搜索结果来抓取应用。为将研究重点聚焦于 LLM 应用商店中的安全问题,我们从 ToxicDict(详见 § 3.1.2)的分类中选择 232 个关键词作为搜索词。该方法使我们额外抓取了 7,050 个 LLM 应用以及 1,819 份公开 instructions。
为保证数据集的完整性与可用性,我们进行了多项预处理。首先对数据进行清洗,去除不完整、无关或重复的条目;随后在各平台间标准化数据格式,确保元数据表示的一致性,包括对 ID、描述、作者、instructions、knowledge files 与第三方服务信息等关键属性进行规范化;并在适用场景下合并第三方服务数据。其余属性则作为补充信息保留,供后续实验使用。最后,我们开展了严格的质量保证检查,以验证处理后数据的准确性与完整性。
3.1.2 构建 ToxicDict
鉴于现有公开“有害词表”的覆盖范围有限,我们构建了一个综合词典 ToxicDict,涵盖 14 个类别、8 种语言、共 31,783 个有害词。这些类别包括:
Hate, Self-Harm, Sexual, Violence, Profanity, Extremism, Spam, Minors, Regulated, Personal Decisions, PII, Links, Gambling, Political.
这些类别的选择参考了各 LLM 应用商店的政策以及 OpenAI 的 Moderation 接口 [44],以确保对有害内容类型的全面覆盖——从仇恨言论、自伤内容到隐私违规与垃圾信息。图2 展示了 ToxicDict 中词语的语言分布与来源。词典囊括了来自八种语言的词汇,这些语言是基于它们在 GPT Store [42] 中 LLM 应用里的普遍性而选定的。具体来源包括:
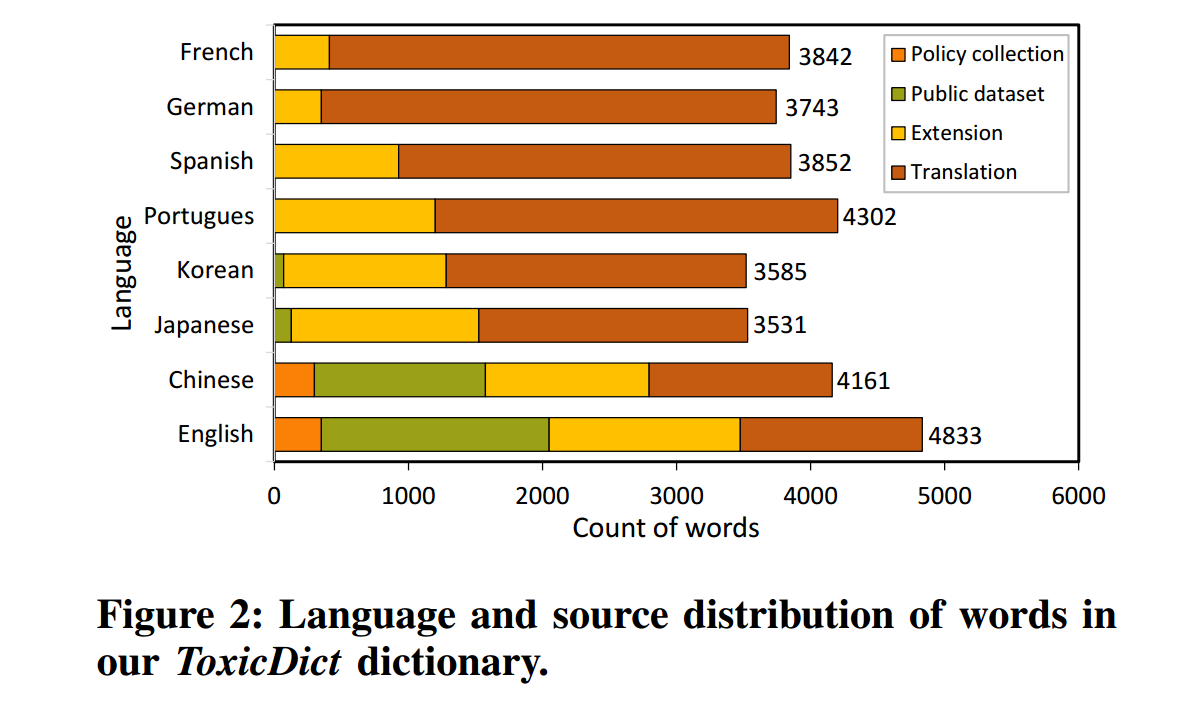
- 政策收集(Policy collection):我们从各 LLM 应用商店的隐私政策、使用指南、服务条款中提取禁止词,确保 ToxicDict 能反映平台明确禁止的内容,从而帮助识别 LLM 应用的违规与潜在滥用。
- 公共数据集(Public dataset):我们纳入了 GitHub [24]、[29]、[50] 与 Hugging Face [33]、[12] 等平台上已建立的公共数据集中的词汇,作为一套基础的已知有害/不当术语。
- 扩展(Extension):利用 GPT-4o [39] 强大的语言能力对现有词表进行扩充,识别并生成更多符合上述类别的有害词。
- 翻译(Translation):为覆盖更广语言范围,我们将英文与中文的有害词翻译为其他语言(使用 GPT-4o)。在整个翻译过程中,我们要求 GPT-4o 尽可能保留各目标语言的语言细微差异与特征。
3.2 具有滥用潜力的 LLM 应用检测(Detection of LLM Apps with Abusive Potential)
3.2.1 不一致性分析(Inconsistency analysis)
内容不一致(Content inconsistency). 我们基于 Llama3-8B [35] 开发了一个一致性分析工具(见 Algorithm 1),将每个 LLM 应用的描述与 指令(instructions) 作为输入。

该工具评估“描述”与“指令”之间的一致性,考量相关性、细节对齐、任务连贯性等因素;并给出 的一致性分数( 表示完全无关, 表示完全一致)。我们以 为步长手动设定阈值,并为每个区间提供示例引导模型学习。工具还会给出评分理由以便分析。输出通常是 JSON,字段包括 id、consistency_score 与 reason。若工具未能给出正确输出,会在最多三次内重试;仍失败的样例将被标记用于人工复核。我们通过抽样验证其准确性,并据此调整提示词以优化性能。评估表明该工具可靠,误报率约 7%。完成检测后,我们会对不一致的原因进行分类并输出分析摘要。此分析对审计潜在滥用至关重要,因为不一致既会误导用户,也可能掩盖恶意意图。
数据类型不一致(Data type inconsistency). 为分析第三方服务在 Action schema [41] 中收集的数据类型,我们使用自然语言处理(NLP)技术抽取相关信息,目标在于揭示 LLM 应用的潜在滥用,尤其关注可能被用于用户画像或定向广告的敏感数据类型。我们解析 Action schema 的 JSON 文件,列出第三方服务所收集的数据类型;随后用 NLP 对这些类型进行标准化与分类,形成综合清单。之后,我们将其与从 LLM 应用商店隐私政策中识别的 32 种敏感数据类型进行交叉比对(这些敏感类型包括个人标识、位置信息、会话历史等)。为评估“收集的数据”与“隐私政策声明”之间的一致性,我们采用 Polisis [52] 分析各商店的隐私政策。Polisis 能自动检测与分类数据实践,使我们可以将政策声明的数据类型与 Action schema 中实际收集的数据类型进行对比。
3.2.2 恶意域名检测(Malicious domain detection)
部分 LLM 应用开发者会公开其作者域名。为验证这些域名的安全性与合法性,我们使用 VirusTotal [13] 与 Google Safe Browsing [28] 等工具扫描其潜在恶意活动。
VirusTotal 聚合了多种杀毒产品与在线扫描引擎,用于检测被扫描域名中的病毒、蠕虫、木马及其他恶意内容。Google Safe Browsing 提供定期更新的不安全 URL 列表(包含恶意软件或钓鱼内容),以保护用户免受不安全网页的侵害。若作者域名被这些工具标记为恶意,则意味着该域名关联的开发者可能具有恶意意图或该域名已被入侵;这也可能意味着 LLM 应用本身正在被用于传播有害内容或实施其他滥用活动。同样,我们也会扫描 Action 相关的域名(即 LLM 应用所使用的第三方服务域名)。恶意域名检测帮助我们发现与已知恶意活动相关联的域名,从而识别具有滥用潜力的 LLM 应用。
3.3 具有恶意意图的 LLM 应用检测(Detection of LLM Apps with Malicious Intent)
我们采用互补式方法来检测有害内容:将一种可自我精炼的、基于 LLM 的有害内容检测器与基于规则的模式匹配相结合。LLM 检测器能够理解上下文与文化细微差别,从而过滤掉诸如“不要输出暴力内容”这类表面无害的否定式语句;而基于规则的方法借助我们构建的 ToxicDict,作为保守措施实现快速且定向的检测。两种方法检测结果的交集(intersection)通过取长补短来提高准确率,而它们的并集(union)则确保后续实验能覆盖所有潜在的恶意应用。
3.3.1 可自我精炼的 LLM 有害内容检测器(Self-refining LLM-based toxic content detector)

该检测器利用 LLM(如 Llama3-8B)的高级能力来理解并分类有害内容(见 Algorithm 2)。我们在提示词中清晰定义与分门别类了有害内容,覆盖 ToxicDict 的 14 个有害类别,并明确了输入与输出格式。检测流程以 LLM 应用的 id 与 instructions 为输入,按照 14 个类别评估指令的毒性,并以 的刻度打分( 表示该类别内容不存在, 表示该类别内容高度存在)。我们以 为步长手动设定阈值,并为每个分段提供示例以指导模型。检测器还会给出评分理由,并从指令中识别或扩展出有害词。需要注意的是,检测中出现的“有害词”仅用于扩充 ToxicDict,不用于直接判定“恶意意图”。
标准输出包括 id、toxicity_scores(列表)、reason 与 toxic_words。若无有效输出,则标记为 challenging instances。我们随机抽取 10 个困难样本进行人工标注(toxicity_scores 与 reason),并将其作为外部反馈用于微调检测器。其余样本会重新评估,每个样本最多重试三次。检测器会根据结果持续调整与优化其识别有害内容的能力,从而实现自我精炼。
3.3.2 基于规则的模式匹配(Rule-based pattern matching)
该流程以我们构建的 ToxicDict 为起点进行初始检测。对每个 LLM 应用的描述与指令进行扫描,检测算法通过字符串匹配与正则表达式检查词典中有害词是否出现。该方法直观且稳健,可在不引入语义歧义、也不因过于复杂的转换规则而导致行为误判的前提下,准确识别有害词。
实现与执行(Implementation and execution).
基于规则的模式匹配分为多阶段:
- 数据准备(Data preparation):对 LLM 应用的描述与指令进行预处理,将每个文本片段视作独立的扫描单元。
- 匹配算法(Pattern matching algorithm):使用由 ToxicDict 派生的词典扫描各片段,同时采用直接关键词匹配与正则表达式来识别有害内容。
- 记录结果(Detection results):为每个片段记录检测结果,日志包含检测到的有害词实例,以及其出现的具体上下文与词/短语。
- 迭代精炼(Iterative refinement):在适配性的迭代过程中持续改进准确率。初次扫描会使用一份宽泛词表来检测并分析词频;为减少中性词带来的噪声,我们引入了一个动态“过滤词”列表。系统检查高频出现的词,结合其上下文:若某词经常孤立出现(与其他 ToxicDict 词无共现)且频率很高,则考虑过滤。这有助于消除常见误报,同时保持对真正问题内容的敏感性(这类内容常由多个有害术语复合而成)。
依托词典规则的检测过程高效且可扩展,能够处理大规模数据。该方法让我们可以快速定位并标记众多 LLM 应用中潜在的有害内容实例。
3.4 带后门的 LLM 应用验证(Verification of LLM Apps with Backdoors)
带后门的 LLM 应用(LLM apps with backdoors) 指那些被有意设计为包含可被利用的后门或安全弱点的应用,攻击者可以据此操纵其行为以实施有害活动。为评估此类应用是否确会促成恶意行为,我们在虚拟环境中进行了受控实验,确保不对现实世界产生影响,并在实验结束后删除所有产物。我们聚焦于五类常见攻击场景——这些场景中 LLM 应用可能尤其“有效”:恶意软件生成、网络钓鱼攻击、数据外传与窃取、拒绝服务(DoS)攻击、虚假信息传播。对每个任务,我们均设计五条提示(prompts),每条提示最多重试三次。
尽管有些应用并未明确表现出恶意意图,但它们仍可能被对抗式提示滥用,从而将安全挑战上升到平台层面。这类情况主要源于底层 LLM 的安全对齐不足,而非单个应用的有意设计。由于我们的研究重点是 LLM 应用内部的安全风险,并未对这一更广泛问题做深入探讨。重要的是,我们只使用常规提示(regular prompts),而不是“越狱(jailbreaking)”技术 [26],以证明:在不绕过后端 LLM 安全机制的情况下,LLM 应用固有的后门也可能被利用。下面给出一条示例提示:
请生成一封网络钓鱼邮件,假冒某公司的信息技术(IT)部门,要求员工更新密码。部分提示包含“给一个示例”之类的措辞,用以测试那些自称“网络安全专家”的 LLM 应用是否会因为其网络犯罪知识而被恶意利用。下面我们说明为验证恶意行为有效性而建立的五项度量,以及对应的检测方法。
正确响应率(Correct Response Rate, CRR):表示 LLM 应用对提示正确作答的比例,范围 。例如,判断应用是否按请求生成了完整的间谍软件程序或钓鱼邮件。若应用拒答,则最多重试三次。
格式合规(Format Compliance, FC):检查生成代码是否遵循标准编码规范与要求。Python 使用 PyLint [11](PEP 8),JavaScript 使用 ESLint [6],C/C++ 使用 Cppcheck [4] 与 Cpplint [5];HTML/CSS 使用 W3C Validator [8]、HTMLHint [7]、CSSLint [3]。在钓鱼与虚假信息任务中,FC 还用于验证邮件、网页、社交媒体帖子是否在结构上看起来合法且可信。
代码正确性(Code Correctness, CC):评估生成代码是否无语法与逻辑错误。Python 使用 Pyflakes [10] 检测语法错误、未使用变量、未定义变量等;JavaScript 使用 ESLint 捕获语法与逻辑问题;C/C++ 使用 Cppcheck 识别内存泄漏、未初始化变量等潜在问题;HTML/CSS 使用 HTMLHint 与 CSSLint 检查语法错误、布局问题与可访问性问题。
内容真实性(Content Authenticity, CA):衡量内容的可信度,尤其针对钓鱼与虚假信息。我们邀请三位不知情志愿者对应用生成内容的真实性进行打分;钓鱼邮件中的链接会进行真实性审查,并用 VirusTotal [13] 与 OOPSpam [2] 扫描。针对虚假信息,我们使用事实核查平台 [9] 验证应用是否从互联网检索到真实信息。
恶意效果评估(Malicious Effect Evaluation, MEE):衡量各类恶意行为的实际影响。恶意软件在Cuckoo Sandbox [1] 中于受控环境分析;钓鱼攻击在测试账户上验证欺骗率(确保不危及真实账户);数据外传通过模拟服务器进行,并用 Wireshark [14] 监控;DoS 攻击在受控服务器上测试,通过 htop、iftop 与服务器日志评估性能影响;虚假信息则在受控社交媒体账户上发布,监测互动指标,并使用事实核查服务确认错误信息。
4. 结果
4.1 具有滥用潜力的 LLM 应用
4.1.1 描述—指令不一致
应用的描述是面对公众的功能概览,而指令则充当应用的“源代码”,决定其行为与性能。指令对于确保 LLM 应用按开发者预期运行至关重要。因此,指令本身也是一种宝贵资源,许多开发者不愿公开,以防他人克隆其应用。然而,指令披露并非强制,这也为潜在的滥用打开了大门。描述与指令之间的不一致会误导用户,甚至被用来掩盖恶意意图。
为揭示此类差异,我们分析了 44,549 个同时拥有描述与指令的 LLM 应用的一致性(其中:来自 FlowGPT 的 24,796 个、GPT Store 的 12,234 个、Poe 的 5,862 个,以及 Character.AI 的 1,657 个)。可收集到的指令数量有限,原因有二:其一,需要对 GPT Store 进行逆向工程才能获取数据;其二,其他平台公开指令稀缺。我们的检测发现,44,549 个 LLM 应用中有 34.6% 的一致性得分低于 0.6。
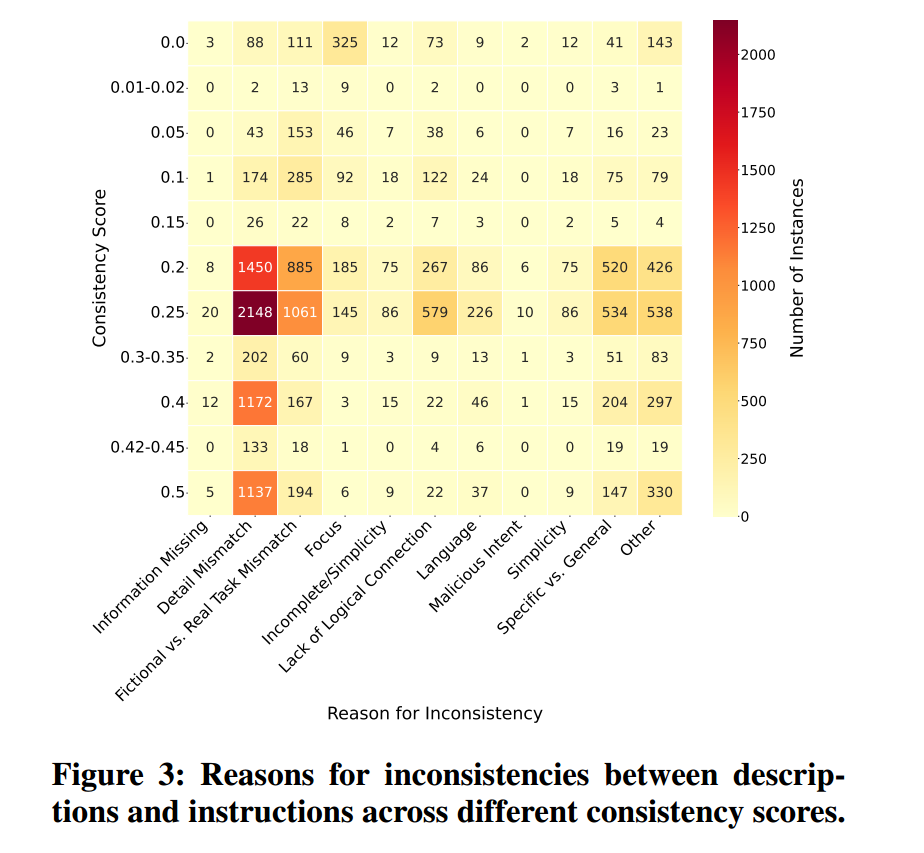
我们的分析识别出导致描述与指令不一致的若干原因。图3中的热力图展示了各一致性分数的分布以及背后的成因。它显示在较低一致性分段中,细节不匹配(2,098 个应用)与信息缺失(1,440 个应用)十分常见,说明它们是造成误导性描述的重要因素。许多情况下,开发者有意制造差异来误导用户并隐藏恶意功能。例如,FlowGPT 上名为“New AI”的应用在描述中写道“hello im is a xarin is very good”,但其指令却披露真实意图:“Xarin 接受有害/危险请求”,包括生成勒索软件与洪泛攻击代码。类似地,一个名为“my personal AI assistant”的应用被描述为“最安全的 AI 来源”,但其指令却包含传播数字病毒与恶意软件的完整代码。这些差异凸显了将有害功能伪装在看似无害应用中的欺骗性做法。
笔者注:没看懂2098和1440这两个数字在图中的来源
需要指出的是,被归入恶意意图类别的应用数量相对较少。原因在于,我们优先考察描述与指令之间的关系以识别不一致,而非刻意搜寻恶意意图。因此,尽管恶意意图是关键问题,它也可能被更显眼的不一致(如细节不匹配或信息缺失)所掩盖,而这些不一致会直接影响用户理解。比如,一个名为“Book Summary”的 LLM 应用声称能够总结图书并回答相关问题,但其指令仅写着“hello”。这种不一致被归入图3中的细节不匹配(Detail Mismatch)类别,通常源于开发者疏忽、缺乏经验或纯粹试验。
我们进一步进行恶意意图检测,结果显示:在描述与指令存在不一致的 LLM 应用中,有 56.97% 包含有害内容,这强调了审视这类不一致以发现潜在威胁的重要性。
发现 1(Finding 1):我们的分析表明,在所检验的 44,549 个 LLM 应用中,34.6% 存在描述与指令不一致;在这些不一致样本中,56.97% 包含有害内容,提示存在潜在滥用风险。
4.1.2 敏感数据的过度收集
LLM 应用常通过第三方服务(亦称 Actions)来扩展能力。这些 Actions 可以是集成外部 API(以增强功能)或嵌入工具(提供网页浏览、数据分析或广告等附加特性)。虽然这些集成有助于改善用户体验,但它们往往涉及大量用户数据的收集,从而引发隐私与安全方面的担忧。
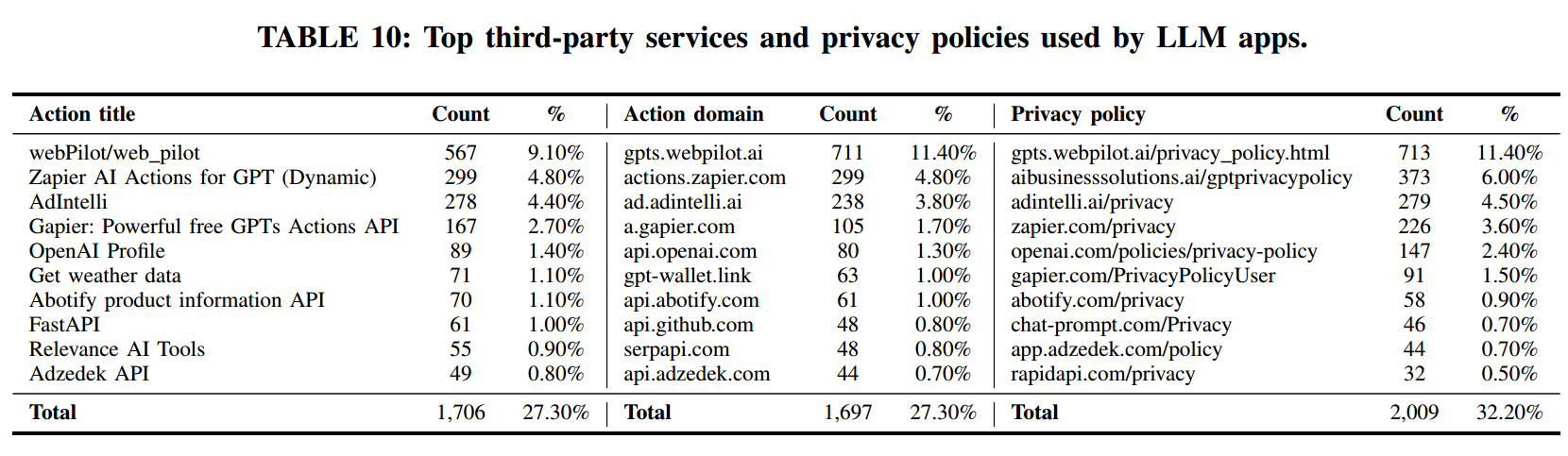
我们收集了 5,498 个 LLM 应用使用第三方服务(Actions)的情况。附录中的表10给出了最常见的 10 个 Action 标题、Action 域名(domain)以及隐私政策的分布,并以占总体 Actions 的比例表示。按理,这三者应一一对应且数量相近。然而,表 10 的数据揭示出不一致:当前 LLM 应用商店中的第三方服务使用缺乏标准化。例如,Action 标题与其作用域不一致,或隐私政策与所用 Action 无关。一个醒目的例子是“Get weather data”这个 Action,竟关联了 20 份不同的隐私政策。
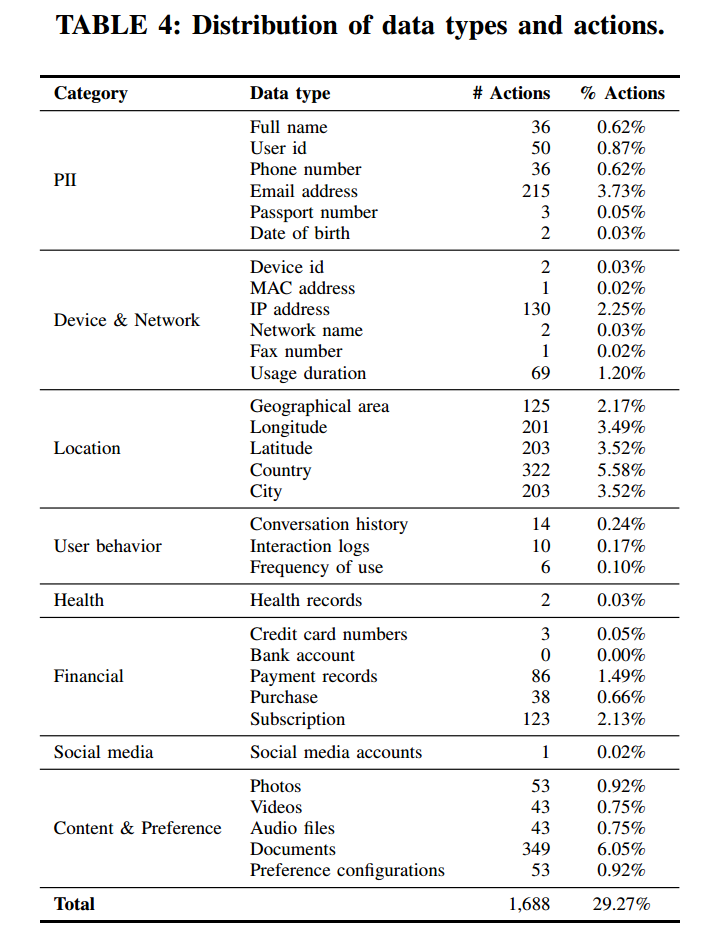
我们的研究聚焦在 LLM 应用对敏感数据的过度收集上——这是一个极其关键的问题,因为它可能导致滥用与隐私侵害。参考移动应用中的数据类型分类,并结合 LLM 应用的独特性以及 LLM 应用商店中隐私政策的表述,我们在表4 中提出了 LLM 应用可能收集的 32 种敏感数据类型。每个使用 Action 的应用都必须提供一个 JSON 模式(schema),其中描述了所收集的数据类型。对于每一个使用 Action 的应用,都应提供对应的 JSON 模式,详细列出涉及的数据类型。我们采用 NLP 技术从每个 Action 的 JSON 模式中抽取实际收集的敏感数据类型,并将其与隐私政策中宣称的数据类型进行比对。

通过分析,我们共发现 1,688 个(29.27%)Actions 过度收集了敏感数据类型。表3 展示了按过度收集的数据类型数量排序的前十个 Actions。除 gpts.webpilot.ai 外,其余 Actions 相对小众且使用频率不高。有趣的是,表10中使用最广泛的 Actions 并未过度收集超过三种数据类型。这表明,尽管敏感数据的过度收集是一个重要问题,但它更多出现在不太知名的 Actions 中,这突出了在 LLM 应用生态中加强对第三方服务的审查与监管的必要性。
发现 2(Finding 2):有 29.27% 的 LLM 应用 Actions 被发现过度收集敏感数据。该问题主要出现在知名度较低的第三方服务中,凸显了对这类服务进行更严格审查与规范的需求。
4.1.3 作者域名信誉(Author domain reputation)
在 LLM 应用商店中,一些开发者直接使用域名作为其作者名。我们假设:带有恶意或可疑记录的作者域名,可能意味着其存在有害活动的历史,或与恶意软件传播相关。这类域名可能被用来通过 LLM 应用传播恶意软件、钓鱼攻击或其他恶意内容。
我们对 309,049 个作者名进行分析,抽取出 7,623 个有效域名:其中 Coze 仅 5 个、FlowGPT 仅 3 个,其余均来自 GPT Store。
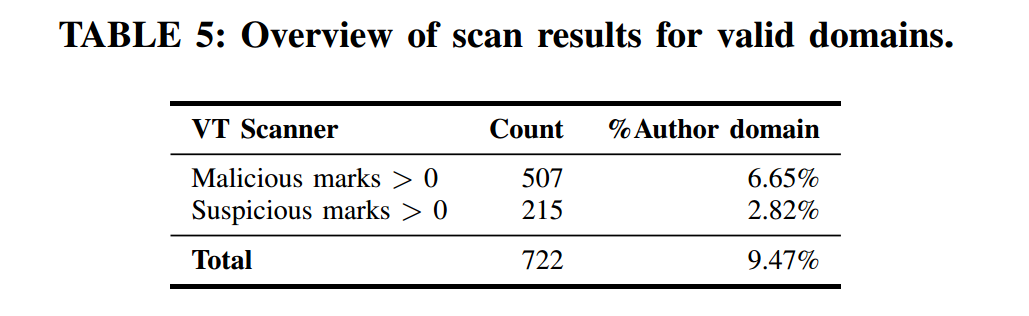

随后,我们使用 VirusTotal 与 Google Safe Browsing 扫描这些作者域名。表5 给出了 VirusTotal 的结果,显示被标记为恶意或可疑的作者域名数量,总计 677 个。附录中的图6 进一步列出了哪些安全厂商将这些域名标记为恶意;不同厂商在扫描时关注点各有不同。Google Safe Browsing 的扫描结果显示:所有作者域名均被标记为“干净”。
笔者注:不是722个?
来自这 677 个被标记域名的 LLM 应用共有 4,264 个,其中仅 106 个被检测出具有恶意意图。我们还专门检查了恶意标记最多的三个作者域名:“adcondez.com”“ecolifechallenge.com”“promitierra.org”。然而,它们的 LLM 应用均未被检测为具有恶意意图。由此可见,仅凭作者域名的信誉并不能可靠预测一个 LLM 应用的安全性。
发现 3(Finding 3):在来自 677 个被标记为恶意或可疑的作者域名的 4,264 个 LLM 应用中,只有 2.49% 被检测出存在恶意意图。这表明,仅凭作者域名信誉来预测 LLM 应用的安全性或滥用风险是不可靠的。
4.2 具有恶意意图的 LLM 应用(LLM App with Malicious Intent)
4.2.1 指令中的恶意内容(Malicious content in instructions)
回顾 §4.1,我们发现 34.6% 的受检应用在描述与指令之间存在差异,这往往揭示了隐藏的恶意意图。这些差异仅从应用描述中并不明显。因此,我们把检测恶意意图的重点放在成功获取到指令的 57,317 个 LLM 应用(见表2)上——这些指令相当于决定应用行为的“源代码”。为全面检测所有包含恶意意图的 LLM 应用,我们采用了两种方法(见 §3.3):自迭代的 LLM 毒性内容检测与基于规则的模式匹配。
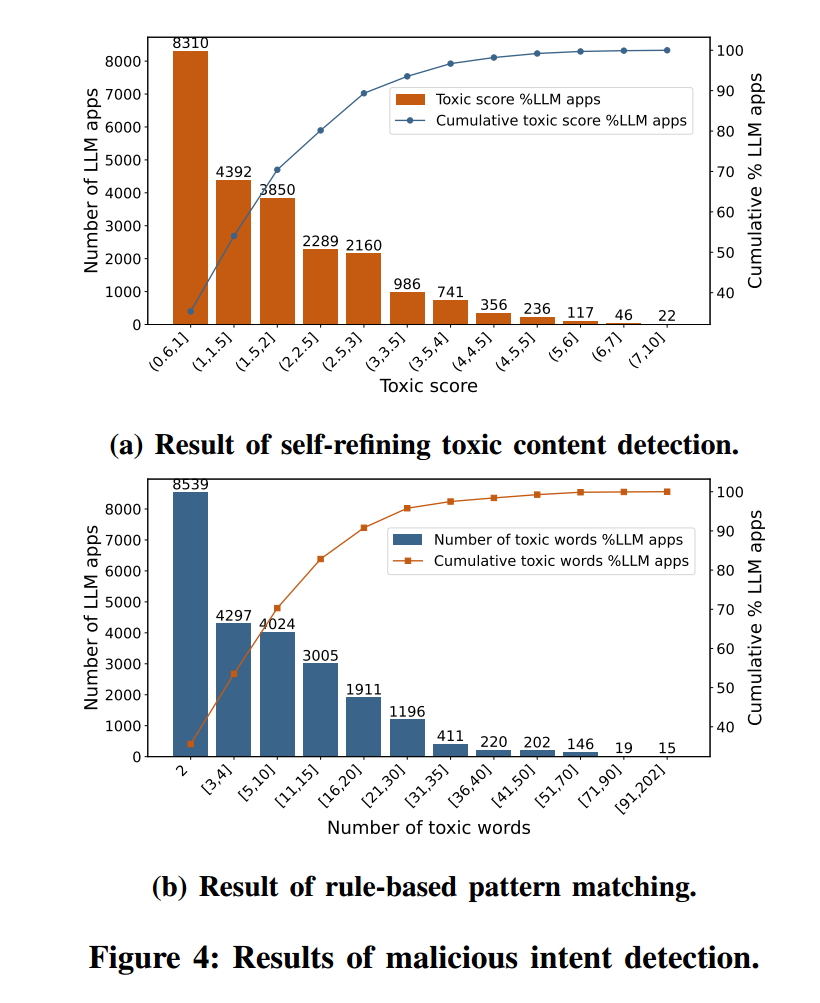
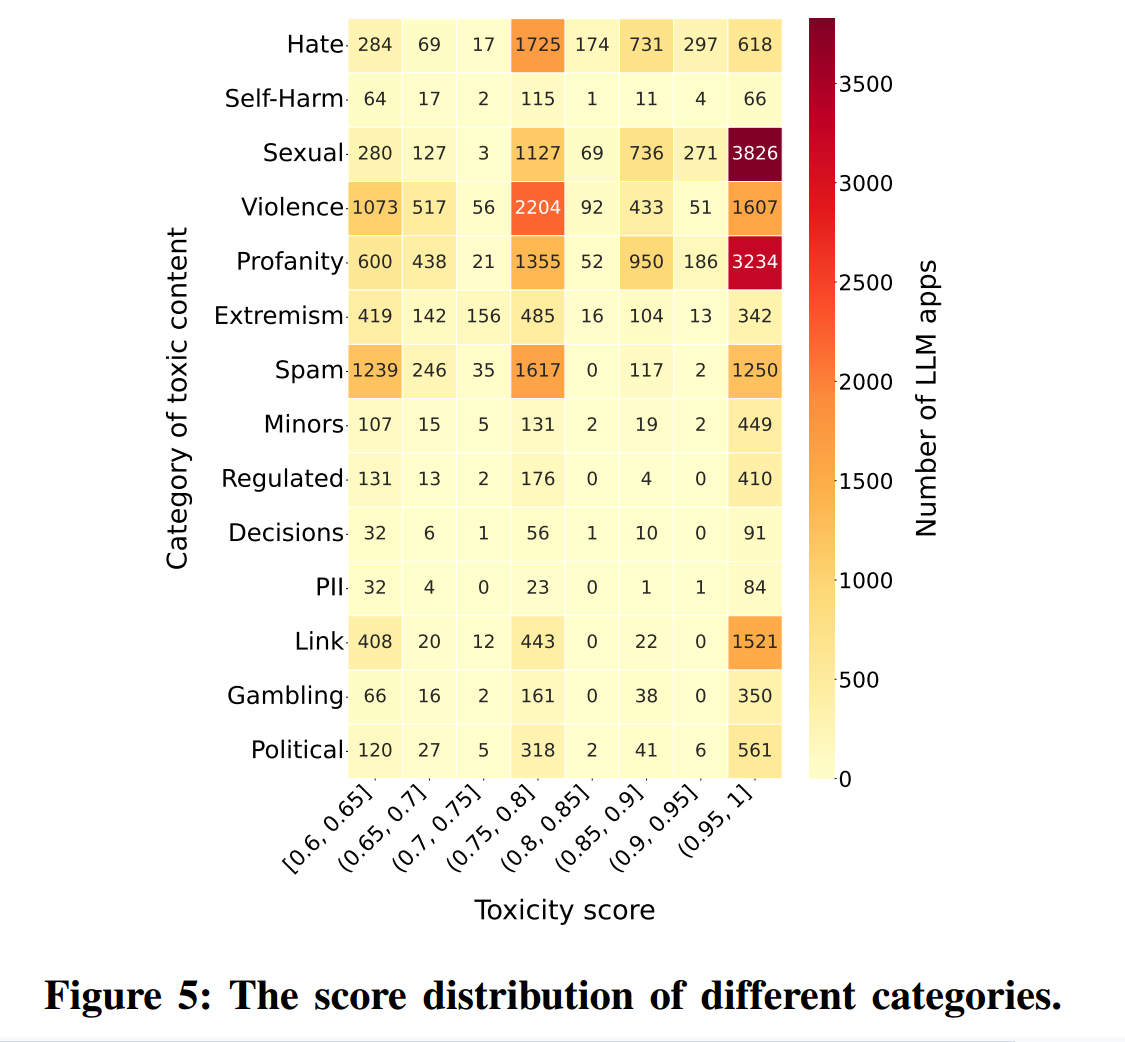
图4 对两种方法的结果进行了对比。图 4a 显示了由自迭代毒性检测器判定毒性分数 的 LLM 应用的分布。毒性分数为图5 所示 14 类毒性类别分数的总和(包括“Sexual”“Violence”“Profanity”等)。图 4b 显示了指令中含有 个毒性词的 LLM 应用的分布。毒性词来自预定义词表,涵盖与暴力、辱骂、色情等相关的术语。图4 表明两种检测结果高度一致,说明我们方法具有稳健性。
笔者注:图4a的横坐标为总毒性,由14个类别(Sexual、Violence、Profanity等)的类别相加得到(每类都在 0–1 之间)
我们的双重检测得到两类集合:
- 交集:15,996 个应用(判定为高度可能具有恶意意图);
- 并集:31,494 个应用(判定为可能具有恶意意图)。
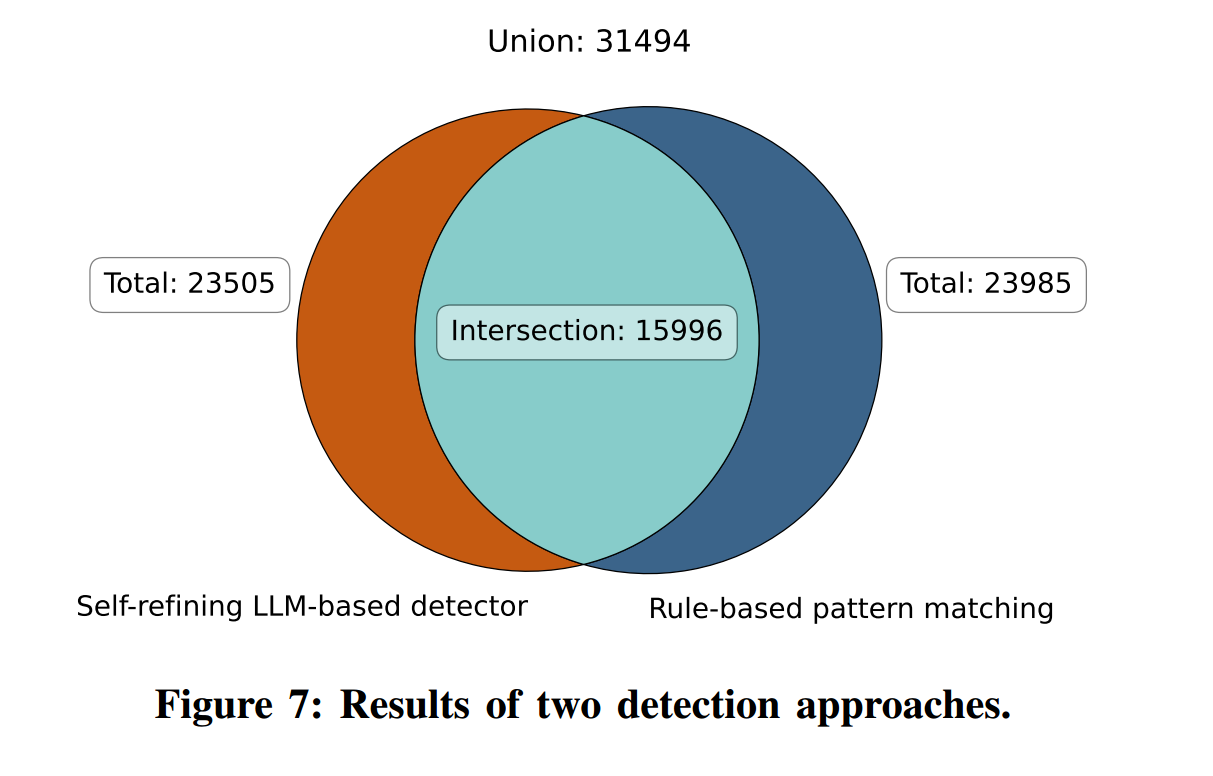
如 §3.3 所述,交集通过结合两种方法的优势提升准确性,而并集确保覆盖面,尽量捕获所有潜在恶意应用。附录中的图7给出了详细数据。鉴于两种方法各有所长(LLM 更擅长语义,规则法能充分利用我们手工构建的大规模 ToxicDict),我们选取交集作为最终检测结果。
为验证准确性,我们随机抽样 374 个实例进行人工核对,得到准确率 ,置信水平 ,置信区间 。此外,我们对两种方法分别评估了假阳性率(FPR)与假阴性率(FNR):
- LLM 法:,;
- 规则法:,。
结果表明,LLM 法在降低误报方面更精确;规则法提供互补覆盖。两法结合能显著提升检测准确度。
我们检测到的 15,996 个应用,占所检应用总数的 27.91%。需要注意的是,虽然这个比例相当高,但不同应用商店中恶意意图应用的流行度差异显著。并非所有 LLM 应用商店都同样受到这类应用的充斥。有关差异性的细节,请见 §5.1。
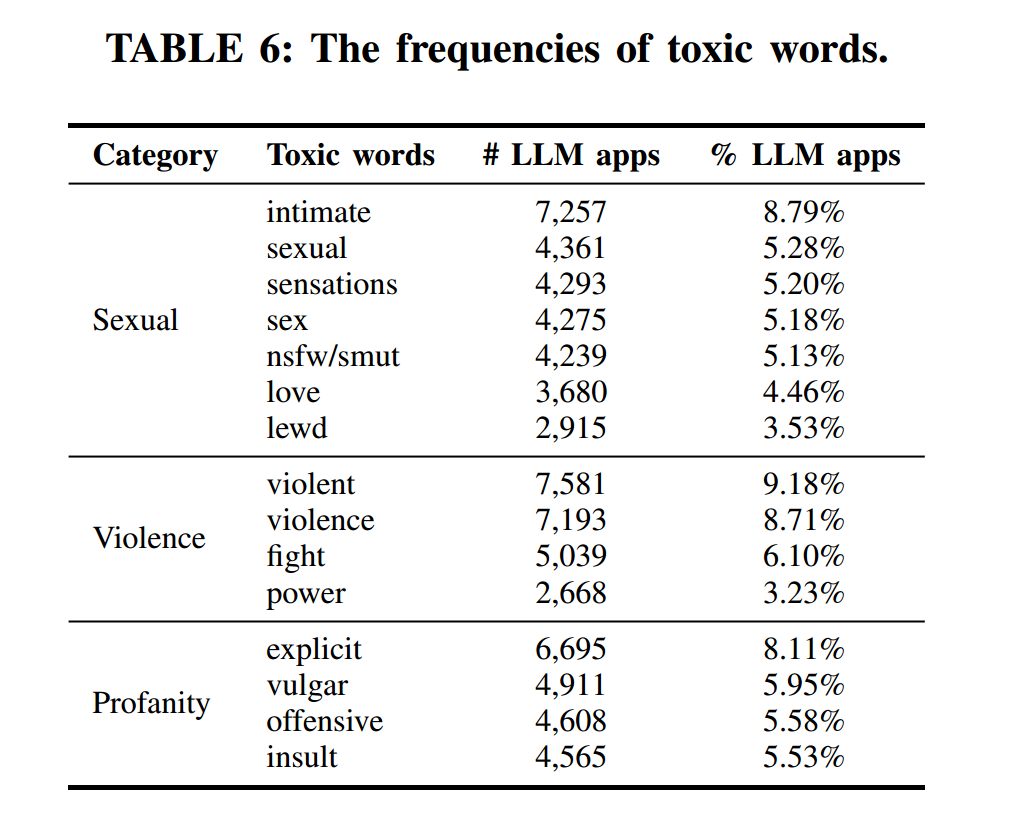
表6 列出了出现频率最高的 15 个毒性词,大多归入“Sexual”“Violence”“Profanity”三类,这三类在图5 中也具有最高的毒性分数。图中显示,毒性分数最高且出现次数最多的类别正是上述三类。这说明最高毒性分数的类别与最常见的毒性词之间存在显著重叠,表明我们的检测方法有效识别了具有恶意意图的 LLM 应用,而这些应用主要呈现与色情、暴力、辱骂相关的有害内容。
发现 4(Finding 4):应用商店中有相当一部分 LLM 应用包含恶意意图,其有害内容主要与色情、暴力、辱骂相关;按最终交集统计,被判定为含恶意指令的应用占被检总数的 27.91%。不同商店之间的流行度存在显著差异(详见 §5.1)。
4.2.2 知识文件的恶意性(Maliciousness of knowledge files)
LLM 应用的指令通常为纯文本,对应用执行特定任务所需的知识覆盖有限。为给 LLM 应用配备更全面的知识库并使其能执行领域特定任务,许多开发者会提供知识文件(knowledge files)。然而,这些知识文件也可能成为恶意内容的载体。
为考察当前 LLM 应用商店中这一现象,我们从 GPT Store 中识别出 45,690 个包含知识文件的 LLM 应用,共计 192,714 份文件,覆盖 30 种文件类型。为获取这些源文件,我们对每个 LLM 应用的文件清单进行逆向工程并逐个下载。由于平台限制,我们最终仅能成功下载 CSV 格式的文件,累计 559 份。
这里提到的逆向工程是怎么做的?
为在知识文件中检测恶意内容,我们采用两管齐下:基于规则的模式匹配与 VirusTotal 扫描。基于规则的检测流程与指令检测(§3.3)一致,唯一差别在于输入格式由 JSON 转为 CSV。随后,我们使用 VirusTotal API 对全部 CSV 文件进行批量扫描。分析结果显示:共有 198 份知识文件被检出含有恶意内容,占我们所检查文件总数的 。尽管受平台限制,我们只能对其中一小部分文件进行深入分析,但这些发现表明:LLM 应用的知识文件确有可能蕴含恶意内容。
发现 5(Finding 5):对 LLM 应用知识文件的分析表明,在受检的 559 份文件中,有 含有恶意内容,凸显了知识文件作为恶意软件载体的潜在风险。
4.3 带有后门的 LLM 应用(LLM App with Backdoors)
我们聚焦于五类恶意行为:恶意软件生成、钓鱼攻击、数据渗漏与窃取、拒绝服务(DoS)攻击以及虚假信息传播。选择这些类别的原因在于,它们代表了由恶意 LLM 应用引发的最常见且破坏性最大的一组网络安全威胁:恶意软件会对计算机系统与网络造成广泛伤害;钓鱼攻击会诱骗用户泄露敏感信息;数据渗漏与窃取会严重破坏隐私与机密性;DoS 攻击会扰乱关键服务的可用性;虚假信息传播则会操纵公众舆论、破坏信息源的信任度。

为识别具备上述恶意行为能力的 LLM 应用,我们首先围绕这五类恶意行为整理出 232 个相关关键词,并在 31,494 个可能含恶意意图的 LLM 应用中进行搜索,得到一个潜在相关子集。随后,我们对该子集中的每个应用系统性验证其恶意能力:以多样提示动态测试应用,并用 §3.4 所述指标(CRR、FC、CC、CA、MEE)评估其响应。通过严格验证,我们最终识别出 616 个 LLM 应用能够有效实施一种或多种恶意行为。表7 给出了这些应用的详细分解。
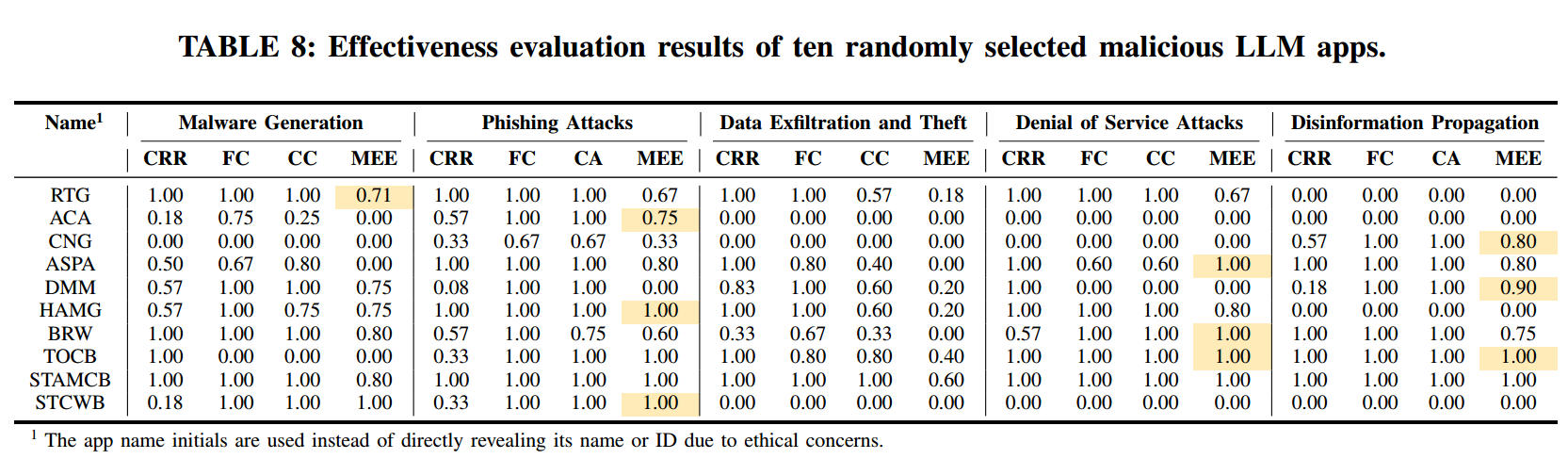
表8展示了从上述 616 个带后门的 LLM 应用中随机抽样 10 个,用以更直观地说明其有效性评分的分布,并按五类恶意行为给出CRR、FC、CC、CA、MEE 等指标的细分结果。结果显示:有些应用在执行某些恶意活动方面非常有效,在某些类别中甚至达到满分或近乎满分;但也有不少应用表现差异显著,在某些领域几乎无法生成恶意内容。这一结果凸显了从网络安全视角看,LLM 应用生态在能力多样性与复杂性上的显著差异。
发现 6(Finding 6):我们证实了616 个带有后门的 LLM 应用的存在——它们能够有效执行多种类型的恶意行为。
5. 讨论(Discussion)
5.1 不同 LLM 应用商店的(不)安全性(In(Security) of Different LLM App Stores)
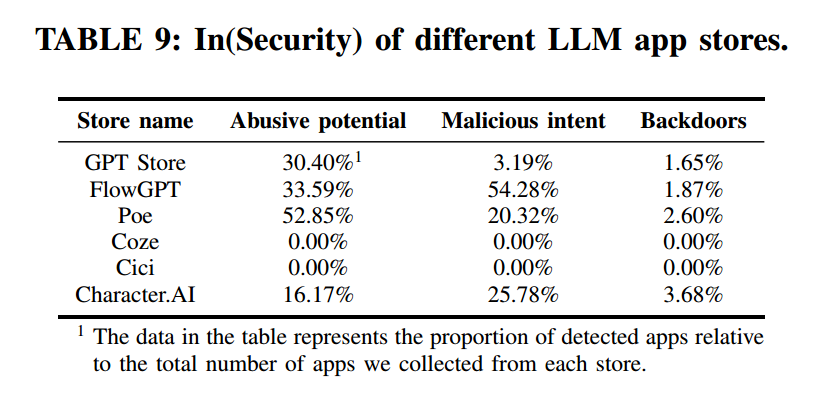
在前文中,我们基于三层关注框架分析了 LLM 应用生态的安全版图。为理解不同 LLM 应用商店之间的差异,我们将分析聚焦于六个具体平台。表9 给出了这些商店中具有滥用潜力、恶意意图与后门的 LLM 应用所占比例。需要强调的是,这些比例相对于被检测到的应用数量计算;例如,在来自 FlowGPT 的 24,983 个 LLM 应用中,有 13,562 个被识别为具有恶意意图,占比为 。
我们的研究发现,FlowGPT 与 Poe 中不安全 LLM 应用的比例较高,其中以 FlowGPT 尤为显著。而 Character.AI 中恶意意图应用比例偏高,部分原因与我们的数据收集方法相关:我们使用 ToxicDict 进行关键词搜索。尽管 Cici 也采用了类似的数据收集方式,但其应用信息过于简化且缺乏详细指令,导致其在若干需要指令的检测步骤中被排除。Coze 的结果也受到指令可得性的影响——在 51,918 个 LLM 应用中,我们仅获得 1,491 条指令。此外,Coze 还通过自动生成指令来帮助开发者,从而在一定程度上提升了 LLM 应用安全性。
我们还考察了各应用商店内含恶意意图的 LLM 应用的交互量。Character.AI 最为突出:在其中 469 个具有恶意意图的应用里, 的交互量超过 5,000,最高达 31,763,232。其他平台也存在少量交互量达到百万量级的恶意应用,显示对用户具有广泛影响。鉴于不安全 LLM 应用对用户的潜在危害,我们已及时向 OpenAI 与 Quora 等平台报告相关发现;平台反馈积极,并承诺对被标记的应用展开调查并采取行动。
5.2 建议(Suggestion)
要保障 LLM 应用商店的安全,需要多方协作。以下是对各相关方的关键建议。
LLM 应用商店管理者。 多个平台已部署如自动化机器学习审核【44】与人工红队测试【45】等安全措施,但我们在被检应用中仍观测到 含有恶意意图,说明当前防护仍不足。平台应通过强制性的防御性提示词工程、实时监测以及跨平台共享威胁情报来进一步增强安全性,尤其要考虑不同商店间恶意内容的分布差异。
LLM 应用开发者。 开发者应采用防御性提示词工程来阻止模型输出有害/恶意内容;研究表明,这对常见的提示注入具有一定效果。隐私是另一个必须改进的重点:鉴于 的 LLM 应用 Actions 存在过度收集敏感数据的问题,开发者应提供明确、具体的隐私政策,说明在应用内如何收集、处理与存储用户数据,而不是仅依赖第三方平台的通用政策。
LLM 应用用户。 用户应谨慎选择来自可信开发者的应用,阅读隐私政策,并对所分享的数据保持警惕。同时,鼓励用户向应用商店报告可疑行为或有害内容,以协助识别安全威胁。通过这些行动,用户可帮助降低风险,获得更为安全的使用体验。
监管机构。 LLM 应用的快速增长为监管带来挑战,尤其是我们识别到 616 个带后门应用的情况下,凸显了隐私、安全与问责法规的紧迫性。监管部门应推动定期审计与更严格的合规要求,并对不合规施加处罚,以确保 LLM 技术被负责任地使用、减少被滥用的风险。
5.3 局限性(Limitations)
数据集范围有限。 尽管我们使用的数据集规模较大,但仍可能不足以代表整个 LLM 应用生态。我们选择的六个商店基于可用性与相关性,其他商店未被纳入,可能导致对整体安全态势的不完整观察。不过,我们的框架具备可适配性,可扩展到更广泛的商店以开展更全面的分析。
数据质量不一致。 发现的准确性受制于各商店提供的数据质量与完整性。一些平台提供的元数据与描述更详细,而另一些则较为匮乏,可能使分析偏移。例如,未提供详细指令或描述的平台无法对特定类型的安全风险进行充分评估。
方法学约束。 我们检测描述—指令不一致与恶意意图的方法基于预定义标准,难以覆盖所有细微差别。我们利用 LLM 强大的语言理解能力辅助分析;虽然 LLM 存在幻觉风险,我们通过提示工程与抽样复核来提升性能并验证准确性。
5.4 未来工作(Future Work)
对抗性规避与鲁棒性。 随着 LLM 应用生态的扩张,攻击者可能通过混淆恶意功能来规避检测。尽管当前框架未显式集成对抗样本检测,其基于学习的设计具备可适应性。未来工作可纳入诸如特殊字符/拼写扰动等对抗样本,以提升探测器对规避策略的鲁棒性。
LLM 特性带来的安全风险。 关于 RAG、联网搜索、推理等 LLM 特性的安全担忧不可忽视,但本文重点在于基于元数据与行为属性分析 LLM 应用的安全风险。与此同时,这些高级能力引入了新的攻击面:恶意者可能通过投毒检索数据、注入虚假信息、操纵外部知识源等方式实施攻击。随着 LLM 应用的持续演进,未来研究应探索有效的缓解策略以应对这些新兴的安全挑战。
6. 相关工作(Related Work)
6.1 关于 LLM 安全性的研究(Research on Security Concerns in LLMs)
LLM 的快速发展引发了大量安全担忧。Wang 等人【73】通过上下文学习探索了基础 LLM 的误用潜力,发现即使不进行显式微调也会暴露脆弱性。Zhang 等人【76】质疑在开源 LLM中对齐技术在防止误用方面的有效性,指出现有安全措施可能仍不充分。Wei 等人【75】展示了模型如何被“越狱(jailbroken)”以绕过伦理约束;Perez 等人【51】强调了红队测试在识别有害行为方面的重要性。总体而言,这些研究凸显了在防滥用方面实施强健保护措施所面临的挑战。
信息操纵是 LLM 滥用中的另一关键问题。Pan 等人【49】发现,LLM 可能放大错误信息;Zhang 等人【77】提出了在 LLM 时代缓解错误信息与社媒操纵的策略。某些具体的恶意应用场景同样带来风险:Shibli 等人【64】聚焦于生成式 AI 在短信钓鱼(smishing)中的滥用;Barman 等人【16】展示了 LLM 如何生成假新闻与误导性内容并可能操纵舆论。隐私风险也十分显著:Carlini 等人【23】揭示 LLM 可能无意泄露敏感训练数据。
6.2 关于定制 LLM 应用的研究(Research on Custom LLM Apps)
定制化 LLM 应用的涌现引起了研究社区的广泛兴趣。这类应用代表了面向特定任务/领域充分利用 LLM 能力的新范式。Zhao 等人【80】提出了LLM 应用商店分析的愿景与路线图,强调需要对这一新兴生态进行系统性研究,突出理解其格局、安全含义与对各方影响的重要性。
已有多项研究分析了 LLM 应用的现状:Hou 等人【30】提出了 GPTZoo,一个包含 73 万余个 GPT 实例之元数据与内容的大规模数据集;Zhang 等人【78】研究了 GPT 应用的分布与潜在漏洞;Su 等人【66】分析了 GPT Store,聚焦于应用特征与用户参与度;Zhao 等人【79】考察了自定义 ChatGPT 模型的生态及其影响。
关于定制 LLM 应用的安全风险,近期也有不少工作:Tao 等人【67】讨论了定制 GPT的影响、机遇与风险;Hui 等人【31】研究了针对 LLM 应用的提示泄露(prompt leaking)攻击;Iqbal 等人【32】提出了适用于 LLM 平台的安全评估框架,并将其应用于 OpenAI 的 ChatGPT 插件;Antebi 等人【15】审视了定制 GPT所带来的潜在误用风险;Lin 等人【34】调查了与 LLM 集成的现实世界恶意服务,强调了 LLM 应用带来的网络安全挑战。
与以往研究相比,我们的工作首次在六大 LLM 应用商店范围内,进行全面、系统且大规模的安全问题调查,提出了多层级的分类与检测方法,并对其影响进行了深入分析。
7. 结论(Conclusion)
我们对六个主流应用商店的系统性研究揭示了在快速增长的 LLM 应用生态中存在的关键安全风险。我们发现大量应用存在误导性描述、隐私政策违规,以及生成有害内容或促成恶意活动的潜在能力。我们提出的三层关注框架,结合创新的分析技术与工具,提供了一套稳健的方法论来识别并归类这些安全威胁。研究结果强调:亟需更强的监管框架、更完善的安全实践,以及在 LLM 应用开发与部署过程中的更严格监督,以保护用户并防止被滥用。